You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5814)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1092)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (844)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (348)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- 繁體 認字咭(973個) PDFDocument28 pages繁體 認字咭(973個) PDFgeneup358775% (4)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Norton and Matsumoto IntroductionDocument19 pagesNorton and Matsumoto Introductiongeneup3587No ratings yet
- Pierre Boulez and Olivier Messiaen's Harmony ClassDocument36 pagesPierre Boulez and Olivier Messiaen's Harmony Classgeneup3587100% (4)
- Islamic Culture in Hong Kong FINAL ONLINEDocument6 pagesIslamic Culture in Hong Kong FINAL ONLINEgeneup3587No ratings yet
- Panel C Music Composition Sounding - Truths - RedactedDocument8 pagesPanel C Music Composition Sounding - Truths - Redactedgeneup3587No ratings yet
- PRiM 2022 OnlineDocument24 pagesPRiM 2022 Onlinegeneup3587No ratings yet
- BagagesuDocument33 pagesBagagesugeneup3587No ratings yet
- In Arabic - Sami Shawa Music TheoryDocument194 pagesIn Arabic - Sami Shawa Music Theorygeneup3587No ratings yet
- Afropop Worldwide - Michael Frishkopf and Kristina Nelson On Koranic RecitationDocument28 pagesAfropop Worldwide - Michael Frishkopf and Kristina Nelson On Koranic Recitationgeneup3587No ratings yet
- Tibetan Contemporary Song and Music Video - Focus and Direction 2000-2009Document19 pagesTibetan Contemporary Song and Music Video - Focus and Direction 2000-2009geneup3587No ratings yet
- Panel C Musicology Selling - Song - RedactedDocument8 pagesPanel C Musicology Selling - Song - Redactedgeneup3587No ratings yet
- Printable Version - The Soviet Nationality Policy in Central Asia - Student PulseDocument3 pagesPrintable Version - The Soviet Nationality Policy in Central Asia - Student Pulsegeneup3587No ratings yet
- Uzbek OriginalDocument225 pagesUzbek Originalgeneup3587No ratings yet
- Professionalism in The Musical TraditionDocument30 pagesProfessionalism in The Musical Traditiongeneup3587No ratings yet
- Iranian Classical Music, Orientalism and Techniques of Contemporary Composition - Soosan LolavarDocument29 pagesIranian Classical Music, Orientalism and Techniques of Contemporary Composition - Soosan Lolavargeneup3587No ratings yet
- Musical Rhythm, Linguistic Rhythm, and Human EvolutionDocument7 pagesMusical Rhythm, Linguistic Rhythm, and Human Evolutiongeneup3587100% (1)
- Empowering Music Educators Through Professional Development and Expert AdviceDocument2 pagesEmpowering Music Educators Through Professional Development and Expert Advicegeneup3587No ratings yet
- Ethnomusicology at The University of AberdeenDocument3 pagesEthnomusicology at The University of Aberdeengeneup3587No ratings yet
- Working Paper - Mahalla - Gerda Henkel FoundationDocument135 pagesWorking Paper - Mahalla - Gerda Henkel Foundationgeneup3587No ratings yet
- Tulip in The Culture of Uzbek PeopleDocument11 pagesTulip in The Culture of Uzbek Peoplegeneup3587No ratings yet
- ICTM Maqam Study Group 6th Conference PDFDocument460 pagesICTM Maqam Study Group 6th Conference PDFgeneup3587No ratings yet
- National Specifies of Speech Etiquette: Abstract: Communication Is The Daily Necessity of Human's LifeDocument5 pagesNational Specifies of Speech Etiquette: Abstract: Communication Is The Daily Necessity of Human's Lifegeneup3587No ratings yet
- Volltext PDFDocument43 pagesVolltext PDFgeneup3587No ratings yet
- Leçon de Musique Avec Nadia BoulangerDocument4 pagesLeçon de Musique Avec Nadia Boulangergeneup3587100% (1)
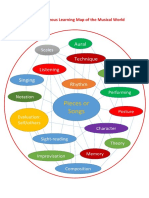
- Pieces or Songs: Aural Technique ListeningDocument1 pagePieces or Songs: Aural Technique Listeninggeneup3587No ratings yet
- Revival of Sufi Traditions in Modern Central Asia - "Jahri Zikr" and Its Ethnological FeaturesDocument14 pagesRevival of Sufi Traditions in Modern Central Asia - "Jahri Zikr" and Its Ethnological Featuresgeneup3587No ratings yet