
You might also like
- Heterogeneous Linguistic Data-Generic XML-based Representation and Flexible Visualization-2005Document5 pagesHeterogeneous Linguistic Data-Generic XML-based Representation and Flexible Visualization-2005driss ouNo ratings yet
- An Approach For Interconnecting Lexical ResourcesDocument6 pagesAn Approach For Interconnecting Lexical ResourcesAndrei ScutelnicuNo ratings yet
- Information Theoretical Complexities in Developing A Bilingual Corpus: Critical Comparison Hindi and MarathiDocument18 pagesInformation Theoretical Complexities in Developing A Bilingual Corpus: Critical Comparison Hindi and MarathiSyahiduzZamanNo ratings yet
- OASIcs LDK 2021 40Document15 pagesOASIcs LDK 2021 40Aditiya UmarNo ratings yet
- Applying Language Technology in Humanities Researc... - (2.4 Corpus and Natural Language Processing Tools)Document11 pagesApplying Language Technology in Humanities Researc... - (2.4 Corpus and Natural Language Processing Tools)Luyi ZhangNo ratings yet
- The Roots Search Tool: Data Transparency For LlmsDocument11 pagesThe Roots Search Tool: Data Transparency For LlmsbilletonNo ratings yet
- Linked Data For Language-Learning ApplicationsDocument8 pagesLinked Data For Language-Learning ApplicationsmodelthroughitNo ratings yet
- IDE As Code: Reifying Language Protocols As First-Class CitizensDocument6 pagesIDE As Code: Reifying Language Protocols As First-Class CitizensiTiSWRiTTENNo ratings yet
- Practical Translation-II: Lecture: 9 & 10 Building Corpora in Translation StudiesDocument25 pagesPractical Translation-II: Lecture: 9 & 10 Building Corpora in Translation StudiesNosheen IrshadNo ratings yet
- Getting To The Core of Terminological ProjectDocument7 pagesGetting To The Core of Terminological ProjectJuliaNo ratings yet
- Unit 2Document20 pagesUnit 2mailtoogiri_99636507No ratings yet
- An Effective Bi-LSTM Word Embedding System For Analysis and Identification of Language in Code-Mixed Social Media Text in English and Roman HindiDocument13 pagesAn Effective Bi-LSTM Word Embedding System For Analysis and Identification of Language in Code-Mixed Social Media Text in English and Roman HindiBig DaddyNo ratings yet
- 508-Article Text-508-1-10-20080128Document23 pages508-Article Text-508-1-10-20080128kimtinh18012005No ratings yet
- Seven Dimensions of Portability For Language Documentation and DescriptionDocument26 pagesSeven Dimensions of Portability For Language Documentation and DescriptionArul DayanandNo ratings yet
- LDL Nexus Task 1.1 PresentationDocument31 pagesLDL Nexus Task 1.1 PresentationAnas Fahad KhanNo ratings yet
- Semantic WebDocument19 pagesSemantic WebAvisek ChaudhuriNo ratings yet
- AComprehensive Semantic Web SurveyDocument24 pagesAComprehensive Semantic Web SurveyKurdeen KhairyNo ratings yet
- IR Chap3Document45 pagesIR Chap3biniam teshomeNo ratings yet
- Designing Monolingual Sample CorpusDocument19 pagesDesigning Monolingual Sample CorpusramlohaniNo ratings yet
- Chapter1-Overview of Database ConceptsDocument19 pagesChapter1-Overview of Database ConceptsHelen BeleteNo ratings yet
- Knight 2011 A Future of Mulimodal CorpusDocument25 pagesKnight 2011 A Future of Mulimodal CorpusirinaNo ratings yet
- Instructional Module and Its Components: Course Developer and Their BackgroundDocument45 pagesInstructional Module and Its Components: Course Developer and Their Backgroundondoy tvNo ratings yet
- Introducing Various Semantic Models For Amharic ExDocument18 pagesIntroducing Various Semantic Models For Amharic ExGetnete degemuNo ratings yet
- Standards For Language Resources: Nancy Ide, Laurent RomaryDocument7 pagesStandards For Language Resources: Nancy Ide, Laurent Romarymnbvfgtr5432plkjihyuuytyrerNo ratings yet
- Language Lexicons For Hindi-English Multilingual Text ProcessingDocument8 pagesLanguage Lexicons For Hindi-English Multilingual Text ProcessingIAES IJAINo ratings yet
- Documents: Language and Property.Document147 pagesDocuments: Language and Property.Abc DefNo ratings yet
- Towards Creating Precision Grammars From Interlinear Glossed Text: Inferring Large-Scale Typological PropertiesDocument10 pagesTowards Creating Precision Grammars From Interlinear Glossed Text: Inferring Large-Scale Typological PropertiesBengt HörbergNo ratings yet
- Rebertsubmission116 NWDocument26 pagesRebertsubmission116 NWsheepriyanka322No ratings yet
- Ontology EtourismDocument34 pagesOntology EtourismTri NguyenNo ratings yet
- Comments Mining With TF-IDF: The Inherent Bias and Its RemovalDocument14 pagesComments Mining With TF-IDF: The Inherent Bias and Its RemovalshitalNo ratings yet
- Beyond 512 Tokens: Siamese Multi-Depth Transformer-Based Hierarchical Encoder For Long-Form Document MatchingDocument10 pagesBeyond 512 Tokens: Siamese Multi-Depth Transformer-Based Hierarchical Encoder For Long-Form Document MatchingJohn PhamvanNo ratings yet
- Sanskrit With Lexical Analysis - Uploaded by ImranDocument7 pagesSanskrit With Lexical Analysis - Uploaded by Imranabhishek4u87No ratings yet
- A Guide To The Basic Logic Dialect For Rule Interchange On The WebDocument16 pagesA Guide To The Basic Logic Dialect For Rule Interchange On The WebSriram SitharamanNo ratings yet
- Knowledge Organization Innovation: Design and FrameworksDocument6 pagesKnowledge Organization Innovation: Design and FrameworksKevin MartinNo ratings yet
- Eai 13-7-2018 159623Document16 pagesEai 13-7-2018 159623ksrrwrwNo ratings yet
- Classifying Domain-Specific Terms Using A DictionaryDocument9 pagesClassifying Domain-Specific Terms Using A DictionaryAbel AbebeNo ratings yet
- Terminology in The Age of Multilingual CorporaDocument23 pagesTerminology in The Age of Multilingual CorporaVascoSobreiroNo ratings yet
- An Online Punjabi Shahmukhi Lexical ResourceDocument7 pagesAn Online Punjabi Shahmukhi Lexical ResourceJameel AbbasiNo ratings yet
- 2019 Litta Et Al DeriMo Prague PaperDocument9 pages2019 Litta Et Al DeriMo Prague Papereleonora littaNo ratings yet
- Semantic Computing and Language Knowledge BasesDocument12 pagesSemantic Computing and Language Knowledge BasesAndi KazaniNo ratings yet
- A Large-Scale Systemic Functional Grammar of GreekDocument14 pagesA Large-Scale Systemic Functional Grammar of GreekdieuphuongNo ratings yet
- Terminology Registries For Knowledge Organization Systems: Functionality, Use, and AttributesDocument16 pagesTerminology Registries For Knowledge Organization Systems: Functionality, Use, and AttributesAna CarolNo ratings yet
- Thesis LLMsForDocVQADocument29 pagesThesis LLMsForDocVQAThrow AwayNo ratings yet
- Metadata StandardsDocument4 pagesMetadata StandardsJolina PardilloNo ratings yet
- Object Database: Neutrality DisputedDocument6 pagesObject Database: Neutrality DisputedSandeep BurmanNo ratings yet
- Corpus LinguisticsDocument25 pagesCorpus LinguisticsisabelprofeatalNo ratings yet
- Semantics-Aware Indexing of Geospatial Resources Based On Multilingual Thesauri: Methodology and Preliminary ResultsDocument22 pagesSemantics-Aware Indexing of Geospatial Resources Based On Multilingual Thesauri: Methodology and Preliminary ResultsJarbas Vidal-FilhoNo ratings yet
- Genres, Registers and Text TypesDocument37 pagesGenres, Registers and Text TypesGeorge TownNo ratings yet
- 14 OWL: A Description Logic Based Ontology Language For The Semantic WebDocument35 pages14 OWL: A Description Logic Based Ontology Language For The Semantic WebKamoKamoNo ratings yet
- Linguistic Data ManagementDocument36 pagesLinguistic Data ManagementAGUINALDO GOMES DE SOUZANo ratings yet
- MCDL: A Reduced But Extensible Multimedia Contents Description LanguageDocument15 pagesMCDL: A Reduced But Extensible Multimedia Contents Description LanguageDeiu AndiNo ratings yet
- Digital Dictionary A Physical Realizatio PDFDocument5 pagesDigital Dictionary A Physical Realizatio PDFJenny Orpilla-MateoNo ratings yet
- Neologism: Easy Vocabulary PublishingDocument6 pagesNeologism: Easy Vocabulary PublishingHaq NasNo ratings yet
- COS4840 Oncology Assignment1Document5 pagesCOS4840 Oncology Assignment1ashllieghNo ratings yet
- Psychology and Marketing - 2023 - Pugliese - How To Conduct Efficient and Objective Literature Reviews Using NaturalDocument15 pagesPsychology and Marketing - 2023 - Pugliese - How To Conduct Efficient and Objective Literature Reviews Using Naturalkimtinh18012005No ratings yet
- I Cab CD 2019 Published Paper 33Document7 pagesI Cab CD 2019 Published Paper 33Yamine KliouiNo ratings yet
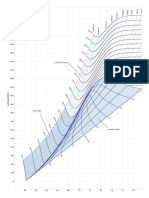
- Mollier Enthalpy Entropy Chart For Steam - US UnitsDocument1 pageMollier Enthalpy Entropy Chart For Steam - US Unitslin tongNo ratings yet
- A B C D: Choose Only One Answer For Each QuestionDocument10 pagesA B C D: Choose Only One Answer For Each QuestionAchitt AchitNo ratings yet
- Industrial Engineering KTU M TechDocument7 pagesIndustrial Engineering KTU M Techsreejan1111No ratings yet
- Nolte KitchenDocument44 pagesNolte KitchenGanesh SNo ratings yet
- Backup Olt CodigoDocument5 pagesBackup Olt CodigoCarlos GomezNo ratings yet
- Binary PDFDocument13 pagesBinary PDFbyprasadNo ratings yet
- Pelod Vs Sofa Scoring in PediatricDocument6 pagesPelod Vs Sofa Scoring in PediatricAdrian KhomanNo ratings yet
- LETRIST Locally Encoded Transform Feature HistograDocument16 pagesLETRIST Locally Encoded Transform Feature HistograHARE KRISHNANo ratings yet
- Artikel Ilmiah Aulia Sekar Pramesti 181100006Document13 pagesArtikel Ilmiah Aulia Sekar Pramesti 181100006auliaNo ratings yet
- UNIT 14 - On-Screen DigitizingDocument6 pagesUNIT 14 - On-Screen DigitizingResti KharismaNo ratings yet
- SC431 Lecture No. 4 Economic Comparisons (Continued)Document51 pagesSC431 Lecture No. 4 Economic Comparisons (Continued)Joseph BaruhiyeNo ratings yet
- Practical - Magnetic - Design (Fill Factor) PDFDocument20 pagesPractical - Magnetic - Design (Fill Factor) PDFAhtasham ChaudhryNo ratings yet
- AtomDocument15 pagesAtomdewi murtasimaNo ratings yet
- Histograms - 2Document6 pagesHistograms - 2Sonia HalepotaNo ratings yet
- 5-Canal Irrigation SystemDocument23 pages5-Canal Irrigation Systemwajid malikNo ratings yet
- UMTS Optimization GuidelineDocument84 pagesUMTS Optimization GuidelineEvelio Sotolongo100% (3)
- 2010 Jan-01Document32 pages2010 Jan-01Shine PrabhakaranNo ratings yet
- LTE Rach ProcedureDocument4 pagesLTE Rach ProcedureDeepak JammyNo ratings yet
- Spesiikasi PerallatanDocument10 pagesSpesiikasi PerallatanRafi RaziqNo ratings yet
- List of Books s8 ElectiveDocument2 pagesList of Books s8 ElectivemaniNo ratings yet
- Assignment - 1 Introduction of Machines and Mechanisms: TheoryDocument23 pagesAssignment - 1 Introduction of Machines and Mechanisms: TheoryAman AmanNo ratings yet
- Geared Motors Power Distribution: V V V VDocument2 pagesGeared Motors Power Distribution: V V V VShamim Ahsan ParvezNo ratings yet
- Magnetic Field of A SolenoidDocument5 pagesMagnetic Field of A SolenoidKang Yuan ShingNo ratings yet
- Calculation Eurocode 2Document4 pagesCalculation Eurocode 2rammirisNo ratings yet
- Baulkham Hills 2012 2U Prelim Yearly & SolutionsDocument11 pagesBaulkham Hills 2012 2U Prelim Yearly & SolutionsYe ZhangNo ratings yet
- Soiling Rates of PV Modules vs. Thermopile PyranometersDocument3 pagesSoiling Rates of PV Modules vs. Thermopile PyranometersAbdul Mohid SheikhNo ratings yet
- Configuration A: Unloaded BJT Transistor AmplifiersDocument3 pagesConfiguration A: Unloaded BJT Transistor AmplifiersdasdNo ratings yet
- Rexx Programmers ReferenceDocument723 pagesRexx Programmers ReferenceAnonymous ET7GttT7No ratings yet
- ASUS U47A Repair GuideDocument5 pagesASUS U47A Repair GuideCarlos ZarateNo ratings yet
- Glpi Developer DocumentationDocument112 pagesGlpi Developer Documentationvictorlage7No ratings yet
- Dark Data: Why What You Don’t Know MattersFrom EverandDark Data: Why What You Don’t Know MattersRating: 4.5 out of 5 stars4.5/5 (3)
- Optimizing DAX: Improving DAX performance in Microsoft Power BI and Analysis ServicesFrom EverandOptimizing DAX: Improving DAX performance in Microsoft Power BI and Analysis ServicesNo ratings yet
- Blockchain Basics: A Non-Technical Introduction in 25 StepsFrom EverandBlockchain Basics: A Non-Technical Introduction in 25 StepsRating: 4.5 out of 5 stars4.5/5 (24)
- Grokking Algorithms: An illustrated guide for programmers and other curious peopleFrom EverandGrokking Algorithms: An illustrated guide for programmers and other curious peopleRating: 4 out of 5 stars4/5 (16)
- Fusion Strategy: How Real-Time Data and AI Will Power the Industrial FutureFrom EverandFusion Strategy: How Real-Time Data and AI Will Power the Industrial FutureNo ratings yet
- SQL QuickStart Guide: The Simplified Beginner's Guide to Managing, Analyzing, and Manipulating Data With SQLFrom EverandSQL QuickStart Guide: The Simplified Beginner's Guide to Managing, Analyzing, and Manipulating Data With SQLRating: 4.5 out of 5 stars4.5/5 (46)
- Agile Metrics in Action: How to measure and improve team performanceFrom EverandAgile Metrics in Action: How to measure and improve team performanceNo ratings yet
- Business Intelligence Strategy and Big Data Analytics: A General Management PerspectiveFrom EverandBusiness Intelligence Strategy and Big Data Analytics: A General Management PerspectiveRating: 5 out of 5 stars5/5 (5)
- The Future of Competitive Strategy: Unleashing the Power of Data and Digital Ecosystems (Management on the Cutting Edge)From EverandThe Future of Competitive Strategy: Unleashing the Power of Data and Digital Ecosystems (Management on the Cutting Edge)Rating: 5 out of 5 stars5/5 (1)
- Data Mining Techniques: For Marketing, Sales, and Customer Relationship ManagementFrom EverandData Mining Techniques: For Marketing, Sales, and Customer Relationship ManagementRating: 4 out of 5 stars4/5 (9)
- Data Smart: Using Data Science to Transform Information into InsightFrom EverandData Smart: Using Data Science to Transform Information into InsightRating: 4.5 out of 5 stars4.5/5 (23)
- Relational Database Design and ImplementationFrom EverandRelational Database Design and ImplementationRating: 4.5 out of 5 stars4.5/5 (5)
- Microsoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]From EverandMicrosoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]Rating: 5 out of 5 stars5/5 (8)













































































































![Microsoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]](https://imgv2-1-f.scribdassets.com/img/word_document/610686937/149x198/9ccfa6158e/1714467780?v=1)