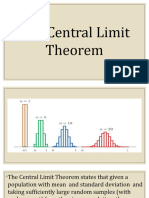
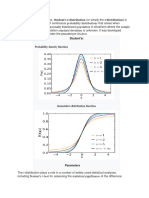
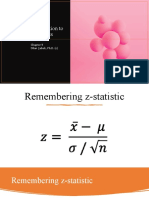You might also like
- Visual AidDocument4 pagesVisual AidsnoopierichNo ratings yet
- Central Limit Theorem T Distribution PercentileDocument11 pagesCentral Limit Theorem T Distribution PercentileMarco ZoletaNo ratings yet
- Day 13 - Intro To T StatisticDocument7 pagesDay 13 - Intro To T StatisticLianne SedurifaNo ratings yet
- T TESTDocument5 pagesT TESTMeenalochini kannanNo ratings yet
- LAS 9 Statistics and Probability - 042027Document9 pagesLAS 9 Statistics and Probability - 042027Shane R. FelominoNo ratings yet
- Introduction To T-StatisticsDocument20 pagesIntroduction To T-StatisticsAyşe KayaNo ratings yet
- Chapter 9: Introduction To The T StatisticDocument42 pagesChapter 9: Introduction To The T StatisticRhaine EstebanNo ratings yet
- Standard Error: Sampling DistributionDocument5 pagesStandard Error: Sampling DistributionErica YamashitaNo ratings yet
- Measures of Spread-2023Document25 pagesMeasures of Spread-2023AmielRayyanB.Badrudin 309No ratings yet
- Descriptive StatisticDocument37 pagesDescriptive StatisticFahad MushtaqNo ratings yet
- Assignment 4Document18 pagesAssignment 4ManyaNo ratings yet
- T DistributionDocument26 pagesT DistributionJDR JDR0% (1)
- Bernard F Dela Vega PH 1-1Document5 pagesBernard F Dela Vega PH 1-1BernardFranciscoDelaVegaNo ratings yet
- Student T-DistributionDocument2 pagesStudent T-DistributionRao Abdul Wahab AkramNo ratings yet
- Sampling DistDocument40 pagesSampling DistSanket SharmaNo ratings yet
- Introduction To The T-Statistic: PSY295 Spring 2003 SummerfeltDocument19 pagesIntroduction To The T-Statistic: PSY295 Spring 2003 SummerfeltEddy MwachenjeNo ratings yet
- Assumptions and Properties of Z and T DistributionDocument4 pagesAssumptions and Properties of Z and T DistributionAdnan AkramNo ratings yet
- Independent T Test..FinalDocument8 pagesIndependent T Test..FinalDipayan Bhattacharya 478No ratings yet
- Ch3 Numerically Summarizing DataDocument35 pagesCh3 Numerically Summarizing DataGrissel HernandezLaraNo ratings yet
- Data ManagementDocument44 pagesData ManagementStephen Sumipo BastatasNo ratings yet
- Introduction To EstimationDocument9 pagesIntroduction To EstimationRegina Raymundo AlbayNo ratings yet
- T F DistributionDocument9 pagesT F Distributionkuchipudi durga pravallikaNo ratings yet
- T DistibutionDocument25 pagesT DistibutionFritz AstilloNo ratings yet
- Differences Between Z and T TestDocument6 pagesDifferences Between Z and T Testpriya sundaramNo ratings yet
- Illustrating The T DistributionDocument18 pagesIllustrating The T DistributionAshieeNo ratings yet
- Week 7: The T Distribution, Confidence Intervals and TestsDocument51 pagesWeek 7: The T Distribution, Confidence Intervals and TestsHussein RazaqNo ratings yet
- Unit-Iv 1. Testing of HypothesisDocument28 pagesUnit-Iv 1. Testing of Hypothesismalleda haneeshNo ratings yet
- Week 017 Measures of Central TendencyDocument15 pagesWeek 017 Measures of Central TendencyIrene PayadNo ratings yet
- Confidence Intervals, Student - S T Distribution, Margin of ErrorDocument11 pagesConfidence Intervals, Student - S T Distribution, Margin of ErrorMukund TiwariNo ratings yet
- T Distribution For MeansDocument21 pagesT Distribution For MeansldlewisNo ratings yet
- Statistic ReportDocument12 pagesStatistic ReportCyra BantilloNo ratings yet
- Z and T TestDocument7 pagesZ and T TestshraddhaNo ratings yet
- Estimation of ParametersDocument87 pagesEstimation of ParametersAlfredNo ratings yet
- Statistics SuggestionsDocument74 pagesStatistics SuggestionsDr. Mahbub Alam MahfuzNo ratings yet
- Normal Distribution1Document8 pagesNormal Distribution1ely san100% (1)
- Lecture 3 Notes - PSYC 204Document8 pagesLecture 3 Notes - PSYC 204SerenaNo ratings yet
- Stat IticsDocument20 pagesStat IticsHoney C. PerezNo ratings yet
- Inference For Numerical Data - Stats 250Document18 pagesInference For Numerical Data - Stats 250Oliver BarrNo ratings yet
- To Statistics: Semester-V Fall 2021 Ms. Fatima Salman Psychology Department Lahore Garrison UniversityDocument36 pagesTo Statistics: Semester-V Fall 2021 Ms. Fatima Salman Psychology Department Lahore Garrison UniversityZeeshan AkhtarNo ratings yet
- Chapter 8 - Sampling DistributionDocument34 pagesChapter 8 - Sampling DistributionMir Md. Mofachel HossainNo ratings yet
- 3 - Data Analysis - Tests of DifferencesDocument50 pages3 - Data Analysis - Tests of Differencesmnrk 1997No ratings yet
- StaticsticsDocument2 pagesStaticsticsCaesar GarsiyaNo ratings yet
- Costructs T Distribution (Dianne)Document9 pagesCostructs T Distribution (Dianne)Dianne RuizNo ratings yet
- Glossary of TermsDocument7 pagesGlossary of TermsKathzkaMaeAgcaoiliNo ratings yet
- Statistics: Organize UnderstandDocument9 pagesStatistics: Organize UnderstandJaved KaloiNo ratings yet
- Statistics NotesDocument15 pagesStatistics NotesBalasubrahmanya K. R.No ratings yet
- T - TestDocument45 pagesT - TestShiela May BoaNo ratings yet
- 1 BiostatisticsDocument16 pages1 BiostatisticsireneNo ratings yet
- Z DistributionDocument2 pagesZ DistributionAamir MukhtarNo ratings yet
- Confidence IntervalDocument19 pagesConfidence IntervalAjinkya Adhikari100% (1)
- Normal DistributionDocument13 pagesNormal DistributionMarvin Dionel BathanNo ratings yet
- Reviewer in Statistics: StatisticDocument4 pagesReviewer in Statistics: StatisticMirafelNo ratings yet
- Confidence Intervals PDFDocument5 pagesConfidence Intervals PDFwolfretonmathsNo ratings yet
- UnitDocument119 pagesUnitKundan VanamaNo ratings yet
- ADDB - Week 2Document46 pagesADDB - Week 2Little ANo ratings yet
- 10.2 Power PointDocument23 pages10.2 Power PointkrothrocNo ratings yet
- Z-Test and T-TestDocument6 pagesZ-Test and T-Test03217925346No ratings yet
- When Do You Use The T DistributionDocument4 pagesWhen Do You Use The T DistributionDerek DamNo ratings yet
- Standard Deviation and Its ApplicationsDocument8 pagesStandard Deviation and Its Applicationsanon_882394540100% (1)