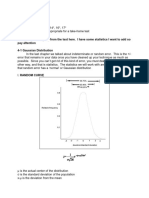
You might also like
- Chapter 3 - Describing Comparing DataDocument21 pagesChapter 3 - Describing Comparing DataPedro ChocoNo ratings yet
- Calculating Standard Error Bars For A GraphDocument6 pagesCalculating Standard Error Bars For A GraphKona MenyongaNo ratings yet
- Practical Engineering, Process, and Reliability StatisticsFrom EverandPractical Engineering, Process, and Reliability StatisticsNo ratings yet
- STATISTIC (Methodology)Document10 pagesSTATISTIC (Methodology)Eliya AiyaniNo ratings yet
- Assignment3 Ans 2015 PDFDocument11 pagesAssignment3 Ans 2015 PDFMohsen FragNo ratings yet
- Measurement of DispersionDocument4 pagesMeasurement of Dispersionoziyan alemnewNo ratings yet
- One and Two Way ANOVADocument11 pagesOne and Two Way ANOVADave MillingtonNo ratings yet
- Anova: Samprit ChakrabartiDocument30 pagesAnova: Samprit Chakrabarti42040No ratings yet
- AD3411 - 6 To11Document15 pagesAD3411 - 6 To11Raj kamalNo ratings yet
- CH 14 StatisticsDocument3 pagesCH 14 StatisticsKarthikeya R SNo ratings yet
- Research Methodology-Exam-2Document21 pagesResearch Methodology-Exam-2Tuyisenge TheonesteNo ratings yet
- BIOSTAT Chapter2Document57 pagesBIOSTAT Chapter2Rodin PaspasanNo ratings yet
- 2013 Trends in Global Employee Engagement ReportDocument8 pages2013 Trends in Global Employee Engagement ReportAnupam BhattacharyaNo ratings yet
- FINAL EXAM IN E-WPS OfficeDocument12 pagesFINAL EXAM IN E-WPS OfficeLorwel ReyesNo ratings yet
- Lab 3 - Kristi Proc UnivariateDocument10 pagesLab 3 - Kristi Proc UnivariateJacob SheridanNo ratings yet
- Measures of DispersionDocument26 pagesMeasures of DispersionDrAmit VermaNo ratings yet
- Standard DeviationDocument3 pagesStandard DeviationmirelaasmanNo ratings yet
- Measures of Variation, Quartiles and Percentiles, Skewness and KurtosisDocument16 pagesMeasures of Variation, Quartiles and Percentiles, Skewness and Kurtosis2200030218csehNo ratings yet
- 11-Anova For BRMDocument39 pages11-Anova For BRMabhdonNo ratings yet
- ASSIGNMEN4Document15 pagesASSIGNMEN4Harshita Sharma100% (1)
- New Lesson 2a - Measure of Central TendencyDocument12 pagesNew Lesson 2a - Measure of Central Tendencyjhean dabatosNo ratings yet
- SCI2010 - Week 4Document5 pagesSCI2010 - Week 4Luk Ee RenNo ratings yet
- Ix. Introduction To Statistical Concepts: Frequency Distribution Measures of Central Tendency Measures of VariabilityDocument119 pagesIx. Introduction To Statistical Concepts: Frequency Distribution Measures of Central Tendency Measures of VariabilityAppleRoseAgravanteNo ratings yet
- Statistics Notes Part 1Document26 pagesStatistics Notes Part 1Lukong LouisNo ratings yet
- Hypothesis Testing Walk ThroughDocument6 pagesHypothesis Testing Walk ThroughJAI AGGARWAL-DM 21DM249No ratings yet
- Chi SquareDocument15 pagesChi SquareYam SalemNo ratings yet
- Exercise CH 11Document10 pagesExercise CH 11Nurshuhada NordinNo ratings yet
- Data Analytics Notes From Unit 1 To 5 by DR Kapil ChaturvediDocument94 pagesData Analytics Notes From Unit 1 To 5 by DR Kapil ChaturvediAbdul Wasiq Khan100% (7)
- QM Statistic NotesDocument24 pagesQM Statistic NotesSalim Abdulrahim BafadhilNo ratings yet
- Measures of VariationDocument30 pagesMeasures of VariationJahbie ReyesNo ratings yet
- Stats ch9 PDFDocument16 pagesStats ch9 PDFSivagami SaminathanNo ratings yet
- KWT 4.ukuran Keragaman Data 2013Document29 pagesKWT 4.ukuran Keragaman Data 2013AndiNo ratings yet
- AnovaDocument55 pagesAnovaFiona Fernandes67% (3)
- AnovaDocument6 pagesAnovaHongYu HuiNo ratings yet
- Chapter 3 DispersionDocument12 pagesChapter 3 DispersionElan JohnsonNo ratings yet
- Chapter 4-1Document46 pagesChapter 4-1Shahzaib SalmanNo ratings yet
- Measures of Relative MotionDocument20 pagesMeasures of Relative MotionBam Bam0% (1)
- Business Statistics and Management Science NotesDocument74 pagesBusiness Statistics and Management Science Notes0pointsNo ratings yet
- Active Learning Task 8Document7 pagesActive Learning Task 8haptyNo ratings yet
- Math 114 Exam 3 ReviewDocument7 pagesMath 114 Exam 3 ReviewGenesa Buen A. PolintanNo ratings yet
- The Mann-Whitney U-Test - : Analysis of 2-Between-Group Data With A Quantitative Response VariableDocument4 pagesThe Mann-Whitney U-Test - : Analysis of 2-Between-Group Data With A Quantitative Response Variabletheone1989No ratings yet
- Case Study Report Tut 1 Group 4 Mrs. Hoai PhuongDocument22 pagesCase Study Report Tut 1 Group 4 Mrs. Hoai Phuong2004040009No ratings yet
- Module 03 AssignmentDocument13 pagesModule 03 Assignmentsuresh avadutha100% (1)
- Anova 123Document9 pagesAnova 123Yann YeuNo ratings yet
- Week 5 Worksheet AnswersDocument6 pagesWeek 5 Worksheet AnswersJennifer MooreNo ratings yet
- Chapter 4 StatisticsDocument11 pagesChapter 4 Statisticszaheer abbasNo ratings yet
- 2 Mean Median Mode VarianceDocument29 pages2 Mean Median Mode VarianceBonita Mdoda-ArmstrongNo ratings yet
- Research 8 Grade 8 Melc 1 q4 Week1Document26 pagesResearch 8 Grade 8 Melc 1 q4 Week1iancyrillvillamer10No ratings yet
- Estrellado Rommel E. - Activity 5Document11 pagesEstrellado Rommel E. - Activity 5CBME STRATEGIC MANAGEMENTNo ratings yet
- Mean, Median and Mode 1 PDFDocument16 pagesMean, Median and Mode 1 PDFMbalieZee0% (1)
- Q1) Calculate Skewness, Kurtosis & Draw Inferences On The Following Data A. Cars Speed and DistanceDocument15 pagesQ1) Calculate Skewness, Kurtosis & Draw Inferences On The Following Data A. Cars Speed and Distancekevin yongNo ratings yet
- Chapter 4 Describing Educational Data Libmanan GroupDocument31 pagesChapter 4 Describing Educational Data Libmanan Groupjoy borjaNo ratings yet
- ANOVA ExampleDocument6 pagesANOVA ExampleLuis ValensNo ratings yet
- 01 Sample Problems For Chapter 1 - ANSWER KEYDocument13 pages01 Sample Problems For Chapter 1 - ANSWER KEYArmaan VermaNo ratings yet
- Analysis of Varience-One Way Analysis (Original Slide)Document25 pagesAnalysis of Varience-One Way Analysis (Original Slide)Hilmi DahariNo ratings yet
- Lesson 5 Measure of Spread 1Document9 pagesLesson 5 Measure of Spread 1rahmanzainiNo ratings yet
- 2 - Chapter 1 - Measures of Central Tendency and Variation NewDocument18 pages2 - Chapter 1 - Measures of Central Tendency and Variation NewDmddldldldl100% (1)
- MS 08 - Solved AssignmentDocument13 pagesMS 08 - Solved AssignmentAdarsh Kalhia100% (1)
- Designing A Strategic Information Systems Planning Methodology For Malaysian Institutes of Higher Learning (Isp-Ipta)Document8 pagesDesigning A Strategic Information Systems Planning Methodology For Malaysian Institutes of Higher Learning (Isp-Ipta)Janet G.No ratings yet
- Econometrics Chapter OneDocument11 pagesEconometrics Chapter OneYafet WolansaNo ratings yet
- Two-Way Anova InteractionDocument9 pagesTwo-Way Anova InteractionImane ChatouiNo ratings yet
- UntitledDocument49 pagesUntitledKhanh Trương Lê MaiNo ratings yet
- Everyday Ethics: Ethical Issues and Stress in Nursing PracticeDocument10 pagesEveryday Ethics: Ethical Issues and Stress in Nursing PracticeSri RahmawatiNo ratings yet
- MComDocument32 pagesMComTuki DasNo ratings yet
- 11) Hillside Buildings in Northeast IndiaDocument13 pages11) Hillside Buildings in Northeast IndiaKausalya PurushothamanNo ratings yet
- MA S IV GuidenceDocument15 pagesMA S IV Guidencehanna khababNo ratings yet
- Session 4Document16 pagesSession 4Oanh To Thi TrucNo ratings yet
- CI and HT PDFDocument8 pagesCI and HT PDFshama vidyarthyNo ratings yet
- Research 2Document2 pagesResearch 2Kaela Beatrice Sy LatoNo ratings yet
- A Synopsis Submitted For The Degree ofDocument21 pagesA Synopsis Submitted For The Degree ofAakash KaushikNo ratings yet
- Rathus Assertive ModuleDocument2 pagesRathus Assertive ModuleRudianto Ahmad100% (1)
- Los Altos Historical CommissionDocument47 pagesLos Altos Historical CommissionnicholasdeleoncircaNo ratings yet
- MBA ProjectDocument45 pagesMBA ProjectKaushal AgrawalNo ratings yet
- ACTIVITATI DE Coaching Si MentoringDocument235 pagesACTIVITATI DE Coaching Si MentoringGILDA GODEANUNo ratings yet
- Chain Restaurant Patrons' Well Bring Percption and Dinning IntentionDocument28 pagesChain Restaurant Patrons' Well Bring Percption and Dinning IntentionshaziaNo ratings yet
- Cultural Factors That Affect The TechnicDocument7 pagesCultural Factors That Affect The TechnicmattrhaierNo ratings yet
- The Effect of Accounting Information Systems in Accounting: AbstractsDocument9 pagesThe Effect of Accounting Information Systems in Accounting: AbstractsRegina FlorenNo ratings yet
- Abdlle ThesisDocument47 pagesAbdlle ThesisBashiir GelleNo ratings yet
- Case Study LFLDocument6 pagesCase Study LFLPaul John Garcia RaciNo ratings yet
- Sub QueriesDocument3 pagesSub QueriesSubramaniam KalyanNo ratings yet
- Organizational Capacity AssessmentDocument4 pagesOrganizational Capacity AssessmentValerie F. LeonardNo ratings yet
- Self-Schema and Self-Discrepancy Mediate The Influence of InstagramDocument9 pagesSelf-Schema and Self-Discrepancy Mediate The Influence of InstagramBryan Gomez VasquezNo ratings yet
- Wzn5CtQBRSCM7bSREUUe 20201209 MassMin GeneralDocument90 pagesWzn5CtQBRSCM7bSREUUe 20201209 MassMin GeneralJuan MedinaNo ratings yet
- Trends in The Development of Higher Education in The Field of ServiceDocument10 pagesTrends in The Development of Higher Education in The Field of ServiceEboka favour chidinmaNo ratings yet
- 261 Lecture 18 Sensory Evaluation (White) 3-2-2011Document33 pages261 Lecture 18 Sensory Evaluation (White) 3-2-2011widianingsih100% (1)
- Evaluation of Capital Budgeting in Public Sector Organizations in NigeriaDocument54 pagesEvaluation of Capital Budgeting in Public Sector Organizations in NigeriaDaniel ObasiNo ratings yet
- Business Research 1Document98 pagesBusiness Research 1vansha_mehra1990No ratings yet
- Effective AVO Crossplot ModelingDocument12 pagesEffective AVO Crossplot ModelingroyNo ratings yet
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeFrom EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeRating: 4 out of 5 stars4/5 (2)
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsFrom EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsRating: 4.5 out of 5 stars4.5/5 (3)
- Mental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)From EverandMental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)No ratings yet
- Calculus Made Easy: Being a Very-Simplest Introduction to Those Beautiful Methods of Reckoning Which are Generally Called by the Terrifying Names of the Differential Calculus and the Integral CalculusFrom EverandCalculus Made Easy: Being a Very-Simplest Introduction to Those Beautiful Methods of Reckoning Which are Generally Called by the Terrifying Names of the Differential Calculus and the Integral CalculusRating: 4.5 out of 5 stars4.5/5 (2)
- Limitless Mind: Learn, Lead, and Live Without BarriersFrom EverandLimitless Mind: Learn, Lead, and Live Without BarriersRating: 4 out of 5 stars4/5 (6)
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.From EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Rating: 5 out of 5 stars5/5 (1)
- Images of Mathematics Viewed Through Number, Algebra, and GeometryFrom EverandImages of Mathematics Viewed Through Number, Algebra, and GeometryNo ratings yet
- Math Workshop, Grade K: A Framework for Guided Math and Independent PracticeFrom EverandMath Workshop, Grade K: A Framework for Guided Math and Independent PracticeRating: 5 out of 5 stars5/5 (1)
- Making and Tinkering With STEM: Solving Design Challenges With Young ChildrenFrom EverandMaking and Tinkering With STEM: Solving Design Challenges With Young ChildrenNo ratings yet