You might also like
- Signal Processing in Auditory Neuroscience: Temporal and Spatial Features of Sound and SpeechFrom EverandSignal Processing in Auditory Neuroscience: Temporal and Spatial Features of Sound and SpeechNo ratings yet
- Chapter 7Document23 pagesChapter 7enes_ersoy_3No ratings yet
- Obleser08 JneurosciDocument8 pagesObleser08 JneurosciAndrew LiebermannNo ratings yet
- Modeling The Voice Source in Terms of Spectral Slopesa) : Marc Garellekrobin Samlanbruce R. Gerratt Jody KreimanmahDocument8 pagesModeling The Voice Source in Terms of Spectral Slopesa) : Marc Garellekrobin Samlanbruce R. Gerratt Jody KreimanmahChristian Castro ToroNo ratings yet
- Modeling The Voice Source in Terms of Spectral SlopesDocument7 pagesModeling The Voice Source in Terms of Spectral Slopesarts.lamiaaaldawyNo ratings yet
- TMP C510Document8 pagesTMP C510FrontiersNo ratings yet
- Relationship Between Tongue Positions and Formant Frequencies in Female SpeakersDocument16 pagesRelationship Between Tongue Positions and Formant Frequencies in Female SpeakersrairochadelNo ratings yet
- Speaking in Noise - How Does The Lombard Effect Improve Acoustic Contrasts Between Speech and Ambient NoiseDocument18 pagesSpeaking in Noise - How Does The Lombard Effect Improve Acoustic Contrasts Between Speech and Ambient NoiseAna BrankovićNo ratings yet
- Voice Efficiency For Different Voice Qualities ComDocument22 pagesVoice Efficiency For Different Voice Qualities ComTiago BicalhoNo ratings yet
- Influences of Tone On Vowel Articulation in Mandarin ChineseDocument9 pagesInfluences of Tone On Vowel Articulation in Mandarin Chineseandy94264No ratings yet
- Auditory Lexical Decision, Categorical Perception, and FM Direction Discrimination Differentially Engage Left and Right Auditory CortexDocument18 pagesAuditory Lexical Decision, Categorical Perception, and FM Direction Discrimination Differentially Engage Left and Right Auditory Cortexmind36No ratings yet
- MDVPDocument10 pagesMDVPCarlos Carrasco Venegas100% (1)
- Comparison of Frequency Transposition and Frequency Compression For People With Extensive Dead Regions in The CochleaDocument23 pagesComparison of Frequency Transposition and Frequency Compression For People With Extensive Dead Regions in The CochleaAnnel Gómez CoelloNo ratings yet
- Speech Disorders in Parkinson's Disease: Early Diagnostics and Effects of Medication and Brain StimulationDocument32 pagesSpeech Disorders in Parkinson's Disease: Early Diagnostics and Effects of Medication and Brain StimulationsavivashiNo ratings yet
- Ajustes Del Habla para La Acústica de La Sala y Sus Efectos en El Esfuerzo VocalDocument26 pagesAjustes Del Habla para La Acústica de La Sala y Sus Efectos en El Esfuerzo VocalSALSA 10No ratings yet
- Research Article: A T. C, R O, D HDocument12 pagesResearch Article: A T. C, R O, D HCamila Santis MuñozNo ratings yet
- Isra PDFDocument5 pagesIsra PDFhorcajada-1No ratings yet
- Musical Intervals in Speech: Deborah Ross, Jonathan Choi, and Dale PurvesDocument6 pagesMusical Intervals in Speech: Deborah Ross, Jonathan Choi, and Dale PurvesMonta TupčijenkoNo ratings yet
- Linguistic Voice Quality: Patricia A. Keating and Christina EspositoDocument6 pagesLinguistic Voice Quality: Patricia A. Keating and Christina EspositoRavikumar ChowdaryNo ratings yet
- Impact 48 13adoDocument43 pagesImpact 48 13adoDerib AdoNo ratings yet
- Bain MechanismDocument10 pagesBain MechanismAna VenturaNo ratings yet
- Jasa08 ShinnDocument7 pagesJasa08 ShinnTekeres CsabaNo ratings yet
- Temporal Order Perception of Auditory Stimuli Is Selectively Modified by Tonal and Non-Tonal Language EnvironmentsDocument7 pagesTemporal Order Perception of Auditory Stimuli Is Selectively Modified by Tonal and Non-Tonal Language EnvironmentsGianinaNo ratings yet
- Modulation-Based Digital Noise Reduction For Application To Hearing Protectors To Reduce Noise and Maintain IntelligibilityDocument12 pagesModulation-Based Digital Noise Reduction For Application To Hearing Protectors To Reduce Noise and Maintain IntelligibilityveronicaNo ratings yet
- Hawley 20 Litovsky 20 and 20 CullingDocument16 pagesHawley 20 Litovsky 20 and 20 CullingRizki Putri RamadhaniNo ratings yet
- Musical Pitch and Lexical Tone Perception With Cochlear ImplantsDocument9 pagesMusical Pitch and Lexical Tone Perception With Cochlear ImplantsSofía LecterNo ratings yet
- JN 00224 2014Document14 pagesJN 00224 2014Joan MendesNo ratings yet
- 10 0000@www Aes Org@2108Document5 pages10 0000@www Aes Org@2108francisco_mateoNo ratings yet
- Basic Neural Processing of Sound in Adults Is Influenced by Bilingual ExperienceDocument13 pagesBasic Neural Processing of Sound in Adults Is Influenced by Bilingual ExperienceAnthonyNo ratings yet
- Middle Ear Velocity Transfer Function CoDocument14 pagesMiddle Ear Velocity Transfer Function Cojay gauNo ratings yet
- A Comparison of Trained and Untrained Vocalists On The Dysphonia Severity Index PDFDocument6 pagesA Comparison of Trained and Untrained Vocalists On The Dysphonia Severity Index PDFAnaNo ratings yet
- It Doesn 'T Matter What You Say: FMRI Correlates of Voice Learning and Recognition Independent of Speech ContentDocument13 pagesIt Doesn 'T Matter What You Say: FMRI Correlates of Voice Learning and Recognition Independent of Speech ContentGlenn MaramisNo ratings yet
- Distinction For Stops: Role of Formant Transitions in The Voiced-VoicelessDocument7 pagesDistinction For Stops: Role of Formant Transitions in The Voiced-VoicelessNathalia Dos ReisNo ratings yet
- 2013 Steinschneider Hear ResDocument17 pages2013 Steinschneider Hear ResseantipsNo ratings yet
- Distinct Cortical Pathways For Music and Speech Revealed by Hypothesis-Free Voxel DecompositionDocument17 pagesDistinct Cortical Pathways For Music and Speech Revealed by Hypothesis-Free Voxel DecompositionGuilherme MachadoNo ratings yet
- Vowel Acoustics in Dysarthria Speech Disorder Diagnosis and ClassificationDocument11 pagesVowel Acoustics in Dysarthria Speech Disorder Diagnosis and ClassificationHechehouche OualidNo ratings yet
- Correlation Speech Recognition PDFDocument8 pagesCorrelation Speech Recognition PDFJesusita Ortiz CollazosNo ratings yet
- Long-Term Average Spectrum in Screening of Voice Quality in Speech: Untrained Male University StudentsDocument6 pagesLong-Term Average Spectrum in Screening of Voice Quality in Speech: Untrained Male University StudentsMaría Belén Soto AlarcónNo ratings yet
- Speech Communication: Sudarsana Reddy Kadiri, Paavo Alku, B. YegnanarayanaDocument15 pagesSpeech Communication: Sudarsana Reddy Kadiri, Paavo Alku, B. YegnanarayanaИлья МакаровNo ratings yet
- 28 Somashekara EtalDocument6 pages28 Somashekara EtaleditorijmrhsNo ratings yet
- Peelle J2013Document10 pagesPeelle J2013CamiloA.GarcíaNo ratings yet
- Wagner Braun 2002Document5 pagesWagner Braun 2002Aude JihelNo ratings yet
- A Comparison of Auditory Evoked Potentials To Acoustic Beats and To Binaural Beats (Hearing Research, Vol. 262, Issue 1-2) (2010)Document11 pagesA Comparison of Auditory Evoked Potentials To Acoustic Beats and To Binaural Beats (Hearing Research, Vol. 262, Issue 1-2) (2010)FarzanNo ratings yet
- (2021) Rathcke Et Al. - Sentence Sonority and Listener Background Modulate The Speech-To-Song IllusionDocument10 pages(2021) Rathcke Et Al. - Sentence Sonority and Listener Background Modulate The Speech-To-Song Illusionmiguel.jimenez.bravoNo ratings yet
- Transfer Effects in The Vocal Imitation of Speech and SongDocument18 pagesTransfer Effects in The Vocal Imitation of Speech and SongMonta TupčijenkoNo ratings yet
- Transfer Effects in The Vocal Imitation of Speech and SongDocument18 pagesTransfer Effects in The Vocal Imitation of Speech and SongMonta TupčijenkoNo ratings yet
- Vowel Articulation in Parkinson's Disease: Bochum, GermanyDocument6 pagesVowel Articulation in Parkinson's Disease: Bochum, GermanyMáté HiresNo ratings yet
- Acoustic Properties of The Voice Source and The Vocal Tract - 2016 - Journal ofDocument14 pagesAcoustic Properties of The Voice Source and The Vocal Tract - 2016 - Journal ofelinlau0No ratings yet
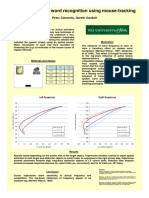
- Analysing Top-Down Effects of Lexical Frequency Using Mousetracking TechniquesDocument1 pageAnalysing Top-Down Effects of Lexical Frequency Using Mousetracking TechniquesPete ClementsNo ratings yet
- Alta Frecuencia Normativa InternacionalDocument16 pagesAlta Frecuencia Normativa InternacionalAndres DurangoNo ratings yet
- High-Frequency Distortion-Product Otoacoustic Emission Repeatability in A Patient PopulationDocument16 pagesHigh-Frequency Distortion-Product Otoacoustic Emission Repeatability in A Patient PopulationCamila Santis MuñozNo ratings yet
- Studi Literatur TikusDocument9 pagesStudi Literatur TikusViva LavidaNo ratings yet
- Test-Retest Reliability of The Speech-Evoked Auditory Brainstem ResponseDocument10 pagesTest-Retest Reliability of The Speech-Evoked Auditory Brainstem ResponseCabinet VeterinarNo ratings yet
- Vocal Pleasantness Ratings Explained by A Musical ApproachDocument10 pagesVocal Pleasantness Ratings Explained by A Musical ApproachAkosNo ratings yet
- BERNADONI Et WOLFE - Vocal Tract Resonances in Singing - Variation With LaryngealDocument11 pagesBERNADONI Et WOLFE - Vocal Tract Resonances in Singing - Variation With LaryngealBruno ArrabalNo ratings yet
- Influence of Musical Training On SensitiDocument8 pagesInfluence of Musical Training On SensitixD xDNo ratings yet
- PERETZ Music Language and Modularity in ActionDocument15 pagesPERETZ Music Language and Modularity in ActionRuiseñor RuizNo ratings yet
- Watt FabDocument15 pagesWatt FabjuanjulianjimenezNo ratings yet
- 12 Celpstrum y Spectrum 2010Document10 pages12 Celpstrum y Spectrum 2010Sebastian Castro TigheNo ratings yet
- Villanueva-Rivera Et Al 2011Document14 pagesVillanueva-Rivera Et Al 2011Jaime Caro VeraNo ratings yet
- A Proposal For The Acoustic Modelling For Word Stress: Mahesh MDocument7 pagesA Proposal For The Acoustic Modelling For Word Stress: Mahesh MInternational Journal of Scientific Research in Science, Engineering and Technology ( IJSRSET )No ratings yet
- 500m 360 Degree Rotary HD Borewell Camera Water Well Borehole Inspection Camera With 12 Inch Screen Electric WinchDocument10 pages500m 360 Degree Rotary HD Borewell Camera Water Well Borehole Inspection Camera With 12 Inch Screen Electric WinchCristopferENo ratings yet
- Assignment AEP 2014Document5 pagesAssignment AEP 2014Sagar MohanNo ratings yet
- TerritoriesWhitePaper V11 PDFDocument42 pagesTerritoriesWhitePaper V11 PDFMbade NDONGNo ratings yet
- F15-04 (2013) Standard Specification For Iron-Nickel-Cobalt Sealing AlloyDocument7 pagesF15-04 (2013) Standard Specification For Iron-Nickel-Cobalt Sealing Alloymercab15No ratings yet
- AWS TCO WorkSpacesDocument16 pagesAWS TCO WorkSpacessantuchetuNo ratings yet
- Departemen Statistika, Fakultas Sains Dan Matematika, Universitas DiponegoroDocument12 pagesDepartemen Statistika, Fakultas Sains Dan Matematika, Universitas DiponegoromonicaramadhaniaNo ratings yet
- Ict Igcse Paper 2 Revision DatabaseDocument9 pagesIct Igcse Paper 2 Revision DatabaseIndianagrofarmsNo ratings yet
- VSM Blue)Document4 pagesVSM Blue)api-27411749No ratings yet
- Log TMBAG6NEXD0028904 210446km 130765miDocument6 pagesLog TMBAG6NEXD0028904 210446km 130765miSasa MitrovicNo ratings yet
- Automated Zone Speci C Irrigation With Wireless Sensor Actuator Network and Adaptable Decision SupportDocument28 pagesAutomated Zone Speci C Irrigation With Wireless Sensor Actuator Network and Adaptable Decision SupportNakal Hans Beta VersionNo ratings yet
- Rate LawsDocument20 pagesRate LawsReginal MoralesNo ratings yet
- Pupalaikis - S Parameters For Signal IntegrityDocument666 pagesPupalaikis - S Parameters For Signal IntegrityzhangwenNo ratings yet
- PErformance TEstDocument13 pagesPErformance TEstPraveen ChoudharyNo ratings yet
- EMV Multi Cable Transit Modular System (EMC-System) : PDFDocument7 pagesEMV Multi Cable Transit Modular System (EMC-System) : PDFbakien-canNo ratings yet
- Prmo 2018 QPDocument2 pagesPrmo 2018 QPJatin RatheeNo ratings yet
- Introduction To IoT With Machine Learning and Image Processing Using Raspberry Pi (Shrirang Ambaji Kulkarni, Varadrah P. Gurupur Etc.) (Z-Library)Document167 pagesIntroduction To IoT With Machine Learning and Image Processing Using Raspberry Pi (Shrirang Ambaji Kulkarni, Varadrah P. Gurupur Etc.) (Z-Library)Siddhant RawatNo ratings yet
- Availability Simulation - IsographDocument1 pageAvailability Simulation - IsographsaospieNo ratings yet
- BS 1370 1979Document13 pagesBS 1370 1979thushtikaNo ratings yet
- Edr IonicsDocument3 pagesEdr IonicsMax JacintoNo ratings yet
- Poster Presentation 3Document1 pagePoster Presentation 3Julien FaureNo ratings yet
- To Study The Fourier Series and Transform by Using OscilloscopeDocument5 pagesTo Study The Fourier Series and Transform by Using OscilloscopeSagar RawalNo ratings yet
- Class Notes On Gravitation (Physics 152) : Galileo Analyzes A Cannonball TrajectoryDocument4 pagesClass Notes On Gravitation (Physics 152) : Galileo Analyzes A Cannonball TrajectorythestudierNo ratings yet
- LP2 Lubrication Pinion For Lubrication of Open Girth Gears, Tooth Wheels and Gear RodsDocument44 pagesLP2 Lubrication Pinion For Lubrication of Open Girth Gears, Tooth Wheels and Gear RodsThanhluan NguyenNo ratings yet
- BSC CSThird Year Affiliated College Syllabuswef 202122Document36 pagesBSC CSThird Year Affiliated College Syllabuswef 202122HeadofDepartmentCS SSCPNo ratings yet
- DS PGM Using CPPDocument18 pagesDS PGM Using CPPanand5703No ratings yet
- The Common Java CookbookDocument333 pagesThe Common Java Cookbooktmo9d100% (20)
- Unification of Euler and Werner Deconvolution in Three Dimensions Via The Generalized Hilbert TransformDocument6 pagesUnification of Euler and Werner Deconvolution in Three Dimensions Via The Generalized Hilbert TransformMithunNo ratings yet
- 878Document47 pages878IulianCiobanuNo ratings yet
- ATS (Automatic Trasfer Switch) : 2 Positions (A B)Document4 pagesATS (Automatic Trasfer Switch) : 2 Positions (A B)Berkah Jaya PanelNo ratings yet