You might also like
- Python - 1 Year - Unit-3Document100 pagesPython - 1 Year - Unit-3Bessy BijoNo ratings yet
- TCL TutorialDocument30 pagesTCL TutorialAhmed AliNo ratings yet
- Splunk Enterprise Security Certified Admin SPLK 3001 Dumps V10.02 DumpsBase PDFDocument10 pagesSplunk Enterprise Security Certified Admin SPLK 3001 Dumps V10.02 DumpsBase PDFdentaltzNo ratings yet
- Perl IntroductionDocument43 pagesPerl IntroductionRamya RamasubramanianNo ratings yet
- String Lists Tuples Dictionaries: Module-2Document166 pagesString Lists Tuples Dictionaries: Module-2harsha sidNo ratings yet
- 1 - TCL Tutorial CAD Glossary PDFDocument35 pages1 - TCL Tutorial CAD Glossary PDFmohana_raoY100% (1)
- Polyglot BSDDocument41 pagesPolyglot BSDclaud allenNo ratings yet
- TCL/TK Tutorial: Fan Yang Kristy HollingsheadDocument30 pagesTCL/TK Tutorial: Fan Yang Kristy Hollingsheadmalexa23100% (1)
- DS WhitePapers Enterprise Knowledge Language Overview and Usage V1.0Document51 pagesDS WhitePapers Enterprise Knowledge Language Overview and Usage V1.0fibriladoNo ratings yet
- LECTURE 5 Cheat Sheet PythonDocument12 pagesLECTURE 5 Cheat Sheet Pythondhanhicha botonNo ratings yet
- Programming Using TCL/TK: These Slides Are Based Upon Several TCL/TK Text Books Material Bydr. Ernest J. Friedman-HillDocument27 pagesProgramming Using TCL/TK: These Slides Are Based Upon Several TCL/TK Text Books Material Bydr. Ernest J. Friedman-HillRaghuram GudeNo ratings yet
- PythonGuide V1.2.9Document2 pagesPythonGuide V1.2.9Samir Al-Bayati100% (1)
- Python Course NotesDocument10 pagesPython Course NotesPepeNo ratings yet
- Chapter Two Variables and Data TypesDocument24 pagesChapter Two Variables and Data TypesStudent RitwanNo ratings yet
- Other Structured Types Sets, Tuples, DictionariesDocument19 pagesOther Structured Types Sets, Tuples, DictionariesJatin SinghNo ratings yet
- Wk05 Sequences 1Document63 pagesWk05 Sequences 1WU ThexhNo ratings yet
- CSE100 wk8 StringDocument25 pagesCSE100 wk8 StringRazia Sultana Ankhy StudentNo ratings yet
- ListsDocument30 pagesListsnavya mehrotraNo ratings yet
- Python Notes Aug 25Document14 pagesPython Notes Aug 25vickyNo ratings yet
- Python in 90 MinutesDocument53 pagesPython in 90 Minutesshyed20012721No ratings yet
- Regular Expressions PythonDocument26 pagesRegular Expressions PythonRaja O Romeyo NaveenNo ratings yet
- TCL/TK Tutorial: Fan Yang Fly@cslu - Ogi.edu Kristy Hollingshead Hollingk@cslu - Ogi.eduDocument30 pagesTCL/TK Tutorial: Fan Yang Fly@cslu - Ogi.edu Kristy Hollingshead Hollingk@cslu - Ogi.eduneelamvamsiNo ratings yet
- Lec 4Document61 pagesLec 4Akshay RathodNo ratings yet
- Py4Inf 10 TuplesDocument17 pagesPy4Inf 10 TuplesjunedijoasliNo ratings yet
- Python Unit1Document24 pagesPython Unit1boratkarvanshNo ratings yet
- StringsDocument29 pagesStringsSamNo ratings yet
- Cpoopg2l Notes MidtermDocument13 pagesCpoopg2l Notes Midtermjohn.delmarkpagulongNo ratings yet
- Introduction To Python: 6th School On LHC PhysicsDocument24 pagesIntroduction To Python: 6th School On LHC PhysicsManzoor aliNo ratings yet
- Lecture 3 - CSLDocument12 pagesLecture 3 - CSLAkhil Preetham SNo ratings yet
- Unit3 2Document75 pagesUnit3 2bt21103054 Rithik GargNo ratings yet
- Python Cheat Sheet & Quick ReferenceDocument35 pagesPython Cheat Sheet & Quick ReferenceMostafa MirbabaieNo ratings yet
- ArrayDocument23 pagesArrayharishNo ratings yet
- Perl File I/O and ArraysDocument45 pagesPerl File I/O and ArraysNowo AdisuryoNo ratings yet
- Python From ScratchDocument8 pagesPython From ScratchAkashRaiNo ratings yet
- Lecture 3 - CS50x PDFDocument14 pagesLecture 3 - CS50x PDFEmily SiaNo ratings yet
- Sequences, Strings and SetsDocument40 pagesSequences, Strings and SetsMazen JamalNo ratings yet
- FoP Ch02 DataType VariablesDocument28 pagesFoP Ch02 DataType VariablesQuang Sang NguyễnNo ratings yet
- Python Basics Warp UpDocument20 pagesPython Basics Warp UpTemoNo ratings yet
- Pythin LearningsDocument51 pagesPythin LearningsNeha KhatriNo ratings yet
- Tuples: Python For EverybodyDocument16 pagesTuples: Python For EverybodyCarmineCatalanoNo ratings yet
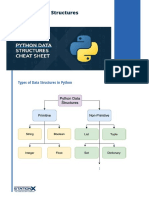
- Python Data Structures Cheat SheetDocument9 pagesPython Data Structures Cheat SheetStavros T.No ratings yet
- Summary in PythonDocument23 pagesSummary in PythonMd Himel HossainNo ratings yet
- List Tuple Concepts in Python 26aug2022Document7 pagesList Tuple Concepts in Python 26aug2022aditya.cse121118No ratings yet
- Scripting Languages Perl Basics: Course: 67557 Hebrew University Lecturer: Elliot Jaffe - הפי טוילאDocument48 pagesScripting Languages Perl Basics: Course: 67557 Hebrew University Lecturer: Elliot Jaffe - הפי טוילאmohan_ramakrishnaNo ratings yet
- LTSDDocument28 pagesLTSDHyder NabiNo ratings yet
- Unix Scripting: A Tutorial For Computational Linguistics (CSE 506/606)Document12 pagesUnix Scripting: A Tutorial For Computational Linguistics (CSE 506/606)annaNo ratings yet
- Web Technologies 2: Arrays & FunctionsDocument36 pagesWeb Technologies 2: Arrays & Functionsrafeak rafeakNo ratings yet
- Python Regex Cheat SheetDocument29 pagesPython Regex Cheat SheetIgor SzalajNo ratings yet
- Basics of PythonDocument8 pagesBasics of PythonsumitNo ratings yet
- Discrete Structures Lab 1 Python Basics: 1 Python Installation 2 Python TutorialDocument8 pagesDiscrete Structures Lab 1 Python Basics: 1 Python Installation 2 Python Tutorialhuy phanNo ratings yet
- Lecture 2Document8 pagesLecture 2azharuddin7777No ratings yet
- Chapter 1 Sets ML Agarwal Class 11Document16 pagesChapter 1 Sets ML Agarwal Class 11MISANo ratings yet
- Chapter Three: SequencesDocument34 pagesChapter Three: SequencesKhathutshelo KharivheNo ratings yet
- ENGR 101.week 11 - HMA - v2Document36 pagesENGR 101.week 11 - HMA - v2Antep Fıstık SepetiNo ratings yet
- Tuples: Python For EverybodyDocument16 pagesTuples: Python For EverybodyNofril ZendriadiNo ratings yet
- Python BasicDocument12 pagesPython BasicTrường PhanNo ratings yet
- Python ReviewDocument6 pagesPython ReviewCHOWDARY A.SUSHMANo ratings yet
- Python Quick Reference Guide Heinold PDFDocument9 pagesPython Quick Reference Guide Heinold PDFRamanjeet SinghNo ratings yet
- Python for Beginners: This comprehensive introduction to the world of coding introduces you to the Python programming languageFrom EverandPython for Beginners: This comprehensive introduction to the world of coding introduces you to the Python programming languageNo ratings yet
- CH05 TBDocument17 pagesCH05 TBsan marcoNo ratings yet
- What's New at 2019 R1 Mechanical EnhancementsDocument21 pagesWhat's New at 2019 R1 Mechanical EnhancementsFgirard scribtNo ratings yet
- Introduction To Microsoft Azure Resource Manager (ARM)Document11 pagesIntroduction To Microsoft Azure Resource Manager (ARM)vatcheNo ratings yet
- Cache Object ScriptDocument228 pagesCache Object ScriptAjay Vikram SinghNo ratings yet
- Perm LogDocument20 pagesPerm Logmodki27No ratings yet
- Anay Dev VB - NET Practical FileDocument51 pagesAnay Dev VB - NET Practical Filejims bca2019No ratings yet
- Ansible NotesDocument39 pagesAnsible Notesweslians2018No ratings yet
- Sec2 Final Revision With Answer PDFDocument7 pagesSec2 Final Revision With Answer PDFAnas TamerNo ratings yet
- Free PHP PDF StamperDocument2 pagesFree PHP PDF StamperJenny0% (1)
- Bai Tap Cho Asm1Document28 pagesBai Tap Cho Asm1ducanhNo ratings yet
- 05 Ooad-Uml 05Document27 pages05 Ooad-Uml 05Hiren BhingaradiyaNo ratings yet
- The Solid Principles SlidesDocument37 pagesThe Solid Principles SlidesAbdul Hafeez MunawarNo ratings yet
- Full-Stack DeveloperDocument2 pagesFull-Stack DeveloperLezardValeth12No ratings yet
- 8.advanced StringDocument35 pages8.advanced StringManoj ManuNo ratings yet
- DCA6203 - WEB TECHNOLOGIES - ASSIGNMENT (Mohammad Mudasir)Document13 pagesDCA6203 - WEB TECHNOLOGIES - ASSIGNMENT (Mohammad Mudasir)Mudasir KhanNo ratings yet
- Khushi Jaiswal ResumeDocument1 pageKhushi Jaiswal Resumekhushijaiswal080203No ratings yet
- Functions: Unit 4Document34 pagesFunctions: Unit 4SudarshanNo ratings yet
- Module Uvm Connect Session1 Introduction AericksonDocument27 pagesModule Uvm Connect Session1 Introduction AericksonsandraNo ratings yet
- Blood Donation CenterDocument11 pagesBlood Donation CenterDev HalvawalaNo ratings yet
- C++ Basics for Exit examDocument72 pagesC++ Basics for Exit exambuzelove773No ratings yet
- Lab4 PresentationDocument9 pagesLab4 PresentationGhassan RbeizNo ratings yet
- Programming Fundamentals Course Outline - 2022-2023Document3 pagesProgramming Fundamentals Course Outline - 2022-2023nhyirahayimNo ratings yet
- Angular JsDocument13 pagesAngular JsSanaullahNo ratings yet
- CS 212: Web Programming: Spring 2017 Course SyllabusDocument11 pagesCS 212: Web Programming: Spring 2017 Course Syllabusjames russell west brookNo ratings yet
- Data Engineering Roadmap For Freshers & ResourcesDocument6 pagesData Engineering Roadmap For Freshers & ResourcesPranjal BajpaiNo ratings yet
- The Swift Programming Language in French Ohxpr832Document27 pagesThe Swift Programming Language in French Ohxpr832Jean-Philippe BinderNo ratings yet