You might also like
- Simulation of Digital Communication Systems Using MatlabFrom EverandSimulation of Digital Communication Systems Using MatlabRating: 3.5 out of 5 stars3.5/5 (22)
- Cn-Unit Iii-NotesDocument39 pagesCn-Unit Iii-NotesRobin RobinNo ratings yet
- Unit 3Document31 pagesUnit 320H51A04P3-PEDAPUDI SHAKTHI GANESH B.Tech ECE (2020-24)No ratings yet
- 002 Network LayerDocument7 pages002 Network LayerDibyasundar DasNo ratings yet
- Unit-Iii: (Q) Explain Network Layer Design Issues? (2M/5M)Document28 pagesUnit-Iii: (Q) Explain Network Layer Design Issues? (2M/5M)karthik vaddiNo ratings yet
- Module - 3 Network LayerDocument27 pagesModule - 3 Network Layer1NC21IS033 Manoj jayanth NNo ratings yet
- Network Layer (Continued... )Document9 pagesNetwork Layer (Continued... )Delli HarinNo ratings yet
- Ubiccjournalvolume2no3 1 25Document5 pagesUbiccjournalvolume2no3 1 25Ubiquitous Computing and Communication JournalNo ratings yet
- Computer NetworksDocument4 pagesComputer NetworksYashwanth KumarNo ratings yet
- Routing Algorithms (Distance Vector, Link State) Study Notes - Computer Sc. & EnggDocument6 pagesRouting Algorithms (Distance Vector, Link State) Study Notes - Computer Sc. & Enggkavya associatesNo ratings yet
- Network Layer Delivery, Forwarding and RoutingDocument46 pagesNetwork Layer Delivery, Forwarding and RoutingJohn AmonNo ratings yet
- CN - Unit Iii NotesDocument45 pagesCN - Unit Iii Notesu25sivakumarNo ratings yet
- CNS Mod 3 NLDocument23 pagesCNS Mod 3 NLSamanthNo ratings yet
- Unit Iii Network LayerDocument75 pagesUnit Iii Network LayerAnonymous hLoSp33No ratings yet
- Unit 4 Network LayerDocument43 pagesUnit 4 Network LayerRahul ChugwaniNo ratings yet
- An Enriched Reactive Routing Protocol - AODV For Mobile Adhoc NetworksDocument6 pagesAn Enriched Reactive Routing Protocol - AODV For Mobile Adhoc Networksjayesh patilNo ratings yet
- A B C D R2 R4: Source RouterDocument15 pagesA B C D R2 R4: Source Routerabhilashsjce100% (1)
- UNIT-III Network LayerDocument118 pagesUNIT-III Network LayerSARKARI BABUNo ratings yet
- UNIT-4: The Network LayerDocument83 pagesUNIT-4: The Network LayerNAMAN JAISWALNo ratings yet
- Spanning Tree Protocol Topology DiscoveryDocument23 pagesSpanning Tree Protocol Topology DiscoveryThomas WilkinsonNo ratings yet
- Dynamic Load Balancing in SDN - ShivaAmrit, RamyaDocument5 pagesDynamic Load Balancing in SDN - ShivaAmrit, RamyaShiva AmritNo ratings yet
- CN Unit-4 NotesDocument24 pagesCN Unit-4 Notessivakanthvaddi61No ratings yet
- Lecture 3Document12 pagesLecture 3pradeepkumar.mahapatroNo ratings yet
- Computer NetworksDocument47 pagesComputer NetworksJeena Mol AbrahamNo ratings yet
- Routing in General Distance Vector RoutingDocument75 pagesRouting in General Distance Vector RoutingSubhrendu Guha NeogiNo ratings yet
- Important Portions m3 m4 m5Document104 pagesImportant Portions m3 m4 m5hamdhanNo ratings yet
- 12 RoutingDocument31 pages12 RoutingAbdul RahmanNo ratings yet
- Unit 4Document16 pagesUnit 4Senthilnathan SNo ratings yet
- Routing in General Distance Vector Routing: Jean-Yves Le BoudecDocument75 pagesRouting in General Distance Vector Routing: Jean-Yves Le BoudecSatish NaiduNo ratings yet
- CS8591 / Computer Networks Department of CSE & IT 2019 - 2020Document25 pagesCS8591 / Computer Networks Department of CSE & IT 2019 - 2020logesswari srinivasanNo ratings yet
- 4 Basic Routing Theory II - Adaptive Routing: Log N) For Oblivious Routing On TheDocument8 pages4 Basic Routing Theory II - Adaptive Routing: Log N) For Oblivious Routing On TheGabriel IonNo ratings yet
- Chapter 4 Bit4001+q+ExDocument77 pagesChapter 4 Bit4001+q+ExĐình Đức PhạmNo ratings yet
- Unit 3Document106 pagesUnit 3sona jainNo ratings yet
- Data and Computer CommunicationsDocument32 pagesData and Computer Communicationschellam1_kalaiNo ratings yet
- Computer Networks (CS425) : Network Layer (Continued... )Document3 pagesComputer Networks (CS425) : Network Layer (Continued... )akyadav123No ratings yet
- Performance Evaluation of AODV For Mobile Ad Hoc Network With Varying Probability and Node MobilityDocument5 pagesPerformance Evaluation of AODV For Mobile Ad Hoc Network With Varying Probability and Node MobilityThu HangNo ratings yet
- Network LayerDocument134 pagesNetwork Layershivang pandeyNo ratings yet
- Data and Computer CommunicationsDocument32 pagesData and Computer CommunicationssantanoopNo ratings yet
- Static Vs Dynamic: Routing AlgorithmDocument10 pagesStatic Vs Dynamic: Routing AlgorithmAnjuPandeyNo ratings yet
- ProtocolDocument6 pagesProtocol19021Dhanush raj.NNo ratings yet
- (64-73) A Study of Congestion Aware Adaptive Routing Protocols in MANETDocument11 pages(64-73) A Study of Congestion Aware Adaptive Routing Protocols in MANETAlexander DeckerNo ratings yet
- Routing AlgorithmsDocument36 pagesRouting AlgorithmsKartik Aneja0% (1)
- Design Issues of Network LayerDocument16 pagesDesign Issues of Network LayerPrateek Sancheti100% (1)
- Functions of Network Layer Routing TableDocument4 pagesFunctions of Network Layer Routing TableAkshay VNo ratings yet
- Lecture Routing 1 18 April 2022Document66 pagesLecture Routing 1 18 April 2022Dinkar Laxman BhombeNo ratings yet
- The Switch Book by Rich Seifert-NotesDocument51 pagesThe Switch Book by Rich Seifert-NotesharinijNo ratings yet
- Faculty of Engineering, Sciences & Technology: Assignment # 03 - Spring Semester 2020Document8 pagesFaculty of Engineering, Sciences & Technology: Assignment # 03 - Spring Semester 2020Muhammad Usman AfaqNo ratings yet
- Removing Convergence Using FCP With Source Path RoutingDocument6 pagesRemoving Convergence Using FCP With Source Path RoutinginventionjournalsNo ratings yet
- Network Layer (Chapter 1)Document22 pagesNetwork Layer (Chapter 1)Sathish ShettyNo ratings yet
- Network LayerDocument76 pagesNetwork LayerKarthik MNo ratings yet
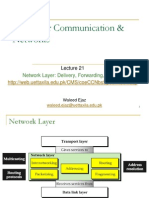
- Computer Communication & Networks: Network Layer: Delivery, Forwarding, RoutingDocument36 pagesComputer Communication & Networks: Network Layer: Delivery, Forwarding, RoutingAli AhmadNo ratings yet
- LindqvistDocument4 pagesLindqvistVikram Kumaar PoudelNo ratings yet
- Theory, Laboratories and Exercises For Mikrotik RouterOSDocument187 pagesTheory, Laboratories and Exercises For Mikrotik RouterOSwilliam quispeNo ratings yet
- Dynamic Source RoutingDocument6 pagesDynamic Source RoutingVignesh AppuNo ratings yet
- Lecture #5 THRDocument45 pagesLecture #5 THRZainab ShahzadNo ratings yet
- Research Inventy: International Journal of Engineering and ScienceDocument5 pagesResearch Inventy: International Journal of Engineering and ScienceinventyNo ratings yet
- CN-Unit 1 Routing AlgorithmsDocument68 pagesCN-Unit 1 Routing AlgorithmsDaksha 2001No ratings yet
- STX Scheme For Reducing Latency With Centralized Matching AlgorithmsDocument12 pagesSTX Scheme For Reducing Latency With Centralized Matching Algorithmstharani_vanithaNo ratings yet
- 11 Sewing Patterns For Womens Dresses Other Pretty Projects PDFDocument46 pages11 Sewing Patterns For Womens Dresses Other Pretty Projects PDFmynameisgook67% (3)
- Gps Tracker CatalogDocument8 pagesGps Tracker CatalogAurélio FariaNo ratings yet
- 911175958Document6 pages911175958Willy Erwin TieNo ratings yet
- Dgcis Report Kolkata PDFDocument12 pagesDgcis Report Kolkata PDFABCDNo ratings yet
- LKG AppleDocument16 pagesLKG AppleKhaderAliNo ratings yet
- Elizabeth Lara Wollman-The Theater Will Rock - A History of The Rock Musical, From Hair To Hedwig-University of Michigan Press (2006)Document289 pagesElizabeth Lara Wollman-The Theater Will Rock - A History of The Rock Musical, From Hair To Hedwig-University of Michigan Press (2006)Maria Fernanda Ortiz Aguirre100% (3)
- Nombre. Leidy Viviana Fajardo Lopez Grupo:1A PAG2: I. Circle The Correct Answers. III. Put in Much or ManyDocument12 pagesNombre. Leidy Viviana Fajardo Lopez Grupo:1A PAG2: I. Circle The Correct Answers. III. Put in Much or ManyLEIDY VIVIANA FAJARDO L�PEZNo ratings yet
- Extra Magic Items Expansion (10940777)Document13 pagesExtra Magic Items Expansion (10940777)Dana Helman100% (1)
- Julius Caesar SummaryDocument2 pagesJulius Caesar SummaryAmAr MoHit Jaiswal100% (1)
- Itera Lec Reviewer-PrelimDocument26 pagesItera Lec Reviewer-PrelimMark SimeonNo ratings yet
- Iec 60065 A1-2005Document18 pagesIec 60065 A1-2005Paul DavidsonNo ratings yet
- Business Proposal TemplateDocument5 pagesBusiness Proposal Templatenatnael ebrahimNo ratings yet
- Sesión 14 Grupo Caso Familia Fundamentos de MercadeoDocument10 pagesSesión 14 Grupo Caso Familia Fundamentos de MercadeoJoe BalenciagaNo ratings yet
- Ericas Ensemble Repertoir ListDocument3 pagesEricas Ensemble Repertoir Listapi-499207949No ratings yet
- List of Compositions by ChopinDocument16 pagesList of Compositions by Chopindamdidam1No ratings yet
- R.B. Pandey & Co.: Dealer & Distributors of National & Internationals Newspapers/Magazines/Journals)Document10 pagesR.B. Pandey & Co.: Dealer & Distributors of National & Internationals Newspapers/Magazines/Journals)rannvijay pandeyNo ratings yet
- 9 PPMP (Gap)Document3 pages9 PPMP (Gap)Eugene GuillermoNo ratings yet
- Crop ImprovementDocument7 pagesCrop Improvementshahena sNo ratings yet
- 10 Punjabi DishesDocument4 pages10 Punjabi DishesrajNo ratings yet
- Editor ReadmeDocument40 pagesEditor ReadmeTaekyongKimNo ratings yet
- Punjab Costume SimulationDocument5 pagesPunjab Costume SimulationKaren Ting Jia SzeNo ratings yet
- Train To PakistanDocument7 pagesTrain To Pakistanvineela_13120% (1)
- Grooving With The Clave: GuitarDocument4 pagesGrooving With The Clave: GuitarJosmer De Abreu100% (1)
- Bettelheim EssayDocument5 pagesBettelheim Essaynjimenez4u100% (1)
- FBS Assignment081023Document5 pagesFBS Assignment081023Mac BellosilloNo ratings yet
- ThefourthwallDocument1 pageThefourthwallapi-201512422No ratings yet
- Play Time: The 2009 Taylor LineDocument56 pagesPlay Time: The 2009 Taylor Lineuchoa100% (1)
- Data Sheet KongsbergDocument53 pagesData Sheet KongsbergSimone BaptistaNo ratings yet
- Picture PromtsDocument57 pagesPicture PromtsOxana MarinescuNo ratings yet