You might also like
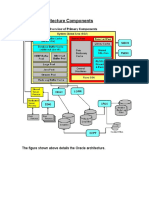
- Oracle ArchitectureDocument102 pagesOracle ArchitecturemanavalanmichaleNo ratings yet
- Postgresql AdminDocument89 pagesPostgresql Adminfrogman20xxNo ratings yet
- 2 Database ArchitectureDocument13 pages2 Database ArchitecturewaleedNo ratings yet
- Log MinerDocument22 pagesLog MinersundaravelrNo ratings yet
- What Is Dynamic SGADocument5 pagesWhat Is Dynamic SGANadiaNo ratings yet
- Oracle Database Oracle Instance + Data Files: AsktomDocument5 pagesOracle Database Oracle Instance + Data Files: Asktomvaloo_phoolNo ratings yet
- Technical Rockwell Automation FactoryTalk ViewSEDocument6 pagesTechnical Rockwell Automation FactoryTalk ViewSEamiguitoNo ratings yet
- Data Gaurd 10 GsheetDocument10 pagesData Gaurd 10 GsheetJonJonNo ratings yet
- Oracle Instance ArchitectureDocument28 pagesOracle Instance ArchitecturemonsonNo ratings yet
- MS SQL Server Architecture: Febriliyan SamopaDocument27 pagesMS SQL Server Architecture: Febriliyan SamopaPramuditha Muhammad IkhwanNo ratings yet
- DB LOB Sizing v54Document17 pagesDB LOB Sizing v54Jebabalanmari JebabalanNo ratings yet
- MMM MM M M MMMM M MMMMMMMMMMMMMMM M MM MMMMMMMMM MMMMMMMMMMMDocument10 pagesMMM MM M M MMMM M MMMMMMMMMMMMMMM M MM MMMMMMMMM MMMMMMMMMMMLokesh ChinniNo ratings yet
- Ops$Sapservice) With Very Few PrivilegesDocument5 pagesOps$Sapservice) With Very Few PrivilegesMarri MahipalNo ratings yet
- Oracle Enterprise Manager Database Control Is The Primary Tool For Managing Your Oracle Database. ItDocument7 pagesOracle Enterprise Manager Database Control Is The Primary Tool For Managing Your Oracle Database. ItTran Quoc DungNo ratings yet
- Understanding Scaling: Scaling Deployments of Oracle BI Enterprise EditionDocument4 pagesUnderstanding Scaling: Scaling Deployments of Oracle BI Enterprise EditionAsad HussainNo ratings yet
- Oracle DBA ArchitectureDocument17 pagesOracle DBA ArchitectureDiwakar Reddy SNo ratings yet
- Introduction To CMIS 565 - Module 0Document9 pagesIntroduction To CMIS 565 - Module 0kamakom78No ratings yet
- Module 1 - Oracle Architecture: ObjectivesDocument41 pagesModule 1 - Oracle Architecture: ObjectivesNavneet SainiNo ratings yet
- BR ToolsDocument8 pagesBR ToolsSurya NandaNo ratings yet
- oRACLE NotesDocument15 pagesoRACLE NotesCarla MissionaNo ratings yet
- Basic and Important Oracle Views VDocument31 pagesBasic and Important Oracle Views VSumit K100% (1)
- Oracle10g Introduction1eryk 130405011929 Phpapp02Document34 pagesOracle10g Introduction1eryk 130405011929 Phpapp02Sonali SinghNo ratings yet
- Database Architecture Oracle DbaDocument41 pagesDatabase Architecture Oracle DbaImran ShaikhNo ratings yet
- Pega 8.8 FeaturesDocument11 pagesPega 8.8 FeaturesRavi VarmaNo ratings yet
- ITSGHD190209 - Open Text Archive Server Installation With SQL DatabaseDocument27 pagesITSGHD190209 - Open Text Archive Server Installation With SQL Databasesuman nalbolaNo ratings yet
- Maa GG Performance 1969630Document51 pagesMaa GG Performance 1969630sjkhappsNo ratings yet
- In Oracle MilieuDocument6 pagesIn Oracle MilieuzahirhussianNo ratings yet
- Tech RSView32Document9 pagesTech RSView32vikas1947No ratings yet
- 3 Oracle Architecture NotesDocument39 pages3 Oracle Architecture NotesPaul NikolaidisNo ratings yet
- Introduction To The Oracle Server: It Includes The FollowingDocument11 pagesIntroduction To The Oracle Server: It Includes The FollowingRishabh BhagatNo ratings yet
- Object Oriented - Interview Questions: What Is OOP?Document18 pagesObject Oriented - Interview Questions: What Is OOP?Sam RogerNo ratings yet
- Module 1 - Oracle ArchitectureDocument110 pagesModule 1 - Oracle ArchitectureKranthi KumarNo ratings yet
- Parser2.0 Documentation-1.0.0Document15 pagesParser2.0 Documentation-1.0.0jppoujadeNo ratings yet
- User Guide - Exchange Compliance Archiver AgentDocument178 pagesUser Guide - Exchange Compliance Archiver AgentRavi KanthNo ratings yet
- Chapter 1. Oracle Database ArchitectureDocument7 pagesChapter 1. Oracle Database ArchitectureAdryan AnghelNo ratings yet
- Oracle Express Installation GuildDocument47 pagesOracle Express Installation GuildHammad JoufarNo ratings yet
- 1 - Logstash BasicsDocument33 pages1 - Logstash BasicsAlok PalNo ratings yet
- Logstash V1.4.1getting StartedDocument9 pagesLogstash V1.4.1getting StartedAnonymous taUuBikNo ratings yet
- GDocument7 pagesGCyro BezerraNo ratings yet
- Tech RSView32Document7 pagesTech RSView32kallorindo scribNo ratings yet
- Module 1 - Oracle ArchitectureDocument33 pagesModule 1 - Oracle ArchitectureDivya SrinivasanNo ratings yet
- Database Administration (SQL Server)Document43 pagesDatabase Administration (SQL Server)Nayd-aYan ArevirNo ratings yet
- What Is RDBMS?: Primary KeyDocument28 pagesWhat Is RDBMS?: Primary Keyapi-27048744No ratings yet
- DBAI Les04 Rev1 1Document22 pagesDBAI Les04 Rev1 1guser97No ratings yet
- Esb New FeaturesDocument16 pagesEsb New Featurespuli_prasanna21No ratings yet
- Harder, Better, Faster, Stronger: Page Views CalendarDocument24 pagesHarder, Better, Faster, Stronger: Page Views CalendardineshkumarchNo ratings yet
- Elasticsearch, Logstash and KibanaDocument11 pagesElasticsearch, Logstash and KibanaSachin JainNo ratings yet
- Module 1 - Oracle ArchitectureDocument34 pagesModule 1 - Oracle ArchitecturePratik Gandhi100% (2)
- Oracle DBA Fundamental 1 Exam Questions and Answers: Buffer Cache Redo Log in TheDocument17 pagesOracle DBA Fundamental 1 Exam Questions and Answers: Buffer Cache Redo Log in Theutagore58No ratings yet
- Optimizing SQL Server 2014: Course: Database Administration Effective Period: September 2015Document52 pagesOptimizing SQL Server 2014: Course: Database Administration Effective Period: September 2015Venus DhammikoNo ratings yet
- XML PublisherDocument61 pagesXML Publisheraadersh2006No ratings yet
- An Overview of Logical Replication in PostgreSQLDocument11 pagesAn Overview of Logical Replication in PostgreSQLStephen EfangeNo ratings yet
- Research Paper On Oracle DatabaseDocument4 pagesResearch Paper On Oracle Databaseqptwukrif100% (1)
- ORACLE ClassDocument26 pagesORACLE Classssv pNo ratings yet
- MICROSOFT AZURE ADMINISTRATOR EXAM PREP(AZ-104) Part-3: AZ 104 EXAM STUDY GUIDEFrom EverandMICROSOFT AZURE ADMINISTRATOR EXAM PREP(AZ-104) Part-3: AZ 104 EXAM STUDY GUIDENo ratings yet
- Mastering TypoScript: TYPO3 Website, Template, and Extension DevelopmentFrom EverandMastering TypoScript: TYPO3 Website, Template, and Extension DevelopmentNo ratings yet
- Oracle Database Administration Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesFrom EverandOracle Database Administration Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesRating: 5 out of 5 stars5/5 (1)
- Modules English Computer ScienceDocument11 pagesModules English Computer Scienceabelteshe_340263389No ratings yet
- PROC MEANS Freq Corr Regression AnnovaDocument60 pagesPROC MEANS Freq Corr Regression AnnovaS SreenivasuluNo ratings yet
- Best 8 Free Data Loss Prevention (DLP) Software Picks in 2021 G2Document2 pagesBest 8 Free Data Loss Prevention (DLP) Software Picks in 2021 G2rakotoarivelo tokyNo ratings yet
- Analyzing Time Rule Processing Details: Oracle Fusion Time and LaborDocument14 pagesAnalyzing Time Rule Processing Details: Oracle Fusion Time and Laborjagadeesh_933015121No ratings yet
- Blockchain-Based Chain of Custody Evidence Management System For Digital Forensic InvestigationsDocument6 pagesBlockchain-Based Chain of Custody Evidence Management System For Digital Forensic InvestigationsDinethra HewageNo ratings yet
- 9 JVMDocument57 pages9 JVMan.nguyenhoang2003No ratings yet
- Computer Graphics Notes - TutorialsDuniyaDocument188 pagesComputer Graphics Notes - TutorialsDuniyakavitadagar100% (1)
- T5L TA AIoT LCM Platform Instruction Screen Development GuideDocument54 pagesT5L TA AIoT LCM Platform Instruction Screen Development GuideZillaIllozNo ratings yet
- Tableau Desktop Professional BookDocument101 pagesTableau Desktop Professional Booksachin rawat100% (1)
- InVision V3.5 User Guide V1.0 July 2010Document331 pagesInVision V3.5 User Guide V1.0 July 2010Javier Matias Ruz MaluendaNo ratings yet
- Micro Project: Dr. D. Y. Patil School of Engineering (Second Shift Polytechnic)Document9 pagesMicro Project: Dr. D. Y. Patil School of Engineering (Second Shift Polytechnic)Vedant GadeNo ratings yet
- Ionlake SOC2 Type2Document36 pagesIonlake SOC2 Type2daniel koberssi100% (1)
- Wells Fargo Pitch DeckDocument20 pagesWells Fargo Pitch DeckKamesh PeriNo ratings yet
- Flink - BasicsDocument15 pagesFlink - BasicsNeha KhatriNo ratings yet
- Word Bangla 1Document4 pagesWord Bangla 1Md. kamrul IslamNo ratings yet
- Very Large Instruction Word (VLIW) : - VLIW - Architectures and Scheduling Techniques (Ch. 3.5)Document35 pagesVery Large Instruction Word (VLIW) : - VLIW - Architectures and Scheduling Techniques (Ch. 3.5)Chengzi HuangNo ratings yet
- The Little Black Book Of: Header BiddingDocument18 pagesThe Little Black Book Of: Header BiddingVishakhaNo ratings yet
- LogDocument2 pagesLogCak MetNo ratings yet
- Ictp211 PrelimsDocument10 pagesIctp211 PrelimsparcongieselaNo ratings yet
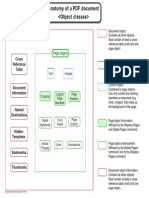
- PDF Anatomy 101Document1 pagePDF Anatomy 101timtoyNo ratings yet
- Data Structures Algorithms and Applications in C by Sartraj SahaniDocument826 pagesData Structures Algorithms and Applications in C by Sartraj SahaniMohammed Nassf100% (1)
- Multimediyna Prezentatsiya Z Angliyskoyi Movi Dlya 11 Klasu Na Temu Komunikatsiyni TehnologiyiDocument25 pagesMultimediyna Prezentatsiya Z Angliyskoyi Movi Dlya 11 Klasu Na Temu Komunikatsiyni TehnologiyiTank goldNo ratings yet
- SAP Training - ALE-LSMW (Idocs)Document42 pagesSAP Training - ALE-LSMW (Idocs)kimhoang_16927574No ratings yet
- Problem Statement: Student Result Management SystemDocument2 pagesProblem Statement: Student Result Management SystemramshyamNo ratings yet
- Project DashboardDocument2 pagesProject DashboardRamesh RadhakrishnarajaNo ratings yet
- Quarryman Viewer: Software ManualDocument80 pagesQuarryman Viewer: Software ManualJaime Hector Rojas ContrerasNo ratings yet
- Oracle.1z0-071.v2020-01-19.q80: Leave A ReplyDocument42 pagesOracle.1z0-071.v2020-01-19.q80: Leave A Replyidyllic chaosNo ratings yet
- Ni Wayan Yashinta DDocument6 pagesNi Wayan Yashinta DrojoNo ratings yet
- API Manager 170 PDFDocument318 pagesAPI Manager 170 PDFSuresh KumarNo ratings yet
- Prepaway Az 900 Microsoft Azure Fundamentals Version 12.0 With AnswerDocument172 pagesPrepaway Az 900 Microsoft Azure Fundamentals Version 12.0 With Answermatija904No ratings yet