You might also like
- Backpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningFrom EverandBackpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningNo ratings yet
- DeepLearing TheoryDocument51 pagesDeepLearing TheorytharunNo ratings yet
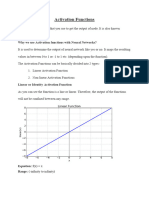
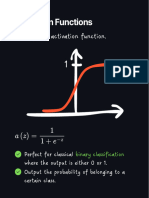
- Activation FunctionDocument31 pagesActivation FunctionAnkur SharmaNo ratings yet
- Unit IvDocument34 pagesUnit Ivdanmanworld443No ratings yet
- Deep Learning Unit 1Document32 pagesDeep Learning Unit 1Aditya Pratap SinghNo ratings yet
- SoftComp 02Document33 pagesSoftComp 02Aditya RautNo ratings yet
- Activation Function To Back ProDocument22 pagesActivation Function To Back ProMeghaNo ratings yet
- Deep LearningDocument40 pagesDeep LearningDr. Dnyaneshwar KirangeNo ratings yet
- Activation FunctionsDocument8 pagesActivation FunctionsRoushan GiriNo ratings yet
- Lecture 2.1.2activation FunctionDocument15 pagesLecture 2.1.2activation FunctionMohd YusufNo ratings yet
- Lecture 15Document21 pagesLecture 15Abood FazilNo ratings yet
- Deep Learning - DL-2Document44 pagesDeep Learning - DL-2Hasnain AhmadNo ratings yet
- Activation FunctionsDocument29 pagesActivation FunctionsAsimullah, M.Phil. Scholar Department of Computer Science, UoPNo ratings yet
- Experiment No. 1 SL-II (ANN)Document3 pagesExperiment No. 1 SL-II (ANN)RutujaNo ratings yet
- Activation Functions in Neural Networks - GeeksforGeeksDocument12 pagesActivation Functions in Neural Networks - GeeksforGeekswendu felekeNo ratings yet
- Unit 2 - Machine LearningDocument19 pagesUnit 2 - Machine LearningGauri BansalNo ratings yet
- Week - 5 (Deep Learning) Q. 1) Explain The Architecture of Feed Forward Neural Network or Multilayer Perceptron. (12 Marks)Document7 pagesWeek - 5 (Deep Learning) Q. 1) Explain The Architecture of Feed Forward Neural Network or Multilayer Perceptron. (12 Marks)Mrunal BhilareNo ratings yet
- AI SVM NetworkDocument10 pagesAI SVM Networkrajthakre81No ratings yet
- notes on Introduction to Deep learningDocument19 pagesnotes on Introduction to Deep learningthumpsup1223No ratings yet
- Activation FunctionsDocument6 pagesActivation FunctionsthummalakuntasNo ratings yet
- Lab 2Document35 pagesLab 2Mohammed MustafaNo ratings yet
- Introduction To Deep LearningDocument48 pagesIntroduction To Deep LearningEshan JainNo ratings yet
- 465-Lecture 2-4Document43 pages465-Lecture 2-4Faisal Bin Abdur Rahman 1912038642No ratings yet
- 6 Types of Activation Functions in Neural NetworksDocument5 pages6 Types of Activation Functions in Neural NetworksNiteshNarukaNo ratings yet
- Unit 3 - Diving - Deep - LearningDocument108 pagesUnit 3 - Diving - Deep - LearningAlekhya RoyNo ratings yet
- Lecture 4Document33 pagesLecture 4Venkat ram ReddyNo ratings yet
- Machine Learning NNDocument16 pagesMachine Learning NNMegha100% (1)
- Types of Machine Learning: Supervised Learning: The Computer Is Presented With Example Inputs and TheirDocument50 pagesTypes of Machine Learning: Supervised Learning: The Computer Is Presented With Example Inputs and TheirJayesh GadewarNo ratings yet
- Activation Functions - Ipynb - ColaboratoryDocument10 pagesActivation Functions - Ipynb - ColaboratoryGOURAV SAHOONo ratings yet
- Unit 2Document18 pagesUnit 2Nitya ShuklaNo ratings yet
- Machine Learning With Artificial Neural NetworksDocument44 pagesMachine Learning With Artificial Neural Networksanuj saxenaNo ratings yet
- Backpropag-Relu-Grad DescentDocument2 pagesBackpropag-Relu-Grad DescentNishita VermaNo ratings yet
- 4 4 Choosing The Right Activation Function For Neural NetworksDocument25 pages4 4 Choosing The Right Activation Function For Neural Networksabbas1999n8No ratings yet
- Activation FunctionDocument13 pagesActivation FunctionPrincess SwethaNo ratings yet
- Activation Functions in Neural NetworksDocument10 pagesActivation Functions in Neural Networksisha.kapoor.cse.2021No ratings yet
- Deep Neural Network (DNN)Document80 pagesDeep Neural Network (DNN)20210802144No ratings yet
- How To Choose An Activation Function For Deep LearningDocument15 pagesHow To Choose An Activation Function For Deep LearningAbdul KhaliqNo ratings yet
- Unit 2 - Machine Learning - WWW - Rgpvnotes.inDocument18 pagesUnit 2 - Machine Learning - WWW - Rgpvnotes.inROHIT MISHRANo ratings yet
- DL_Notes_ALL.docxDocument63 pagesDL_Notes_ALL.docxapwaghmareNo ratings yet
- Deep Learning: International Islamic University of ChittagongDocument31 pagesDeep Learning: International Islamic University of ChittagongAyat UllahNo ratings yet
- Activation Functions in Neural Networks: What Is Activation Function?Document11 pagesActivation Functions in Neural Networks: What Is Activation Function?Navneet LalwaniNo ratings yet
- Activation Functions DLDocument8 pagesActivation Functions DLdhdhdNo ratings yet
- 12 Types of Neural Network Activation FunctionsDocument38 pages12 Types of Neural Network Activation FunctionsNusrat UllahNo ratings yet
- Hidden Units and Network Architecture DesignDocument15 pagesHidden Units and Network Architecture DesignDEIVAM RNo ratings yet
- Machine Learning Concepts for HealthcareDocument16 pagesMachine Learning Concepts for HealthcareRaj PhysioNo ratings yet
- CS601 - Machine Learning - Unit 2 - Notes - 1672759753Document14 pagesCS601 - Machine Learning - Unit 2 - Notes - 1672759753mohit jaiswalNo ratings yet
- ML Session 15 BackpropagationDocument30 pagesML Session 15 Backpropagationkr8665894No ratings yet
- Activation Functions: Sigmoid, Tanh, Relu, Leaky Relu, Prelu, Elu, Threshold Relu and Softmax Basics For Neural Networks and Deep LearningDocument15 pagesActivation Functions: Sigmoid, Tanh, Relu, Leaky Relu, Prelu, Elu, Threshold Relu and Softmax Basics For Neural Networks and Deep LearningRMolina65No ratings yet
- ANN - CAE-II Important QuestionsDocument11 pagesANN - CAE-II Important QuestionsAnurag RautNo ratings yet
- Deep Learning Applications in Stock Prediction and CybersecurityDocument21 pagesDeep Learning Applications in Stock Prediction and CybersecurityAman AgarwalNo ratings yet
- Module1 ECO-598 AI & ML Aug 21Document45 pagesModule1 ECO-598 AI & ML Aug 21Soujanya NerlekarNo ratings yet
- ML3 Unit 4-3Document13 pagesML3 Unit 4-3ISHAN SRIVASTAVANo ratings yet
- 0905 Cs 161183 VishalDocument38 pages0905 Cs 161183 VishalVishal JainNo ratings yet
- Regularization: Swetha V, Research ScholarDocument32 pagesRegularization: Swetha V, Research ScholarShanmuganathan V (RC2113003011029)No ratings yet
- Neural Networks NotesDocument22 pagesNeural Networks NoteszomukozaNo ratings yet
- Perceptron For ClassDocument28 pagesPerceptron For Classiemct23No ratings yet
- Aditya Jain NN AssignmentDocument13 pagesAditya Jain NN AssignmentAditya JainNo ratings yet
- Machine Learning101Document20 pagesMachine Learning101consaniaNo ratings yet
- Unit Iv DMDocument58 pagesUnit Iv DMSuganthi D PSGRKCWNo ratings yet
- Functii de Activare1Document89 pagesFunctii de Activare1adrian IosifNo ratings yet
- Huawei Quiz CpeDocument2 pagesHuawei Quiz CpeJonafe Piamonte100% (1)
- Artificial Neural Networks: An Overview: August 2023Document11 pagesArtificial Neural Networks: An Overview: August 2023LoneSamuraiNo ratings yet
- MCQDocument4 pagesMCQspraveen2007No ratings yet
- BE IT 2019 Course Syllabus 20032023Document106 pagesBE IT 2019 Course Syllabus 20032023Shiv MishraNo ratings yet
- Candidate Checklist for AR Team LeaderDocument4 pagesCandidate Checklist for AR Team Leadervipin HNo ratings yet
- Ham CIPF Crossing Intention Prediction Network Based On Feature Fusion Modules CVPRW 2023 PaperDocument10 pagesHam CIPF Crossing Intention Prediction Network Based On Feature Fusion Modules CVPRW 2023 PaperBeer JohnstonNo ratings yet
- Applsci 13 06667Document22 pagesApplsci 13 06667SANDHYA RANI N 218002114No ratings yet
- Analog Architectures For Neural Network Acceleration Based On Non-Volatile MemoryDocument35 pagesAnalog Architectures For Neural Network Acceleration Based On Non-Volatile MemoryAditya AgarwalNo ratings yet
- University of Arizona Honors ThesisDocument6 pagesUniversity of Arizona Honors Thesisbkxk6fzf100% (2)
- Ntust Kuberun and DLDocument48 pagesNtust Kuberun and DLAna YelinaNo ratings yet
- Icramet RDGAN Rep3Document6 pagesIcramet RDGAN Rep3Tri WinotoNo ratings yet
- Fusing Blockchain and AI With Metaverse A SurveyDocument15 pagesFusing Blockchain and AI With Metaverse A Surveywer78230No ratings yet
- Tung Similarity-Preserving Knowledge Distillation ICCV 2019 PaperDocument10 pagesTung Similarity-Preserving Knowledge Distillation ICCV 2019 Paperraniahamizi006No ratings yet
- Automated Image Captioning With Convnets and Recurrent Nets: Andrej Karpathy, Fei-Fei LiDocument105 pagesAutomated Image Captioning With Convnets and Recurrent Nets: Andrej Karpathy, Fei-Fei LiChandra Shekhar KadiyamNo ratings yet
- DEX: Deep Expectation of Apparent AgeDocument6 pagesDEX: Deep Expectation of Apparent AgeThilini NadeeshaNo ratings yet
- Car Make and Model Recognition Using ImaDocument8 pagesCar Make and Model Recognition Using ImaRAna AtIfNo ratings yet
- Collective Intelligence Deep LearningDocument23 pagesCollective Intelligence Deep LearningMarcello BarylliNo ratings yet
- Improvement of Learning For CNN With Relu Activation by Sparse RegularizationDocument8 pagesImprovement of Learning For CNN With Relu Activation by Sparse RegularizationTerves AlexanderNo ratings yet
- Project PlanDocument8 pagesProject Planapi-532121045No ratings yet
- Practical Guide to Understanding and Applying Graph Neural NetworksDocument28 pagesPractical Guide to Understanding and Applying Graph Neural NetworksHoàng ThắngNo ratings yet
- TensorFlow 1.x Deep Learning Cookbook - Over 90 Unique Recipes To Solve Artificial-Intelligence Driven Problems With PythonDocument526 pagesTensorFlow 1.x Deep Learning Cookbook - Over 90 Unique Recipes To Solve Artificial-Intelligence Driven Problems With PythonArun A S PillaiNo ratings yet
- Transfer Learning Based Plant Diseases Detection Using ResNet50Document6 pagesTransfer Learning Based Plant Diseases Detection Using ResNet50Madhusmita SahuNo ratings yet
- Transunet: Transformers Make Strong Encoders For Medical Image SegmentationDocument13 pagesTransunet: Transformers Make Strong Encoders For Medical Image SegmentationHima SagarNo ratings yet
- Fire Hotspots Detection System On CCTV Videos Using You Only Look Once (YOLO) Method and Tiny YOLO Model For High Buildings EvacuationDocument6 pagesFire Hotspots Detection System On CCTV Videos Using You Only Look Once (YOLO) Method and Tiny YOLO Model For High Buildings EvacuationDinar TASNo ratings yet
- (IJCST-V12I1P6) :kaushik Kashyap, Rinku Moni Borah, Priyanku Rahang, DR Bornali Gogoi, Prof. Nelson R VarteDocument5 pages(IJCST-V12I1P6) :kaushik Kashyap, Rinku Moni Borah, Priyanku Rahang, DR Bornali Gogoi, Prof. Nelson R VarteEighthSenseGroupNo ratings yet
- Dog Breed Classificationusing Convolutional Neural NetworkDocument54 pagesDog Breed Classificationusing Convolutional Neural NetworkLike meshNo ratings yet
- Detecting illegal logging using audio identification over IoTDocument8 pagesDetecting illegal logging using audio identification over IoTClara JustinoNo ratings yet
- Literature Survey For Lung Cancer Analysis and PredictionDocument6 pagesLiterature Survey For Lung Cancer Analysis and PredictionIJRASETPublicationsNo ratings yet
- RohanChopraAaronEngl 2019 DataSciencewithPythonCombinePythonwithMaDocument426 pagesRohanChopraAaronEngl 2019 DataSciencewithPythonCombinePythonwithMaBrayan BuitragoNo ratings yet
- Semi-Supervised Learning With Self-Supervised NetworksDocument10 pagesSemi-Supervised Learning With Self-Supervised NetworksÅrjüñ GårgNo ratings yet