You might also like
- Ex 1Document7 pagesEx 1THỊNH DIỆP PHƯỚCNo ratings yet
- Chuong 3Document18 pagesChuong 3Pktc BKNo ratings yet
- T H I Quy VectoDocument18 pagesT H I Quy VectoAnh Vy Nguyễn50% (2)
- Các Kết Quả Và Dữ Liệu Thu Thập ĐượcDocument10 pagesCác Kết Quả Và Dữ Liệu Thu Thập ĐượcTrần Quang NgọcNo ratings yet
- Marketing Ngân HàngDocument29 pagesMarketing Ngân HàngPhạm Quỳnh OanhNo ratings yet
- ARIMADocument19 pagesARIMAHiếu Nguyễn Võ Trung100% (1)
- Tính D NG PDFDocument7 pagesTính D NG PDFHiep NguyenNo ratings yet
- On Tap Ly Thuyet 1Document13 pagesOn Tap Ly Thuyet 1Nhi Trần Võ XuânNo ratings yet
- Gujarati 2011 Chương 6 - Chẩn Đoán Hồi Quy Tự Tương QuanDocument28 pagesGujarati 2011 Chương 6 - Chẩn Đoán Hồi Quy Tự Tương QuanMAI NGUYEN THINo ratings yet
- THỰC HÀNH STATA VÀ KẾT QUẢ NGHIÊN CỨUDocument11 pagesTHỰC HÀNH STATA VÀ KẾT QUẢ NGHIÊN CỨUK60 Lê Thị Hoàng MyNo ratings yet
- Thống kê suy diễnDocument15 pagesThống kê suy diễnluatsua09No ratings yet
- đề ôn thi KTLDocument42 pagesđề ôn thi KTLIrene Quỳnh AnhNo ratings yet
- đề ôn thi KTLDocument42 pagesđề ôn thi KTLAnh NgocNo ratings yet
- A KINH TẾ LƯỢNGDocument130 pagesA KINH TẾ LƯỢNGNgô Việt ĐứcNo ratings yet
- Định lý CayleyDocument8 pagesĐịnh lý Cayleytnquynh1127893No ratings yet
- TCDL - Ôn ThiDocument6 pagesTCDL - Ôn ThiHuyên Huỳnh ThanhNo ratings yet
- HQ dữ liệu bảng 5Document20 pagesHQ dữ liệu bảng 5Dũng NguyễnNo ratings yet
- Kinh Tế LượngDocument44 pagesKinh Tế LượngHoàng Đức AnnhNo ratings yet
- Buổi 6: Các khuyết tật của mô hình 1. Đa cộng tuyếnDocument6 pagesBuổi 6: Các khuyết tật của mô hình 1. Đa cộng tuyếnHương GiangNo ratings yet
- TN Full KTLTC TVDocument61 pagesTN Full KTLTC TVDUYÊN NGUYỄN THỊ MINHNo ratings yet
- Session 03 - ToanTuVaBieuThucDocument26 pagesSession 03 - ToanTuVaBieuThucdiemtung2k3No ratings yet
- Điều chế deltaDocument4 pagesĐiều chế deltaDanh ManhNo ratings yet
- Nghiên C U MarDocument12 pagesNghiên C U MarNguyễn Bảo LinhNo ratings yet
- T Tƣơng QuanDocument79 pagesT Tƣơng QuanAnh KimNo ratings yet
- Tài Liệu ôn PTKDDocument8 pagesTài Liệu ôn PTKDNguyễn Thái Thảo BíchNo ratings yet
- Hiện tượng đa cộng tuyếnDocument4 pagesHiện tượng đa cộng tuyếnTuan Nguyen NgocNo ratings yet
- NHÓM 4 - BÀI TẬP CHƯƠNG 3 SÁCH BROOKSDocument25 pagesNHÓM 4 - BÀI TẬP CHƯƠNG 3 SÁCH BROOKSNguyen PhamNo ratings yet
- Tai Lieu VECM 2013Document19 pagesTai Lieu VECM 2013Khánh MinhNo ratings yet
- NHÓM 1 - BUỔI 1 - KINH TẾ LƯỢNG TÀI CHÍNHDocument10 pagesNHÓM 1 - BUỔI 1 - KINH TẾ LƯỢNG TÀI CHÍNHkimchi.15102004No ratings yet
- Nghiên C U MAR22Document24 pagesNghiên C U MAR22Vân KhanhNo ratings yet
- MPP2019 521 R17V A Guide To Modern Econometrics Marno Verbeek - Ch4 4.6 4.11 2017 12 28 16084753Document23 pagesMPP2019 521 R17V A Guide To Modern Econometrics Marno Verbeek - Ch4 4.6 4.11 2017 12 28 16084753thuanhuynhNo ratings yet
- TH C Hành Spss 25 - 01 - 24Document23 pagesTH C Hành Spss 25 - 01 - 24ngphanh955No ratings yet
- Bai Tap5 - DH48AD003 - Nhom 2Document6 pagesBai Tap5 - DH48AD003 - Nhom 2truong717159No ratings yet
- Chương 5Document9 pagesChương 5Vũ Ngọc LanNo ratings yet
- Hồi quy tt bội: giá trị p của thử nghiệm t bằng cách sử dụng bảng Phân phối tDocument4 pagesHồi quy tt bội: giá trị p của thử nghiệm t bằng cách sử dụng bảng Phân phối thuy.le1003No ratings yet
- NCCDocument34 pagesNCCVân TrườngNo ratings yet
- Đề thi thử cuối kìDocument8 pagesĐề thi thử cuối kìQuang NguyễnNo ratings yet
- Thi TCĐLDocument8 pagesThi TCĐLHuyên Huỳnh ThanhNo ratings yet
- Kinh Tế Lượng - Khoảng Tin Cậy Và Kiểm Định Giả Thiết Về Các Hệ Số Hồi Quy - VOERDocument12 pagesKinh Tế Lượng - Khoảng Tin Cậy Và Kiểm Định Giả Thiết Về Các Hệ Số Hồi Quy - VOERlinhnamvipNo ratings yet
- Tóm tắt UDTKDocument7 pagesTóm tắt UDTKHuỳnh TrâmNo ratings yet
- Phương Pháp SaiDocument4 pagesPhương Pháp SaitavietcuongNo ratings yet
- Cơ Sở Lý Thuyết: A. Hồi Quy Tuyến Tính 1.1 Mô hình hồi quy tuyến tính bộiDocument19 pagesCơ Sở Lý Thuyết: A. Hồi Quy Tuyến Tính 1.1 Mô hình hồi quy tuyến tính bộiĐức TrọngNo ratings yet
- Phát hiện và khắc phục hiện tượng tự tương quanDocument27 pagesPhát hiện và khắc phục hiện tượng tự tương quanscribbyscrib50% (2)
- BÀI THẢO LUẬN KTL1Document18 pagesBÀI THẢO LUẬN KTL1anhphamphuongtt2No ratings yet
- Bai DichDocument6 pagesBai Dichhoangthach04No ratings yet
- Phân Tích Tương Quan PearsonDocument2 pagesPhân Tích Tương Quan PearsonDanh NguyễnNo ratings yet
- 2. Bài tập thực hành máy tính tái tạo kết quả hồi quy dữ liệu bảng trong slides sử dụng StataDocument40 pages2. Bài tập thực hành máy tính tái tạo kết quả hồi quy dữ liệu bảng trong slides sử dụng StataĐÀO NGUYỄN THỊNo ratings yet
- 1.3 1.4 1.5Document3 pages1.3 1.4 1.5solane5629No ratings yet
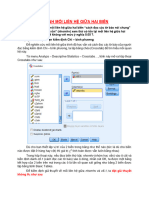
- 2-HD-SPSS 04-Kiem Dinh Moi Lien He Giua Hai BienDocument10 pages2-HD-SPSS 04-Kiem Dinh Moi Lien He Giua Hai Bienhlpt2004No ratings yet
- Chương 3Document26 pagesChương 3QuangKiệtNo ratings yet
- Bài Tập Chương 2Document6 pagesBài Tập Chương 2Nghiêm NgọNo ratings yet
- Btl Xstk Phần RiêngDocument12 pagesBtl Xstk Phần RiêngkimNo ratings yet
- XSTK-BTL-cơ sở lý thuyếtDocument8 pagesXSTK-BTL-cơ sở lý thuyếttranngotruclanNo ratings yet
- XSTKT p14 16Document2 pagesXSTKT p14 16viên viênNo ratings yet
- Câu hỏi BTL2Document6 pagesCâu hỏi BTL2Thắng Võ NgọcNo ratings yet
- Chương 3 LDPCDocument23 pagesChương 3 LDPCCUc GAch0% (1)
- Chapter 5 Low Density Parity Check CodesDocument13 pagesChapter 5 Low Density Parity Check CodesQuân DươngNo ratings yet
- Chương 3 Sử Dụng Thống Kê Trong Phân Tích Số LiệuDocument29 pagesChương 3 Sử Dụng Thống Kê Trong Phân Tích Số LiệuMinh MinhNo ratings yet
- Regression Analysis in Machine LearningDocument13 pagesRegression Analysis in Machine LearningLove AngerNo ratings yet