You might also like
- College of Agricultural Biotechnology: (Plant Tissue Culture)Document74 pagesCollege of Agricultural Biotechnology: (Plant Tissue Culture)PAWANKUMAR S. K.No ratings yet
- Sequence Alignment Methods and AlgorithmsDocument37 pagesSequence Alignment Methods and Algorithmsapi-374725475% (4)
- Introduction To MS EXCELDocument91 pagesIntroduction To MS EXCELDfaid NGNo ratings yet
- Sequence Similarity Searching: Basic Local Alignment Search ToolDocument47 pagesSequence Similarity Searching: Basic Local Alignment Search ToolshooberNo ratings yet
- Substitution MatrixDocument10 pagesSubstitution MatrixRashmi DhimanNo ratings yet
- Dna SupercoilingDocument16 pagesDna SupercoilingrainabtNo ratings yet
- Protein FoldingDocument21 pagesProtein FoldingRONAK LASHKARINo ratings yet
- Crispr Cas HajarDocument21 pagesCrispr Cas HajarHajira Fatima100% (1)
- Bi 341 Chapter 1 The Genetic Code of Genes and Genomes & Introduction - KBDocument76 pagesBi 341 Chapter 1 The Genetic Code of Genes and Genomes & Introduction - KBMATHIXNo ratings yet
- RFLPDocument1 pageRFLPachin47No ratings yet
- X-Ray Crystallography: Kalyan DasDocument31 pagesX-Ray Crystallography: Kalyan DasAlexandru Bogdan TironNo ratings yet
- Protein PredictionDocument100 pagesProtein Predictionvani_darlingNo ratings yet
- Lecture Sanger SeqDocument22 pagesLecture Sanger SeqDaima SheikhNo ratings yet
- Allele Frequencies in A Population: G.H. Hardy Dr. Wilhelm WeinbergDocument9 pagesAllele Frequencies in A Population: G.H. Hardy Dr. Wilhelm WeinbergArchie Abella VillavicencioNo ratings yet
- MAT500 Paper PhylogeneticsDocument19 pagesMAT500 Paper PhylogeneticsScottMcRaeNo ratings yet
- Directed Mutagenesis and Protein EngineeringDocument52 pagesDirected Mutagenesis and Protein Engineeringslowdragon2003No ratings yet
- Plant Molecular Farming For Recombinant Therapeutic ProteinsDocument61 pagesPlant Molecular Farming For Recombinant Therapeutic Proteinsnitin_star2010No ratings yet
- Group # 13Document49 pagesGroup # 13maheen fatimaNo ratings yet
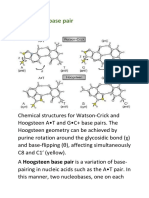
- Hoogsteen Base Pair PDFDocument7 pagesHoogsteen Base Pair PDFNikitaNo ratings yet
- ElectrophoresisDocument45 pagesElectrophoresisPagla HowaNo ratings yet
- NepheloturbidometryDocument6 pagesNepheloturbidometryzaife khanNo ratings yet
- Protein Immunoblotting: (Western Blotting)Document19 pagesProtein Immunoblotting: (Western Blotting)NANDA AHSANINo ratings yet
- Eukaryotic TranscriptionDocument16 pagesEukaryotic TranscriptionKunal DuttaNo ratings yet
- R DNA TchnologyDocument32 pagesR DNA TchnologyReena GuptaNo ratings yet
- Genome Organization in ProkaryoteDocument21 pagesGenome Organization in ProkaryotegitaNo ratings yet
- Ch-Immobilization of Enzyme PDFDocument92 pagesCh-Immobilization of Enzyme PDFVNo ratings yet
- A Review of Methods For The Detection of Pathogenic MicroorganismsDocument16 pagesA Review of Methods For The Detection of Pathogenic MicroorganismsLuisNo ratings yet
- PolarimetryDocument9 pagesPolarimetryAshaq HussainNo ratings yet
- Biosensors RPCDocument72 pagesBiosensors RPCSajjad Hossain ShuvoNo ratings yet
- Eukaryotic Expression SystemsDocument26 pagesEukaryotic Expression SystemsDeana NamirembeNo ratings yet
- SPECTROSCOPY - Docx Senthil - Docx 1......Document17 pagesSPECTROSCOPY - Docx Senthil - Docx 1......Zaidh. fd100% (1)
- Yac Bac PacDocument30 pagesYac Bac PacRahmama100% (1)
- Is - Innate ImmunityDocument11 pagesIs - Innate ImmunityOrhan AsdfghjklNo ratings yet
- II. Cot AnalysisDocument32 pagesII. Cot AnalysisSuraj BhattaraiNo ratings yet
- Nano Material Synthesis Techniques Top-Down and Bottom-Up Nanofabrication, Synthesis ofDocument6 pagesNano Material Synthesis Techniques Top-Down and Bottom-Up Nanofabrication, Synthesis ofsanthoshNo ratings yet
- Molecular CloningDocument61 pagesMolecular CloningDavi DzikirianNo ratings yet
- 2.3 Biogeochemical CycleDocument31 pages2.3 Biogeochemical CyclePAVITRA A/P THEVINDRAN MoeNo ratings yet
- Detection of Nucleic AcidDocument13 pagesDetection of Nucleic AcidAfrah AlatasNo ratings yet
- Spectrophotometry. Principle and ApplicationsDocument11 pagesSpectrophotometry. Principle and Applicationsmdusman2010No ratings yet
- Mechanism of Protein Targeting Into Endoplasmic ReticulumDocument24 pagesMechanism of Protein Targeting Into Endoplasmic ReticulumRebati Raman PandaNo ratings yet
- Rna EditingDocument31 pagesRna EditingAarthi VijayNo ratings yet
- Gene PredictionDocument50 pagesGene Predictionsaeedahmad901No ratings yet
- TransductionDocument14 pagesTransductionArchana RakibeNo ratings yet
- Submitted by Aiswarya V 1St MSC Zoology Roll Number 3301Document32 pagesSubmitted by Aiswarya V 1St MSC Zoology Roll Number 3301PES PEOPLENo ratings yet
- PPTDocument21 pagesPPTaqsamazin100% (1)
- S1 2021 - Restriction Enzyme Pract 2 - V1 - WorksheetDocument6 pagesS1 2021 - Restriction Enzyme Pract 2 - V1 - WorksheetLloaana 12No ratings yet
- Preclass Quiz 8 - Fa19 - MOLECULAR BIOLOGY (47940) PDFDocument3 pagesPreclass Quiz 8 - Fa19 - MOLECULAR BIOLOGY (47940) PDFElizabeth DouglasNo ratings yet
- ExtremophilesDocument3 pagesExtremophilesharrisonNo ratings yet
- Plant Biochemistry Module FinalDocument26 pagesPlant Biochemistry Module FinalHina RaufNo ratings yet
- Dosimetry: Film Badge DosimetersDocument3 pagesDosimetry: Film Badge DosimetersmahaNo ratings yet
- Cell Adhesion MoleculesDocument14 pagesCell Adhesion MoleculesSecret Agent100% (1)
- Cytoskeleton DADocument35 pagesCytoskeleton DAAnonymous NVBCqKWHNo ratings yet
- Laboratory Diagnosis of Parasitic DiseasesDocument57 pagesLaboratory Diagnosis of Parasitic DiseasesAmanuel MaruNo ratings yet
- Membrane Models: Gorter and Grendel's Membrane Theory (1920)Document5 pagesMembrane Models: Gorter and Grendel's Membrane Theory (1920)Hafiz AhmadNo ratings yet
- Utation: Big PictureDocument2 pagesUtation: Big PicturehomamunfatNo ratings yet
- Biological Ions and Oxid PhospDocument67 pagesBiological Ions and Oxid PhospRamesh KetaNo ratings yet
- Enzyme AssaysDocument3 pagesEnzyme AssaysAudreySlitNo ratings yet
- BIOLOGY Concept Booster MCQ Sheet - 20 PDFDocument13 pagesBIOLOGY Concept Booster MCQ Sheet - 20 PDFBiomentorNo ratings yet
- The Plasma Proteins V5: Structure, Function, and Genetic ControlFrom EverandThe Plasma Proteins V5: Structure, Function, and Genetic ControlFrank PutnamRating: 3 out of 5 stars3/5 (1)
- The Pyridine Nucleotide CoenzymesFrom EverandThe Pyridine Nucleotide CoenzymesJohannes EverseNo ratings yet
- 16 - Urinary System Anatomy and PhysiologyDocument58 pages16 - Urinary System Anatomy and PhysiologyNickson OnchokaNo ratings yet
- 17a - Male Reproductive System - Anatomy & PhysiologyDocument36 pages17a - Male Reproductive System - Anatomy & PhysiologyNickson OnchokaNo ratings yet
- 15b - Digestive System Anatomy and Physiology SeriesDocument100 pages15b - Digestive System Anatomy and Physiology SeriesNickson OnchokaNo ratings yet
- 17b - Female Reproductive System - Anatomy and PhysiologyDocument35 pages17b - Female Reproductive System - Anatomy and PhysiologyNickson OnchokaNo ratings yet
- Anterior Triangles of The NeckDocument5 pagesAnterior Triangles of The NeckNickson OnchokaNo ratings yet
- 11 - Cardiovascular Series of LecturesDocument161 pages11 - Cardiovascular Series of LecturesNickson OnchokaNo ratings yet
- 10 - The Endocrine SystemDocument56 pages10 - The Endocrine SystemNickson OnchokaNo ratings yet
- HBB 2116 Nucleotide DNA Biomolecule 8Document27 pagesHBB 2116 Nucleotide DNA Biomolecule 8Nickson OnchokaNo ratings yet
- 9 - Integument System Anatomy and PhysiologyDocument42 pages9 - Integument System Anatomy and PhysiologyNickson OnchokaNo ratings yet
- HBB 2116 Carbohydrates 2Document49 pagesHBB 2116 Carbohydrates 2Nickson OnchokaNo ratings yet
- HBB 2116 Carbohydrates 1Document40 pagesHBB 2116 Carbohydrates 1Nickson OnchokaNo ratings yet
- Multiple Sequence Alignment Black and WhiteDocument2 pagesMultiple Sequence Alignment Black and WhiteNickson OnchokaNo ratings yet