You might also like
- Jeffrey Epstein39s Little Black Book Unredacted PDFDocument95 pagesJeffrey Epstein39s Little Black Book Unredacted PDFasdasdasd75% (4)
- MillionDollarPipsManual PDFDocument12 pagesMillionDollarPipsManual PDFOnes RoseNo ratings yet
- Risk Assessment For Tank 2Document4 pagesRisk Assessment For Tank 2Ace2201100% (1)
- Banking Management System 7030Document34 pagesBanking Management System 7030sanjaysingh meharaNo ratings yet
- Application Management ServicesDocument16 pagesApplication Management ServicesAnil ChityalNo ratings yet
- Determinants of Household Carbon Footprints: Alice T. Valerio, Renz S. MascardoDocument26 pagesDeterminants of Household Carbon Footprints: Alice T. Valerio, Renz S. MascardoBillyNo ratings yet
- Drones 05 00066 v3Document24 pagesDrones 05 00066 v3niwton3000No ratings yet
- Deep Learning Features at Scale For Visual Place RecognitionDocument8 pagesDeep Learning Features at Scale For Visual Place RecognitionbusuulwaerickNo ratings yet
- 2020 Relational NetworkDocument15 pages2020 Relational NetworksabrineNo ratings yet
- Bags of Binary Words For Fast Place Recognition in Image SequencesDocument9 pagesBags of Binary Words For Fast Place Recognition in Image SequencesbahiNo ratings yet
- Denoising and Fuel Spray Droplet Detection From Light Scattere - 2022 - Energy ADocument10 pagesDenoising and Fuel Spray Droplet Detection From Light Scattere - 2022 - Energy AQuang HưngNo ratings yet
- Remotesensing 13 04044 v2 CompressedDocument12 pagesRemotesensing 13 04044 v2 Compresseddarshanmythreya14No ratings yet
- Region-Based Convolutional Networks For Accurate Object Detection and SegmentationDocument21 pagesRegion-Based Convolutional Networks For Accurate Object Detection and SegmentationwdwdNo ratings yet
- Using Satellite Images To Determine AQI Values in CaliforniaDocument6 pagesUsing Satellite Images To Determine AQI Values in Californiaatharva deshpandeNo ratings yet
- Aerial Imagery Pixel-Level SegmentationDocument30 pagesAerial Imagery Pixel-Level SegmentationSuanny FabyneNo ratings yet
- The Graph Neural Network ModelDocument20 pagesThe Graph Neural Network ModelHet Bhavin PatelNo ratings yet
- Scheibenreif Self-Supervised Vision Transformers For Land-Cover Segmentation and Classification CVPRW 2022 PaperDocument10 pagesScheibenreif Self-Supervised Vision Transformers For Land-Cover Segmentation and Classification CVPRW 2022 PaperZakaria NgerejaNo ratings yet
- Deep-Learning Based SAR Ship Detection With Generative Data AugmentationDocument9 pagesDeep-Learning Based SAR Ship Detection With Generative Data AugmentationRana UsmanNo ratings yet
- Scaling Convex Optimisation For Radio AstronomyDocument11 pagesScaling Convex Optimisation For Radio AstronomySaheba ShaikNo ratings yet
- Improving Detection Capabilities of YOLOv8-n for SDocument10 pagesImproving Detection Capabilities of YOLOv8-n for S3BAdriana Anggita DaeliNo ratings yet
- Shannon and Fuzzy Entropy Based Evolutionary Image Thresholding For Image SegmentationDocument13 pagesShannon and Fuzzy Entropy Based Evolutionary Image Thresholding For Image SegmentationvijayakumareliteNo ratings yet
- NeRF - NavigationDocument8 pagesNeRF - NavigationBach NguyenNo ratings yet
- Quantitative Comparison of Linear and Non-Linear Dimensionality Reduction Techniques For Solar Image ArchivesDocument6 pagesQuantitative Comparison of Linear and Non-Linear Dimensionality Reduction Techniques For Solar Image ArchivesOmega AlphaNo ratings yet
- Digital Signal Processing: Zuodong Yang, Yong Wu, Wenteng Zhao, Yicong Zhou, Zongqing Lu, Weifeng Li, Qingmin LiaoDocument7 pagesDigital Signal Processing: Zuodong Yang, Yong Wu, Wenteng Zhao, Yicong Zhou, Zongqing Lu, Weifeng Li, Qingmin LiaoAbdelhalim BouallegNo ratings yet
- Semantic-Guided Feature Selection for Image CaptioningDocument10 pagesSemantic-Guided Feature Selection for Image CaptioningTomislav IvandicNo ratings yet
- Aguilera Learning Cross-Spectral Similarity CVPR 2016 PaperDocument9 pagesAguilera Learning Cross-Spectral Similarity CVPR 2016 Papercaxidas953No ratings yet
- A Comparative Analysis of GAN-Based Methods For SAR-To-Optical Image TranslationDocument5 pagesA Comparative Analysis of GAN-Based Methods For SAR-To-Optical Image TranslationMAHESWARI MNo ratings yet
- 6416 978-1-5386-7150-4/18/$31.00 ©2018 Ieee Igarss 2018Document4 pages6416 978-1-5386-7150-4/18/$31.00 ©2018 Ieee Igarss 2018Uppuluri Lalitha MadhuriNo ratings yet
- 1 s2.0 S266591742200071X MainDocument9 pages1 s2.0 S266591742200071X MainRamalakshmi KNo ratings yet
- Learning Bayesiano CsmriDocument13 pagesLearning Bayesiano CsmriEdward Ventura BarrientosNo ratings yet
- CCF-Net: A Cascade Center-Based Framework Towards E Cient Human Parts DetectionDocument13 pagesCCF-Net: A Cascade Center-Based Framework Towards E Cient Human Parts Detectionwang elleryNo ratings yet
- Zhong et al. - 2017 - Learning to Diversify Deep Belief Networks for Hyperspectral Image ClassificationDocument15 pagesZhong et al. - 2017 - Learning to Diversify Deep Belief Networks for Hyperspectral Image ClassificationEwerton DuarteNo ratings yet
- EM ML SurveyDocument4 pagesEM ML SurveysomedoodNo ratings yet
- Liu A Data-Centric Solution To NonHomogeneous Dehazing Via Vision Transformer CVPRW 2023 PaperDocument10 pagesLiu A Data-Centric Solution To NonHomogeneous Dehazing Via Vision Transformer CVPRW 2023 Paperlohithinfinite154No ratings yet
- Pattern Recognition: Xiaokai Liu, Weihao Ma, Xiaorui Ma, Jie WangDocument11 pagesPattern Recognition: Xiaokai Liu, Weihao Ma, Xiaorui Ma, Jie WangSameer AhmedNo ratings yet
- Place Recognition With ConvNet LandmarksDocument10 pagesPlace Recognition With ConvNet LandmarksGeorge PachitariuNo ratings yet
- Editorial: Introduction To The Special Issue On Innovative Applications of Computer VisionDocument2 pagesEditorial: Introduction To The Special Issue On Innovative Applications of Computer VisionasddsdsaNo ratings yet
- 1164818.IntelliSys FinalDocument15 pages1164818.IntelliSys FinalLYNN VILLACORTANo ratings yet
- 2 Marked PDFDocument4 pages2 Marked PDFMonisha djNo ratings yet
- ETH: A Framework For The Design-Space Exploration of Extreme-Scale Scientific VisualizationDocument10 pagesETH: A Framework For The Design-Space Exploration of Extreme-Scale Scientific VisualizationcjchienNo ratings yet
- Comparative Analysis of Deep Learning Image Detection AlgorithmsDocument27 pagesComparative Analysis of Deep Learning Image Detection AlgorithmsArin Cantika musiNo ratings yet
- S Patio Temporal Kernel RegressionDocument18 pagesS Patio Temporal Kernel Regressionsonalidhali157622No ratings yet
- Graph TtransferDocument9 pagesGraph TtransferNehaKarunyaNo ratings yet
- Road Detection from Aerial Imagery Using CNNsDocument8 pagesRoad Detection from Aerial Imagery Using CNNsJuan Fernandez IriarteNo ratings yet
- Optics Communications: Di Guo, Jingwen Yan, Xiaobo QuDocument7 pagesOptics Communications: Di Guo, Jingwen Yan, Xiaobo QuWafa BenzaouiNo ratings yet
- Duplicate Image Detection and Comparison Using Single Core, Multiprocessing, and MultithreadingDocument8 pagesDuplicate Image Detection and Comparison Using Single Core, Multiprocessing, and MultithreadingInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Structural Prior Driven Regularized Deep Learning For Sonar Image ClassificationDocument16 pagesStructural Prior Driven Regularized Deep Learning For Sonar Image ClassificationXn TangNo ratings yet
- Improving CBIR using wavelet-based feature extractionDocument8 pagesImproving CBIR using wavelet-based feature extractionCarolina WatanabeNo ratings yet
- S S: T A C N: Triving For Implicity HE LL Onvolutional ETDocument14 pagesS S: T A C N: Triving For Implicity HE LL Onvolutional ETKenny SNo ratings yet
- S S: T A C N: Triving For Implicity HE LL Onvolutional ETDocument14 pagesS S: T A C N: Triving For Implicity HE LL Onvolutional ETKenny SNo ratings yet
- An Efficient SVD-Based Method For Image DenoisingDocument13 pagesAn Efficient SVD-Based Method For Image Denoisingmohitgond170No ratings yet
- Orb SlamDocument17 pagesOrb SlamRenato SanabriaNo ratings yet
- Research Paper Zebra PoseDocument16 pagesResearch Paper Zebra PoseDivyam ShethNo ratings yet
- Model Transferability From ImageNet To Lithography HotspotDocument9 pagesModel Transferability From ImageNet To Lithography Hotspotameed shahNo ratings yet
- Pramono Hierarchical Self-Attention Network For Action Localization in Videos ICCV 2019 PaperDocument10 pagesPramono Hierarchical Self-Attention Network For Action Localization in Videos ICCV 2019 Papervishalk172No ratings yet
- MRM 27511Document46 pagesMRM 27511Ryu ReyhanNo ratings yet
- Yang2017 PDFDocument15 pagesYang2017 PDFpradeep BNo ratings yet
- Towards an Algebra for Lighting SimulationDocument9 pagesTowards an Algebra for Lighting Simulationluis_a_diago771No ratings yet
- Multidimensional Contrast Limited Adaptive Histogram EqualizationDocument11 pagesMultidimensional Contrast Limited Adaptive Histogram EqualizationAnooshdini2002No ratings yet
- Physics-Informed Neural Networks For Diffraction Tomography: Research ArticleDocument12 pagesPhysics-Informed Neural Networks For Diffraction Tomography: Research Articleasrar asimNo ratings yet
- Pattern Recognition: Fen Fang, Liyuan Li, Ying Gu, Hongyuan Zhu, Joo-Hwee LimDocument10 pagesPattern Recognition: Fen Fang, Liyuan Li, Ying Gu, Hongyuan Zhu, Joo-Hwee LimEdgar Enrique Vilca RomeroNo ratings yet
- Research 3rdsemDocument10 pagesResearch 3rdsemmuskan goyalNo ratings yet
- Pami09 CompressedDocument18 pagesPami09 CompressedlojzeNo ratings yet
- High-Speed Tracking With Kernelized Correlation FiltersDocument14 pagesHigh-Speed Tracking With Kernelized Correlation FiltersKha DijaNo ratings yet
- A Local Contrast Method For Small Infrared Target DetectionDocument8 pagesA Local Contrast Method For Small Infrared Target DetectionbinukirubaNo ratings yet
- File C Program Files ANSYS Inc v160 Aisol DesignSpace DDocument36 pagesFile C Program Files ANSYS Inc v160 Aisol DesignSpace DLuis Miguel NavarreteNo ratings yet
- rr321201 Multimedia and Web DesignDocument4 pagesrr321201 Multimedia and Web DesignSRINIVASA RAO GANTANo ratings yet
- Comparator Design Using Full Adder: July 2014Document5 pagesComparator Design Using Full Adder: July 2014John Mark Manalo RosalesNo ratings yet
- Analysis of Fatigue Life in Two Weld Class Systems: Master Thesis in Solid MechanicsDocument296 pagesAnalysis of Fatigue Life in Two Weld Class Systems: Master Thesis in Solid Mechanicsgoedel1000No ratings yet
- Soft Systems MethodologyDocument9 pagesSoft Systems MethodologyWellWisherNo ratings yet
- Monitor Panel Emergency Panel: Ap SeriesDocument1 pageMonitor Panel Emergency Panel: Ap SeriesRamtelNo ratings yet
- 2614Document24 pages2614ARULKUMARSUBRAMANIANNo ratings yet
- Itu Survey On Radio Spectrum Management 17-01-07 FinalDocument280 pagesItu Survey On Radio Spectrum Management 17-01-07 FinalĐại Gia Nam ĐịnhNo ratings yet
- E-Signedcontract 1102019Document12 pagesE-Signedcontract 1102019Apostolos LogothetisNo ratings yet
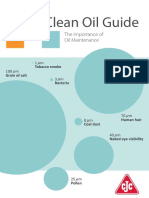
- Clean Oil GuideDocument48 pagesClean Oil GuideDarío CostasNo ratings yet
- What Is A SatelliteDocument2 pagesWhat Is A SatelliteTeferi LemmaNo ratings yet
- Intro to Data Comms & Computer NetworksDocument52 pagesIntro to Data Comms & Computer NetworksFerlyn Maye Angeles BenavidesNo ratings yet
- 014-Din en 1503 2001 001 Steels Specified in European StandardsDocument9 pages014-Din en 1503 2001 001 Steels Specified in European StandardsQuality MSIPLNo ratings yet
- IP Address Lab AnswersDocument3 pagesIP Address Lab Answersabdel2121No ratings yet
- Dynamic System Analysis Installation and User's Guide: IBM SystemsDocument62 pagesDynamic System Analysis Installation and User's Guide: IBM SystemsKamalkant YadavNo ratings yet
- Objective Question of RefineryDocument11 pagesObjective Question of Refineryvishal bailurNo ratings yet
- Aspen Hysys Surge Analysis Compressor DynamicsDocument4 pagesAspen Hysys Surge Analysis Compressor DynamicssalcedopozasNo ratings yet
- PPU UNIT 1 Part-1Document23 pagesPPU UNIT 1 Part-1VeeturiVarunNo ratings yet
- Pike Plan Report 2015Document236 pagesPike Plan Report 2015Daily FreemanNo ratings yet
- Batangas CATV Vs CADocument10 pagesBatangas CATV Vs CAMary Joyce Lacambra AquinoNo ratings yet
- Object-Oriented Design and High-Level Programming LanguagesDocument85 pagesObject-Oriented Design and High-Level Programming LanguagesctadventuresinghNo ratings yet
- S 85 625 2016WebSumDocument13 pagesS 85 625 2016WebSumGerson cuyaNo ratings yet
- Vodafone Case FinalDocument25 pagesVodafone Case FinalpavanbhatNo ratings yet
- Scientemp - CAL 9500P Programmable Process Controller User ManualDocument24 pagesScientemp - CAL 9500P Programmable Process Controller User ManualscientempNo ratings yet