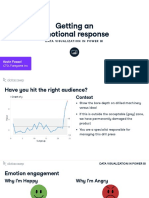
You might also like
- Premium Calculation and Insurance Pricing: Roger J.A. Laeven Marc J. GoovaertsDocument22 pagesPremium Calculation and Insurance Pricing: Roger J.A. Laeven Marc J. GoovaertsDionisio UssacaNo ratings yet
- XL ReinstatementsRDocument20 pagesXL ReinstatementsRdavid AbotsitseNo ratings yet
- The Individual Risk SlideDocument26 pagesThe Individual Risk SlideDionisio UssacaNo ratings yet
- XX Ws 093513 (Not Mine)Document20 pagesXX Ws 093513 (Not Mine)Geoffrey SmithNo ratings yet
- Attitude Towards RiskDocument11 pagesAttitude Towards RiskOrestis :. KonstantinidisNo ratings yet
- Department of Actuarial Mathematics and Statistics, Heriot-Watt University, Edinburgh EHI4 4AS, United KingdomDocument20 pagesDepartment of Actuarial Mathematics and Statistics, Heriot-Watt University, Edinburgh EHI4 4AS, United KingdomhadihadihaNo ratings yet
- The Credibility Premiums for Exponential PrincipleDocument12 pagesThe Credibility Premiums for Exponential PrincipleAliya 02No ratings yet
- Aggregate Loss Models SummaryDocument22 pagesAggregate Loss Models SummaryDionisio UssacaNo ratings yet
- F (X) - P (Y) y (X), y (X), P (Y)Document7 pagesF (X) - P (Y) y (X), y (X), P (Y)TomJerryNo ratings yet
- ACTL3162 General Insurance Techniques: References: MW Ch1Document15 pagesACTL3162 General Insurance Techniques: References: MW Ch1kenny013No ratings yet
- Actuarial Valuation LifeDocument22 pagesActuarial Valuation Lifenitin_007100% (1)
- Optimal Insurance Design Under VaR FrameworkDocument19 pagesOptimal Insurance Design Under VaR FrameworkRadia AbbasNo ratings yet
- General Theory Economics of Risk and Time: Toulouse School of Economics Catherine Bobtcheff Catherine - Bobtcheff@tse-Fr - EuDocument49 pagesGeneral Theory Economics of Risk and Time: Toulouse School of Economics Catherine Bobtcheff Catherine - Bobtcheff@tse-Fr - EuTrúc LinhNo ratings yet
- Expected Utility Theory: XX X X P P PDocument6 pagesExpected Utility Theory: XX X X P P PgopshalNo ratings yet
- The Moral Hazard Model: The Discrete and The Continuous CasesDocument6 pagesThe Moral Hazard Model: The Discrete and The Continuous CasesJournal of ComputingNo ratings yet
- Optimal Portfolios and The Mutual Fund Separation Theorem: I 1 2 N IjDocument3 pagesOptimal Portfolios and The Mutual Fund Separation Theorem: I 1 2 N IjMachaca Alvaro MamaniNo ratings yet
- Problem Set 2 - Study Group BDocument15 pagesProblem Set 2 - Study Group B265313No ratings yet
- Generalized Initial Premium in XL Reinsurance With ReinstatementsDocument11 pagesGeneralized Initial Premium in XL Reinsurance With Reinstatementshalim24No ratings yet
- Correlation, Tail Dependence and Diversification: Dietmar PfeiferDocument20 pagesCorrelation, Tail Dependence and Diversification: Dietmar PfeiferMahfudhotinNo ratings yet
- Basic Utility Theory For Portfolio SelectionDocument25 pagesBasic Utility Theory For Portfolio SelectionTecwyn LimNo ratings yet
- Definition and ApplicationsDocument5 pagesDefinition and ApplicationsAnirban BardhanNo ratings yet
- Chapter IDocument9 pagesChapter ISharon ANo ratings yet
- GMM by WooldridgeDocument15 pagesGMM by WooldridgemeqdesNo ratings yet
- Homework 3Document3 pagesHomework 3KeithNo ratings yet
- Computational Methods For Compound SumsDocument29 pagesComputational Methods For Compound Sumsraghavo100% (1)
- Lars Stole Contract TheoryDocument85 pagesLars Stole Contract TheoryJay KathavateNo ratings yet
- Ruin TheoryDocument82 pagesRuin TheoryParita PanchalNo ratings yet
- 20 Cost Sensitive LearningDocument6 pages20 Cost Sensitive LearningvikasbhowateNo ratings yet
- Loss Aversion - Sridhar DA1Document2 pagesLoss Aversion - Sridhar DA1shri shubhamNo ratings yet
- Expected Utility TheoryDocument10 pagesExpected Utility TheorygopshalNo ratings yet
- Solutions To Modern Actuarial Risk TheoryDocument9 pagesSolutions To Modern Actuarial Risk Theoryrrmedinajr23% (13)
- Amd 03Document20 pagesAmd 03MRINAL GAUTAMNo ratings yet
- Zimch: Hans BuhlmannDocument14 pagesZimch: Hans BuhlmannelviapereiraNo ratings yet
- Expected Utilfgity TheoryDocument11 pagesExpected Utilfgity TheorySahil GuptaNo ratings yet
- Unit 6Document15 pagesUnit 6Muhammed Mikhdad K G 21177No ratings yet
- Chap 4 PDFDocument33 pagesChap 4 PDFbaha146No ratings yet
- Stat 230 Problem Set 2Document1 pageStat 230 Problem Set 2N squaredNo ratings yet
- The premium insurance from portfolio theory viewDocument8 pagesThe premium insurance from portfolio theory viewIstrate Adriana ElenaNo ratings yet
- Lect1 12Document32 pagesLect1 12Ankit SaxenaNo ratings yet
- The Concept of Comonotonicity in Actuarial Science and Finance: ApplicationsDocument31 pagesThe Concept of Comonotonicity in Actuarial Science and Finance: ApplicationsgzipNo ratings yet
- Premium CalculationDocument30 pagesPremium CalculationMahbubur RahmanNo ratings yet
- Guesstimation: A New Justification of The Geometric Mean HeuristicDocument7 pagesGuesstimation: A New Justification of The Geometric Mean HeuristicPiyushGargNo ratings yet
- Estimating The Tais of Loss Severity Using Extreme ValuesDocument22 pagesEstimating The Tais of Loss Severity Using Extreme ValuesLapaPereiraNo ratings yet
- Jep 27 1 173Document44 pagesJep 27 1 173silv_phNo ratings yet
- Barberis 2013 Thirty Years of Prospect Theory in Economics A Review and AssessmentDocument24 pagesBarberis 2013 Thirty Years of Prospect Theory in Economics A Review and AssessmentKostas TampakisNo ratings yet
- Pricing Catastrophe Reinsurance With Reinstatement Provisions Using A Catastrophe ModelDocument20 pagesPricing Catastrophe Reinsurance With Reinstatement Provisions Using A Catastrophe ModelAnurag PuniaNo ratings yet
- Markowitz Mean-Variance Portfolio TheoryDocument17 pagesMarkowitz Mean-Variance Portfolio Theorymimo1911No ratings yet
- Extracting Stochastic Diseconomies of Scale and Environmental Harm from Nonlinear ResponseDocument5 pagesExtracting Stochastic Diseconomies of Scale and Environmental Harm from Nonlinear ResponsebobmezzNo ratings yet
- IEOR E4731: Credit Risk and Credit Derivatives: Lecture 13: A General Picture of Portfolio Credit Risk ModelingDocument27 pagesIEOR E4731: Credit Risk and Credit Derivatives: Lecture 13: A General Picture of Portfolio Credit Risk ModelingJessica HendersonNo ratings yet
- Understanding Expected Utility Theory and Risk PreferencesDocument28 pagesUnderstanding Expected Utility Theory and Risk PreferencesDương DươngNo ratings yet
- ExecCourse1 9-20pdfDocument44 pagesExecCourse1 9-20pdfpetere056No ratings yet
- Utility-Based Valuation For Pricing Derivative SecuritiesDocument18 pagesUtility-Based Valuation For Pricing Derivative SecuritiesAlexis TocquevilleNo ratings yet
- Calibration of A Jump Di FussionDocument28 pagesCalibration of A Jump Di Fussionmirando93No ratings yet
- Uncertainties From LABBOOK2022Document4 pagesUncertainties From LABBOOK2022katethekat2.0No ratings yet
- Microeconomics State ContingencyDocument18 pagesMicroeconomics State ContingencyMaNo ratings yet
- Monte Carlo Methods for Dimensionality and Variance ReductionDocument19 pagesMonte Carlo Methods for Dimensionality and Variance ReductionRopan EfendiNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Chapter 4Document18 pagesChapter 4Komi David ABOTSITSENo ratings yet
- Chapter 3Document16 pagesChapter 3Komi David ABOTSITSENo ratings yet
- Chapter 2Document18 pagesChapter 2Komi David ABOTSITSENo ratings yet
- Chapter 1Document16 pagesChapter 1Komi David ABOTSITSENo ratings yet
- Chapter 2Document11 pagesChapter 2Komi David ABOTSITSENo ratings yet
- Chapter 3Document12 pagesChapter 3Komi David ABOTSITSENo ratings yet
- Chapter 1Document9 pagesChapter 1Komi David ABOTSITSENo ratings yet
- Chapter 4Document11 pagesChapter 4Komi David ABOTSITSENo ratings yet
- Chapter 1Document10 pagesChapter 1Komi David ABOTSITSENo ratings yet
- Chapter 2Document8 pagesChapter 2Komi David ABOTSITSENo ratings yet
- Chapter 2Document5 pagesChapter 2Komi David ABOTSITSENo ratings yet
- Chapter 3Document7 pagesChapter 3Komi David ABOTSITSENo ratings yet
- Chapter 3Document54 pagesChapter 3Komi David ABOTSITSENo ratings yet
- Power BI Case Study Meta Data Sheet-2Document1 pagePower BI Case Study Meta Data Sheet-2Komi David ABOTSITSENo ratings yet
- Chapter 1Document13 pagesChapter 1Komi David ABOTSITSENo ratings yet
- Chapter 2Document73 pagesChapter 2Komi David ABOTSITSENo ratings yet
- One-sample proportion tests in Python: An introduction to hypothesis testingDocument41 pagesOne-sample proportion tests in Python: An introduction to hypothesis testingKomi David ABOTSITSENo ratings yet
- Chapter 3Document15 pagesChapter 3Komi David ABOTSITSENo ratings yet
- Chapter 4Document43 pagesChapter 4Komi David ABOTSITSENo ratings yet
- Introduction To Data Visualization With Seaborn Chapter3Document32 pagesIntroduction To Data Visualization With Seaborn Chapter3FgpeqwNo ratings yet
- Chapter 1Document41 pagesChapter 1Komi David ABOTSITSENo ratings yet
- Chapter 3Document16 pagesChapter 3Komi David ABOTSITSENo ratings yet
- Chapter 1Document34 pagesChapter 1Komi David ABOTSITSENo ratings yet
- Introduction To Data Visualization With Seaborn Chapter1Document26 pagesIntroduction To Data Visualization With Seaborn Chapter1FgpeqwNo ratings yet
- Chapter 3Document7 pagesChapter 3Komi David ABOTSITSENo ratings yet
- Changing Plot Style and Color: Erin CaseDocument54 pagesChanging Plot Style and Color: Erin CaseBaldev KumarNo ratings yet
- Chapter 2Document42 pagesChapter 2Komi David ABOTSITSENo ratings yet
- Chapter 4Document15 pagesChapter 4Komi David ABOTSITSENo ratings yet
- Chapter 2Document8 pagesChapter 2Komi David ABOTSITSENo ratings yet
- Chapter 2Document10 pagesChapter 2Komi David ABOTSITSENo ratings yet