You might also like
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- Multivariate Smoothing Via The Fourier IntegralDocument58 pagesMultivariate Smoothing Via The Fourier IntegralnagatoNo ratings yet
- Hesi 13Document86 pagesHesi 13Kj DeNo ratings yet
- A Monte Carlo Algorithm For Simulating Fermions On Lefschetz ThimblesDocument16 pagesA Monte Carlo Algorithm For Simulating Fermions On Lefschetz ThimblesPaulo BedaqueNo ratings yet
- Subject Chemistry: 22: Postulates of Quantum MechanicsDocument8 pagesSubject Chemistry: 22: Postulates of Quantum MechanicsHemanginee DasNo ratings yet
- Algorithms For Multidimensional Spectral Factorization and Sum of SquaresDocument21 pagesAlgorithms For Multidimensional Spectral Factorization and Sum of SquaresPuoyaNo ratings yet
- 1-S2.0-S0898122109007263-MainDocument14 pages1-S2.0-S0898122109007263-MainThiago NobreNo ratings yet
- Numerical Solution of Volterra-Fredholm IntegralDocument16 pagesNumerical Solution of Volterra-Fredholm Integralneda gossiliNo ratings yet
- A New Operator Theory of Linear Partial Differential EquationsDocument28 pagesA New Operator Theory of Linear Partial Differential Equationsfayssal achhoudNo ratings yet
- Distance Metrics and Data Transformations: Jianxin WuDocument25 pagesDistance Metrics and Data Transformations: Jianxin WuXg WuNo ratings yet
- The Transformer Model in Equations: John ThickstunDocument5 pagesThe Transformer Model in Equations: John ThickstunCristian RodriguezNo ratings yet
- Report4 Density Estimation AllDocument63 pagesReport4 Density Estimation AllJohnNo ratings yet
- Discrete and Continuous Dynamical Systems Series S: Doi:10.3934/dcdss.2022029Document30 pagesDiscrete and Continuous Dynamical Systems Series S: Doi:10.3934/dcdss.2022029Vadel SniperNo ratings yet
- Application of Differential Equation in Computer ScienceDocument6 pagesApplication of Differential Equation in Computer ScienceUzair Razzaq100% (1)
- Batch Grinding KineticsDocument5 pagesBatch Grinding KineticsrodrigoalcainoNo ratings yet
- Band Edge Limit of The Scattering Matrix For Quasi-One-Dimensional Discrete SCHR Odinger OperatorsDocument26 pagesBand Edge Limit of The Scattering Matrix For Quasi-One-Dimensional Discrete SCHR Odinger OperatorsmemfilmatNo ratings yet
- Mvanginkel Radonandhough tr2004Document11 pagesMvanginkel Radonandhough tr2004Musadiq HussainNo ratings yet
- Chapter 16Document24 pagesChapter 16Pawan NegiNo ratings yet
- Optik: Original Research ArticleDocument14 pagesOptik: Original Research ArticleBaljinderNo ratings yet
- Opt2017 Part1Document48 pagesOpt2017 Part1Co londota2No ratings yet
- Modeling Stock Return Distributions With A Quantum Harmonic OscillatorDocument13 pagesModeling Stock Return Distributions With A Quantum Harmonic OscillatorMusical RabbitNo ratings yet
- Metric and Topological SpacesDocument89 pagesMetric and Topological SpacesOrxan QasimovNo ratings yet
- Calcul DiffDocument38 pagesCalcul Difffakraouicpge2019No ratings yet
- The Q-Exponentials Do Not Maximize The Rényi EntropyDocument12 pagesThe Q-Exponentials Do Not Maximize The Rényi EntropyKosKal89No ratings yet
- 2014 ElenaDocument20 pages2014 ElenaHaftuNo ratings yet
- Algorithms 17 00123Document12 pagesAlgorithms 17 00123jamel-shamsNo ratings yet
- Option Pricing Models With Jumps - Integro-Differential Equations and Inverse Problems-2004Document20 pagesOption Pricing Models With Jumps - Integro-Differential Equations and Inverse Problems-2004hichkas1981No ratings yet
- A. H. Bhrawy, M. M. Tharwat and M. A. AlghamdiDocument14 pagesA. H. Bhrawy, M. M. Tharwat and M. A. AlghamdiVe LopiNo ratings yet
- uH#w:M3 EE XFD") ) H ZXVPJTL, IcSAXDNreJAXvE6dP2 FEDocument1 pageuH#w:M3 EE XFD") ) H ZXVPJTL, IcSAXDNreJAXvE6dP2 FEheaan.lasaiNo ratings yet
- InformationDocument3 pagesInformationLeanna Elsie JadielNo ratings yet
- 1 s2.0 S0747717197901103 MainDocument30 pages1 s2.0 S0747717197901103 MainMerbsTimeline (Merblin)No ratings yet
- 10.3934 Math.2023108Document24 pages10.3934 Math.2023108satitz chongNo ratings yet
- Mujeeb Ur Rehman and Umer Saeed: C 2015 Korean Mathematical SocietyDocument28 pagesMujeeb Ur Rehman and Umer Saeed: C 2015 Korean Mathematical SocietyVe LopiNo ratings yet
- Aggregation of Interacting Criteria by Means of The Discrete Choquet IntegralDocument18 pagesAggregation of Interacting Criteria by Means of The Discrete Choquet Integralsilv_phNo ratings yet
- 02 Comss 22 Acar-TurgayDocument12 pages02 Comss 22 Acar-TurgayMustapha MaaroufNo ratings yet
- 1998 RS Zounes RH Rand Transition Curves For The Quasi-Periodic Mathieu Equation SIM J Appl Math 58Document22 pages1998 RS Zounes RH Rand Transition Curves For The Quasi-Periodic Mathieu Equation SIM J Appl Math 58TheodoraNo ratings yet
- On A Possible Geometric Interpretation of Relativistic Quantum Theory - 5Document5 pagesOn A Possible Geometric Interpretation of Relativistic Quantum Theory - 5John BirdNo ratings yet
- Toro 4-ADERDocument63 pagesToro 4-ADERyousel proledNo ratings yet
- An Overview On Tools From Functional Analysis: Matthias Augustin, Sarah Eberle, and Martin GrothausDocument35 pagesAn Overview On Tools From Functional Analysis: Matthias Augustin, Sarah Eberle, and Martin GrothaussergenNo ratings yet
- L23 - Postulates of QMDocument24 pagesL23 - Postulates of QMdomagix470No ratings yet
- Quantum Moment Hydrodynamics and The Entropy Principle: P. Degond and C. RinghoferDocument34 pagesQuantum Moment Hydrodynamics and The Entropy Principle: P. Degond and C. RinghofersoibalNo ratings yet
- Quantum MechanicsDocument22 pagesQuantum MechanicscrmzNo ratings yet
- Michael Parkinson PDFDocument6 pagesMichael Parkinson PDFPepeNo ratings yet
- The Quasi-Boundary Value Regularization Method For Identifying The Initial Value With Discrete Random NoiseDocument12 pagesThe Quasi-Boundary Value Regularization Method For Identifying The Initial Value With Discrete Random NoiseTrân TrọngNo ratings yet
- Algorithms For Solving Nonlinear Systems of EquationsDocument28 pagesAlgorithms For Solving Nonlinear Systems of Equationslvjiaze12No ratings yet
- Abdalla2020 Article OnPositiveSolutionsOfASystemOfDocument23 pagesAbdalla2020 Article OnPositiveSolutionsOfASystemOfMuhammad FouadNo ratings yet
- Sample Research PaperDocument26 pagesSample Research Paperfb8ndyffmcNo ratings yet
- Numerical IntegrationDocument16 pagesNumerical IntegrationBandita DasNo ratings yet
- Generalized Tensor Function Via The TensDocument39 pagesGeneralized Tensor Function Via The TensЕлена НиколаевскаяNo ratings yet
- The Generalized Variogram 2343Document61 pagesThe Generalized Variogram 2343Andres Alejandro Molina AlvarezNo ratings yet
- 1 s2.0 S0021904520301209 MainDocument36 pages1 s2.0 S0021904520301209 Mainafaf boudeboudaNo ratings yet
- Eshkuvatov, Z. K. 87 103Document17 pagesEshkuvatov, Z. K. 87 103Erwin RojasNo ratings yet
- Chapter 2 - Postulates of Quantum MechanicsDocument11 pagesChapter 2 - Postulates of Quantum Mechanicssolomon mwatiNo ratings yet
- Revised Notes of Unit 2Document17 pagesRevised Notes of Unit 2kanishkmodi31No ratings yet
- Nonlinear Quantum Mechanics: Results and Open Questions: Elementary Particles and FieldsDocument8 pagesNonlinear Quantum Mechanics: Results and Open Questions: Elementary Particles and Fieldsakr_659No ratings yet
- Low Variance Sampling Techniques For Particle FilterDocument7 pagesLow Variance Sampling Techniques For Particle FilterNguyen Manh QuanNo ratings yet
- An Implicit Difference Scheme For The Fourth-Order Nonlinear Partial Integro-Differential EquationsDocument25 pagesAn Implicit Difference Scheme For The Fourth-Order Nonlinear Partial Integro-Differential EquationstuljabhavanikfpcNo ratings yet
- Markov ProcessDocument4 pagesMarkov ProcessParul VermaNo ratings yet
- 01 Traffic Engineering - Traffic Models Calibration PDFDocument17 pages01 Traffic Engineering - Traffic Models Calibration PDFLestor NaribNo ratings yet
- An Introduction To Fractional CalculusDocument29 pagesAn Introduction To Fractional CalculusFredrik Joachim GjestlandNo ratings yet
- Simulasi Fenomena Aliran Daya Pada Sistem Tenaga Listrik "Ieee 5-Bus" Berbasis Metode Numeris Dan Berbantuan Aplikasi MatlabDocument9 pagesSimulasi Fenomena Aliran Daya Pada Sistem Tenaga Listrik "Ieee 5-Bus" Berbasis Metode Numeris Dan Berbantuan Aplikasi MatlabNaufal IndrastotoNo ratings yet
- LA5Document3 pagesLA5Rahat Ali KhanNo ratings yet
- Linear Algebra: Dama50 - Mathematics For Machine LearningDocument29 pagesLinear Algebra: Dama50 - Mathematics For Machine LearningPapadakis ChristosNo ratings yet
- Dy DX D y DX D y DX y D y DX Dy DX D Q DT R DQ DT Q C EsinwtDocument2 pagesDy DX D y DX D y DX y D y DX Dy DX D Q DT R DQ DT Q C Esinwtdaniel ayobamiNo ratings yet
- Fall 2023 - MTH603 - 1 - SOLDocument17 pagesFall 2023 - MTH603 - 1 - SOLNazir AhmadNo ratings yet
- Chapter 4Document37 pagesChapter 4Silabat AshagrieNo ratings yet
- Derivation of The Laplacian From PDFDocument6 pagesDerivation of The Laplacian From PDFEloy Alfonso FloresNo ratings yet
- Maths Ipe Imp Q & AnsDocument72 pagesMaths Ipe Imp Q & AnsSalmanAnjansNo ratings yet
- Lotto DesignDocument25 pagesLotto DesignClaudioNo ratings yet
- Matlab Basic Functions ReferenceDocument4 pagesMatlab Basic Functions ReferencebharatNo ratings yet
- Module 2Document98 pagesModule 2Bhavana ThummalaNo ratings yet
- James NotesDocument83 pagesJames NotesUmer HuzaifaNo ratings yet
- Notes On Riemann Integral: 1 Definition and First PropertiesDocument13 pagesNotes On Riemann Integral: 1 Definition and First PropertiesMuhammad Arslan Muhammad ArslanNo ratings yet
- Chapter 4 Signal Flow GraphDocument34 pagesChapter 4 Signal Flow GraphAbhishek PattanaikNo ratings yet
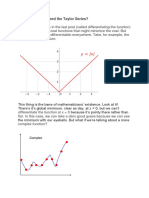
- The Taylor SeriesDocument5 pagesThe Taylor Seriessal27adamNo ratings yet
- Uniform Continuity: Ryan Acosta BabbDocument4 pagesUniform Continuity: Ryan Acosta Babbarvind lakshmi ranjanNo ratings yet
- Goursat A Course in Mathematical AnalysisDocument574 pagesGoursat A Course in Mathematical AnalysisGaurav Dhar100% (3)
- The Polynomials AssignmentDocument3 pagesThe Polynomials AssignmentMarc LambertNo ratings yet
- IMOmath - Functional Equations - Problems With SolutionsDocument15 pagesIMOmath - Functional Equations - Problems With SolutionsThang ThangNo ratings yet
- Limits, Continuity and Differentiability - GATE Study Material in PDFDocument9 pagesLimits, Continuity and Differentiability - GATE Study Material in PDFTestbook Blog33% (3)
- Multiple Choice Questions: Cbse Class 12 Maths MCQ'S & Case StudyDocument7 pagesMultiple Choice Questions: Cbse Class 12 Maths MCQ'S & Case StudyDhayananthNo ratings yet
- HKU MATH1853 - Brief Linear Algebra Notes: 1 Eigenvalues and EigenvectorsDocument6 pagesHKU MATH1853 - Brief Linear Algebra Notes: 1 Eigenvalues and EigenvectorsfirelumiaNo ratings yet
- Kruskal's ReportDocument2 pagesKruskal's ReportZenita DrostonNo ratings yet
- MA5156-Applied Mathematics For EngineersDocument16 pagesMA5156-Applied Mathematics For Engineerssivabalan rakasekaran67% (3)
- ECEG-6311 Power System Optimization and AI: Linear and Non Linear Programming Yoseph Mekonnen (PH.D.)Document25 pagesECEG-6311 Power System Optimization and AI: Linear and Non Linear Programming Yoseph Mekonnen (PH.D.)habte gebreial shrashrNo ratings yet
- Discrete Structures - Assignment-01: PART 1: CountingDocument2 pagesDiscrete Structures - Assignment-01: PART 1: CountingXYZNo ratings yet
- 116 Problems in Algebra - Functional EquationsDocument23 pages116 Problems in Algebra - Functional EquationsHoàng LongNo ratings yet
- BooleDocument1 pageBoolechegarrNo ratings yet
- Linear Algebra TD4 (2021 22) 1Document3 pagesLinear Algebra TD4 (2021 22) 1Ben MVPNo ratings yet
- Graphical Solution of LP Problems Hand-OutDocument11 pagesGraphical Solution of LP Problems Hand-Outdeleonjaniene bsaNo ratings yet
- Mental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)From EverandMental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)No ratings yet
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsFrom EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsRating: 4.5 out of 5 stars4.5/5 (3)
- Limitless Mind: Learn, Lead, and Live Without BarriersFrom EverandLimitless Mind: Learn, Lead, and Live Without BarriersRating: 4 out of 5 stars4/5 (6)
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.From EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Rating: 5 out of 5 stars5/5 (1)
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeFrom EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeRating: 4 out of 5 stars4/5 (2)
- Calculus Made Easy: Being a Very-Simplest Introduction to Those Beautiful Methods of Reckoning Which are Generally Called by the Terrifying Names of the Differential Calculus and the Integral CalculusFrom EverandCalculus Made Easy: Being a Very-Simplest Introduction to Those Beautiful Methods of Reckoning Which are Generally Called by the Terrifying Names of the Differential Calculus and the Integral CalculusRating: 4.5 out of 5 stars4.5/5 (2)
- Math Workshop, Grade K: A Framework for Guided Math and Independent PracticeFrom EverandMath Workshop, Grade K: A Framework for Guided Math and Independent PracticeRating: 5 out of 5 stars5/5 (1)
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingFrom EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingRating: 4.5 out of 5 stars4.5/5 (21)
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormFrom EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormRating: 5 out of 5 stars5/5 (5)