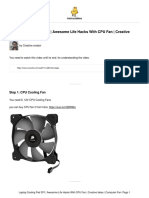
You might also like
- SAP interface programming with RFC and VBA: Edit SAP data with MS AccessFrom EverandSAP interface programming with RFC and VBA: Edit SAP data with MS AccessNo ratings yet
- PD1 Set1Document15 pagesPD1 Set1Kashyap Joshi100% (2)
- SAS Programming Guidelines Interview Questions You'll Most Likely Be AskedFrom EverandSAS Programming Guidelines Interview Questions You'll Most Likely Be AskedNo ratings yet
- 2023 Aug Airline Sentiment Analysis With A Transformer Artificial Neural NetworkDocument14 pages2023 Aug Airline Sentiment Analysis With A Transformer Artificial Neural NetworkAli Riza SARALNo ratings yet
- All Interview QuestionsDocument5 pagesAll Interview QuestionsDinesh GoyalNo ratings yet
- Excel Formulas Interview QuestionsDocument8 pagesExcel Formulas Interview QuestionsLeonor PereiraNo ratings yet
- AWR ReportDocument20 pagesAWR Reportsanjayid1980No ratings yet
- Self-Test Questions - Week 01Document4 pagesSelf-Test Questions - Week 01uacs20043441No ratings yet
- Prova Mais RecenteDocument4 pagesProva Mais Recentedif.conhecimentoNo ratings yet
- Gathering A StatsPack SnapshotDocument5 pagesGathering A StatsPack Snapshotelcaso34No ratings yet
- II Sem It, Iot, Air List of Experiment and Skill Based Mini ProjectsDocument4 pagesII Sem It, Iot, Air List of Experiment and Skill Based Mini ProjectsSneha AgrawalNo ratings yet
- C Entire NotesDocument127 pagesC Entire NotessrujanangNo ratings yet
- 1.what Are Non-Additive Facts in Detail?Document17 pages1.what Are Non-Additive Facts in Detail?Ravikumar MandalapuNo ratings yet
- Exam 1 690C 2020 SOLUTIONS StataDocument6 pagesExam 1 690C 2020 SOLUTIONS StatajminyosoNo ratings yet
- COBOL Compiler OptionsDocument56 pagesCOBOL Compiler OptionsRabindra2416No ratings yet
- What Is Page Directives? What Is Master Page? What Is Design Pattern? What Is Adrotator?Document7 pagesWhat Is Page Directives? What Is Master Page? What Is Design Pattern? What Is Adrotator?Vipin JainNo ratings yet
- Realtek RF MP Tool Guidelines V19Document24 pagesRealtek RF MP Tool Guidelines V19Luan SantosNo ratings yet
- ABAP Technical QuestionsDocument58 pagesABAP Technical QuestionsamolbandalNo ratings yet
- Contract SearchDocument183 pagesContract SearchParvati BNo ratings yet
- PD1 Set2Document9 pagesPD1 Set2Kashyap JoshiNo ratings yet
- Industrial Management & Professional Safety TechniquesDocument1 pageIndustrial Management & Professional Safety Techniquesحمزة عبد الهادي حسونNo ratings yet
- Cross Database Comparison: Enhancement GuideDocument35 pagesCross Database Comparison: Enhancement GuideParatchana JanNo ratings yet
- MCS-051 Solved Assignment July-Jan 2013-14 PDFDocument0 pagesMCS-051 Solved Assignment July-Jan 2013-14 PDFAkshay Bhairu KhamkarNo ratings yet
- Interview QuestionDocument5 pagesInterview QuestionrathodshriNo ratings yet
- Interview questions-SQLDocument2 pagesInterview questions-SQLsatyq SivaNo ratings yet
- Principles of Biostatistics and Data AnalysisDocument51 pagesPrinciples of Biostatistics and Data Analysis.cadeau01No ratings yet
- Web Based Crime Records Management SystemDocument9 pagesWeb Based Crime Records Management SystemKorby Okyere DarkoNo ratings yet
- SAP Repetitive Manufacturing With Reporting Point BackflushDocument12 pagesSAP Repetitive Manufacturing With Reporting Point BackflushDevidas Karad100% (1)
- Big Data 2017 Presales AssessmentDocument52 pagesBig Data 2017 Presales AssessmentArole AyodejiNo ratings yet
- Python Basic LearningDocument8 pagesPython Basic LearningArslan AbdullahNo ratings yet
- Locating Similar SQL in OracleDocument5 pagesLocating Similar SQL in Oracleapi-3759101No ratings yet
- SpdocDocument36 pagesSpdocgaros3No ratings yet
- Ebss 111Document88 pagesEbss 111jwaladhivenkatesh1No ratings yet
- SN-IMC-1-036 Cyclic Redundancy CheckDocument5 pagesSN-IMC-1-036 Cyclic Redundancy CheckSergio R. GomarNo ratings yet
- STATSPACK Solve Perf IssuesDocument50 pagesSTATSPACK Solve Perf IssuesankurdiwanNo ratings yet
- Dam Project ReportDocument35 pagesDam Project ReportMuhammad SardaarNo ratings yet
- SpdocDocument62 pagesSpdocmaahjoorNo ratings yet
- Step-By-Step Guide To Ale and Idocs: Sap Virtual/Onsite TrainingsDocument4 pagesStep-By-Step Guide To Ale and Idocs: Sap Virtual/Onsite Trainingsmail2use90No ratings yet
- Avm RDPDocument98 pagesAvm RDPsirishaNo ratings yet
- Step by Step Tutorials in Bapi-SAP ABAPDocument116 pagesStep by Step Tutorials in Bapi-SAP ABAPNelson GarciaNo ratings yet
- 123step by Step Tutorials in Bapi Sap Abap PDF FreeDocument116 pages123step by Step Tutorials in Bapi Sap Abap PDF FreeReign AckermannNo ratings yet
- SDETDocument6 pagesSDETgunaNo ratings yet
- MCS-051 Solved AssignmentsDocument37 pagesMCS-051 Solved AssignmentsAbhijit MalakarNo ratings yet
- R Integration For Golden Batch: SchedulerDocument3 pagesR Integration For Golden Batch: SchedulerPriyank SrivastavaNo ratings yet
- Day 1Document3 pagesDay 1GururajHudgiNo ratings yet
- Release NotesDocument16 pagesRelease NotesRiki MizusakiNo ratings yet
- SS Black Belt Test QnADocument22 pagesSS Black Belt Test QnAVyas Z100% (1)
- Sap TestingDocument5 pagesSap Testingdillipsahoo2012No ratings yet
- Data StructureDocument11 pagesData StructureSamriddhi NayakNo ratings yet
- UI PathDocument22 pagesUI PathPreethiNo ratings yet
- Header Data: SymptomDocument2 pagesHeader Data: SymptomMoeed Ahmed BaigNo ratings yet
- SamplerSight Pharma PDFDocument117 pagesSamplerSight Pharma PDFHoài PhạmNo ratings yet
- Oracle PLSQL Tuning GuideDocument19 pagesOracle PLSQL Tuning GuideYathindra sheshappaNo ratings yet
- Assessment PointsDocument2 pagesAssessment Pointsvmalik1981No ratings yet
- Study Routing Material Contributed by Ulhas KavleDocument23 pagesStudy Routing Material Contributed by Ulhas Kavlesaisuni.mNo ratings yet
- Graphically displays variation in a processDocument17 pagesGraphically displays variation in a processPravuNo ratings yet
- Computer Science I 8Document1 pageComputer Science I 8cde852No ratings yet
- CSS Manual Questions Print OutDocument22 pagesCSS Manual Questions Print OutAayush RaksheNo ratings yet
- Correct database issue with ABAP Code InspectorDocument11 pagesCorrect database issue with ABAP Code InspectorEsther VizarroNo ratings yet
- BW SPRO SettingDocument19 pagesBW SPRO SettingAjay TiwariNo ratings yet
- WordPress Developer Intern AssignmentDocument4 pagesWordPress Developer Intern AssignmentSHREYANSHU KODILKARNo ratings yet
- Assignement 4Document6 pagesAssignement 4SHREYANSHU KODILKARNo ratings yet
- SalesforceDocument12 pagesSalesforceSHREYANSHU KODILKARNo ratings yet
- CC Easy Solution 2019Document68 pagesCC Easy Solution 2019SHREYANSHU KODILKARNo ratings yet
- JNK PPT v2Document26 pagesJNK PPT v2SHREYANSHU KODILKARNo ratings yet
- Discover the natural beauty and cultural heritage of Jammu and KashmirDocument15 pagesDiscover the natural beauty and cultural heritage of Jammu and KashmirSHREYANSHU KODILKARNo ratings yet
- Design - 02 - TimeLine Infographic 12 Steps Business PowerPoint Prefvbjbsentation.Document2 pagesDesign - 02 - TimeLine Infographic 12 Steps Business PowerPoint Prefvbjbsentation.SHREYANSHU KODILKARNo ratings yet
- Basics of Robotics: Yuvraj Khelkar (SC69) Surabhi Annigeri (SC58) Shreyanshu Kodilkar (SC55)Document16 pagesBasics of Robotics: Yuvraj Khelkar (SC69) Surabhi Annigeri (SC58) Shreyanshu Kodilkar (SC55)SHREYANSHU KODILKAR100% (1)
- Savvion BPM Installation GuideDocument152 pagesSavvion BPM Installation GuideJagdish BhanushaliNo ratings yet
- VSM Recruiting-The Lean WayDocument12 pagesVSM Recruiting-The Lean Wayrinto.epNo ratings yet
- EC6703 Embedded Real Time Systems Course OutlineDocument2 pagesEC6703 Embedded Real Time Systems Course OutlineSuresh Kumar100% (1)
- Lecture 12 SRAMDocument37 pagesLecture 12 SRAMSucharitha ReddyNo ratings yet
- IP Lab Manual 8661 ReadyDocument105 pagesIP Lab Manual 8661 ReadyRADHANo ratings yet
- String Functions With ExamplesDocument6 pagesString Functions With Examplesprataplavu1No ratings yet
- Branch Name B.E. Aeronautical Engineering: Semes Ter Subject Name Subject Code Exam Date SessionDocument99 pagesBranch Name B.E. Aeronautical Engineering: Semes Ter Subject Name Subject Code Exam Date SessionCoding HintsNo ratings yet
- Home AutomationDocument56 pagesHome AutomationDevdatta Supnekar67% (3)
- Activity2 Packet Tracer - Creating An Ethernet LANDocument3 pagesActivity2 Packet Tracer - Creating An Ethernet LANHannah Bea LindoNo ratings yet
- Exam 350-401 - Pg10Document5 pagesExam 350-401 - Pg10Info4 DetailNo ratings yet
- Thesis Hamza Ed-Douibi PDFDocument200 pagesThesis Hamza Ed-Douibi PDFmauriciovilleNo ratings yet
- EWB - Vehicle Tracking Mobile AppDocument16 pagesEWB - Vehicle Tracking Mobile AppLeenaNo ratings yet
- Topic - Unit 5 - Team Problem Solving Activity - Unit 5 Group 3Document13 pagesTopic - Unit 5 - Team Problem Solving Activity - Unit 5 Group 3Vyshnavi ThottempudiNo ratings yet
- Level 3 Unit 11 Maintaining Computer Systems PDFDocument9 pagesLevel 3 Unit 11 Maintaining Computer Systems PDFfaisal saghir0% (1)
- Generate Hotel DBR Reports with easeDocument21 pagesGenerate Hotel DBR Reports with easeVivek SuryaNo ratings yet
- Python ZTM Cheatsheet: Andrei NeagoieDocument38 pagesPython ZTM Cheatsheet: Andrei NeagoieJoe KingNo ratings yet
- FS07 - Manual - EN - 2021.04.23 ADocument23 pagesFS07 - Manual - EN - 2021.04.23 AJunior SanchesNo ratings yet
- Sukhwinder Exam ConfirmationDocument2 pagesSukhwinder Exam ConfirmationOPERATIONAL WINSTARNo ratings yet
- FCPIT Practical FileDocument6 pagesFCPIT Practical FileShefali GuptaNo ratings yet
- Guide To Design Database For Employee Management System in MySQLDocument8 pagesGuide To Design Database For Employee Management System in MySQLDinh Ai VuNo ratings yet
- Equinox Port-MatrixDocument10 pagesEquinox Port-MatrixDanielNo ratings yet
- Procedure For Uploading Employee Photos Into SAPDocument24 pagesProcedure For Uploading Employee Photos Into SAPnstomarNo ratings yet
- History and Development of Linux22Document260 pagesHistory and Development of Linux22Jatinder RandahwaNo ratings yet
- DIY Laptop Cooling Pad Using CPU FansDocument7 pagesDIY Laptop Cooling Pad Using CPU FansRahro ShamlouNo ratings yet
- IT205 Course SyllabusDocument10 pagesIT205 Course SyllabusNathaniel JohnstonNo ratings yet
- AzureadDocument59 pagesAzureadBala SubramanyamNo ratings yet
- Test Plan:: Google WebsiteDocument9 pagesTest Plan:: Google WebsitePriti GuptaNo ratings yet
- Python IntroductionDocument28 pagesPython IntroductionvickyvermaNo ratings yet
- Digital Principles and System Design Lecture PlanDocument3 pagesDigital Principles and System Design Lecture PlanaddssdfaNo ratings yet