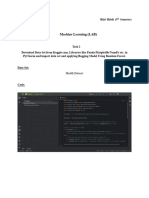
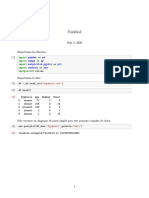
You might also like
- AI Class 10 Sample Paper-1 - 2024Document7 pagesAI Class 10 Sample Paper-1 - 2024rockstargirl108No ratings yet
- Machine Learning With SQLDocument12 pagesMachine Learning With SQLprince krish100% (1)
- Semantic Network Analysis in Social SciencesDocument249 pagesSemantic Network Analysis in Social SciencesJUAN FRANCISCO ROZAS DE QUINTANANo ratings yet
- Machine Learning LAB: Practical-1Document24 pagesMachine Learning LAB: Practical-1Tsering Jhakree100% (1)
- Logistic RegressionDocument7 pagesLogistic RegressionShaaficiNo ratings yet
- ML (Lab 8) Tasks Bilal Habib (5th Semester)Document16 pagesML (Lab 8) Tasks Bilal Habib (5th Semester)muhammad.shahrukhNo ratings yet
- Week 7 Laboratory ActivityDocument12 pagesWeek 7 Laboratory ActivityGar NoobNo ratings yet
- KNN Age Prediction ModelDocument9 pagesKNN Age Prediction ModelARINA SYAKIRAH MUHAIYUDDINNo ratings yet
- DeepLearningForVisionSystems Ch5 ResNetDocument24 pagesDeepLearningForVisionSystems Ch5 ResNetmkkadambiNo ratings yet
- Tensor Flow and Keras Sample ProgramsDocument22 pagesTensor Flow and Keras Sample Programsvinothkumar0743No ratings yet
- ML Paper - Breast Cancer ModelDocument38 pagesML Paper - Breast Cancer ModelAwesomeDudeNo ratings yet
- Experiment No.: 8: T. Y. B. Tech (CSE) - II Subject: Open Source Lab-IIDocument2 pagesExperiment No.: 8: T. Y. B. Tech (CSE) - II Subject: Open Source Lab-IIASHISH MALINo ratings yet
- MLA Lab 6:-Implementation of Decision TreeDocument16 pagesMLA Lab 6:-Implementation of Decision Treetushar3patil03No ratings yet
- FML File FinalDocument36 pagesFML File FinalKunal SainiNo ratings yet
- Maxbox - Starter67 Machine LearningDocument7 pagesMaxbox - Starter67 Machine LearningMax KleinerNo ratings yet
- ML Lab Manual (1-10) FINALDocument34 pagesML Lab Manual (1-10) FINALchintuNo ratings yet
- Roll NO 2020Document8 pagesRoll NO 2020Ali MohsinNo ratings yet
- Decision TreeDocument3 pagesDecision TreesabaNo ratings yet
- Mla - 2 (Cia - 1) - 20221013Document14 pagesMla - 2 (Cia - 1) - 20221013JEFFREY WILLIAMS P M 20221013No ratings yet
- ML0101EN Clas Decision Trees Drug Py v1Document12 pagesML0101EN Clas Decision Trees Drug Py v1banicxNo ratings yet
- 20mid0209 Lab - 6Document11 pages20mid0209 Lab - 6R B SHARANNo ratings yet
- Aychew ChernetDocument8 pagesAychew ChernetaychewchernetNo ratings yet
- ML - Practical FileDocument15 pagesML - Practical FileJatin MathurNo ratings yet
- Remedial Uts AiDocument6 pagesRemedial Uts AiZULFIKAR AFI MALIKNo ratings yet
- Tutorial 6Document8 pagesTutorial 6POEASONo ratings yet
- Data Mining and Warehousing Concepts Lab: (ITPC - 228)Document6 pagesData Mining and Warehousing Concepts Lab: (ITPC - 228)Angelina TutuNo ratings yet
- SodapdfDocument1 pageSodapdfNathon MineNo ratings yet
- Machine Learning Lab Manual (15CSL76)Document30 pagesMachine Learning Lab Manual (15CSL76)Priyanka VermaNo ratings yet
- DWDM Unit-3: What Is Classification? What Is Prediction?Document12 pagesDWDM Unit-3: What Is Classification? What Is Prediction?Sai Venkat GudlaNo ratings yet
- Project 1Document4 pagesProject 1aqsa yousafNo ratings yet
- ML Lab RecordDocument27 pagesML Lab RecordVENKATVYASNo ratings yet
- Data Mining 4th IsDocument24 pagesData Mining 4th IsRewan NaGyNo ratings yet
- Introduction To Python and Computer Programming 1704298503Document44 pagesIntroduction To Python and Computer Programming 1704298503el.tico.138623No ratings yet
- Ishan Aiml 1Document3 pagesIshan Aiml 1Ishan AhujaNo ratings yet
- Data MiningDocument27 pagesData Miningbekar1012No ratings yet
- 1 - An Introduction To Machine Learning With Scikit-LearnDocument9 pages1 - An Introduction To Machine Learning With Scikit-Learnyati kumariNo ratings yet
- projetML Ing1 24Document2 pagesprojetML Ing1 24Mouhib HermiNo ratings yet
- Diabetes Case Study - Jupyter NotebookDocument10 pagesDiabetes Case Study - Jupyter NotebookAbhising100% (1)
- Reagrding Lab TestDocument8 pagesReagrding Lab Testaman rajNo ratings yet
- Dwdm-Unit-3 R16Document14 pagesDwdm-Unit-3 R16Manaswini BhaskaruniNo ratings yet
- AI and ML Lab ManualDocument29 pagesAI and ML Lab ManualNithya NairNo ratings yet
- ML NEW Final FormatDocument37 pagesML NEW Final FormatTharun KumarNo ratings yet
- Lab Week 7Document3 pagesLab Week 7Muhd FakhrullahNo ratings yet
- Assigmnent 3 (Data Mining)Document18 pagesAssigmnent 3 (Data Mining)Naeem IslamNo ratings yet
- ML pr5Document3 pagesML pr5shekh dhrupalNo ratings yet
- FML LabFile 7expsDocument37 pagesFML LabFile 7expsKunal SainiNo ratings yet
- Class 14 - Basic Coding in Python - 5Document24 pagesClass 14 - Basic Coding in Python - 5Naimur RahmanNo ratings yet
- Worksheet No. 9: 1. Aim/Overview of The PracticalDocument6 pagesWorksheet No. 9: 1. Aim/Overview of The PracticalBLACKER EMPIRENo ratings yet
- Week14 N9Document3 pagesWeek14 N920131A05N9 SRUTHIK THOKALANo ratings yet
- MLP Week 6 NaiveBayesImplementation - Ipynb - ColaboratoryDocument5 pagesMLP Week 6 NaiveBayesImplementation - Ipynb - ColaboratoryMeer HassanNo ratings yet
- Deep Learning RecordDocument70 pagesDeep Learning Recordmathan.balaji.02No ratings yet
- 4.1.3.5 Lab - Decision Tree ClassificationDocument11 pages4.1.3.5 Lab - Decision Tree ClassificationNurul Fadillah JannahNo ratings yet
- The Art of Finding The Best Features For Machine Learning - by Rebecca Vickery - Towards Data ScienceDocument14 pagesThe Art of Finding The Best Features For Machine Learning - by Rebecca Vickery - Towards Data ScienceHamdan Gani, S.Kom., MTNo ratings yet
- The Implication of Statistical Analysis and Feature Engineering For Model Building Using Machine Learning AlgorithmsDocument11 pagesThe Implication of Statistical Analysis and Feature Engineering For Model Building Using Machine Learning AlgorithmsijcsesNo ratings yet
- DTEXP5Document8 pagesDTEXP5Sanya SinghNo ratings yet
- CodesDocument6 pagesCodesVamshi KrishnaNo ratings yet
- Deep LearningDocument25 pagesDeep Learningdevansh misraNo ratings yet
- ML Worksheet 7 20BCS2957Document4 pagesML Worksheet 7 20BCS2957srishti JaitlyNo ratings yet
- 18mca52c U3Document8 pages18mca52c U3SivarajanNo ratings yet
- For More Visit WWW - Ktunotes.inDocument21 pagesFor More Visit WWW - Ktunotes.inArcha RajanNo ratings yet
- ArbolesRF UNIDocument3 pagesArbolesRF UNIALISON ELIZABETH HUAPAYA CAYCHONo ratings yet
- Building A Simple Machine Learning Model On Breast Cancer DataDocument12 pagesBuilding A Simple Machine Learning Model On Breast Cancer DataKhalifa MoizNo ratings yet
- Grade 1 Written Paper For StudentsDocument9 pagesGrade 1 Written Paper For Studentsmuhammad.shahrukhNo ratings yet
- Week 2 Power PlantsDocument32 pagesWeek 2 Power Plantsmuhammad.shahrukhNo ratings yet
- ML (Lab 8) Tasks Bilal Habib (5th Semester)Document16 pagesML (Lab 8) Tasks Bilal Habib (5th Semester)muhammad.shahrukhNo ratings yet
- EE7243 - Control of Electric Machine DrivesDocument3 pagesEE7243 - Control of Electric Machine Drivesmuhammad.shahrukhNo ratings yet
- Machine Learning Lab Evaluation. - Sheet1Document1 pageMachine Learning Lab Evaluation. - Sheet1muhammad.shahrukhNo ratings yet
- Machine Learning Classification Model For Identifying Wildlife Species in East AfricaDocument9 pagesMachine Learning Classification Model For Identifying Wildlife Species in East AfricaInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- ICDM UpliftDocument10 pagesICDM UpliftaliceecpknNo ratings yet
- DW PracticalsDocument40 pagesDW PracticalsMr Sathesh Abraham Leo CSENo ratings yet
- ML Models ConceptsDocument32 pagesML Models ConceptsZarfa MasoodNo ratings yet
- Evolution and Testimony of Deep Learning Algorithm For Diabetic Retinopathy DetectionDocument5 pagesEvolution and Testimony of Deep Learning Algorithm For Diabetic Retinopathy DetectionLaode AnsyarullahNo ratings yet
- Detectionof Cotton Plant DiseseDocument20 pagesDetectionof Cotton Plant DiseseAdarsh ChauhanNo ratings yet
- Final Synopsis-Major Abhilasha, AnanyaDocument10 pagesFinal Synopsis-Major Abhilasha, AnanyaAbhilasha GoelNo ratings yet
- Real Time Student Emotion Analysis Changed 2Document7 pagesReal Time Student Emotion Analysis Changed 2NavyaNo ratings yet
- 1 s2.0 S0301679X22005163 MainDocument20 pages1 s2.0 S0301679X22005163 Mainsmitirupa.pradhanfmeNo ratings yet
- PIIS2451929420300851Document13 pagesPIIS2451929420300851Chris BertNo ratings yet
- Machine Learning - Unit - 1Document58 pagesMachine Learning - Unit - 1DeepakNo ratings yet
- Data Mining Techniques Unit-1Document122 pagesData Mining Techniques Unit-1Rohan SinghNo ratings yet
- A Survey On Intrusion Detection System Using Machine Learning TechniquesDocument7 pagesA Survey On Intrusion Detection System Using Machine Learning TechniquesIJRASETPublicationsNo ratings yet
- Scalable Neural NetworkDocument31 pagesScalable Neural Networkaryandeo2011No ratings yet
- MainDocument12 pagesMainLEONARDO DAVID HERRERA ZUÑIGANo ratings yet
- Toxic Comment Detection Code Using LSTM: A Project OnDocument11 pagesToxic Comment Detection Code Using LSTM: A Project OnShiva MeenaNo ratings yet
- LSTM: A Search Space Odyssey: Klaus Greff, Rupesh K. Srivastava, Jan Koutn Ik, Bas R. Steunebrink, J Urgen SchmidhuberDocument12 pagesLSTM: A Search Space Odyssey: Klaus Greff, Rupesh K. Srivastava, Jan Koutn Ik, Bas R. Steunebrink, J Urgen SchmidhuberStefano Bbc RossiNo ratings yet
- Building A CycleGAN Model Using Tensorflow 2Document9 pagesBuilding A CycleGAN Model Using Tensorflow 2faridasabryNo ratings yet
- The AI Hierarchy of NeedsDocument8 pagesThe AI Hierarchy of NeedsNapoleon QuisumbingNo ratings yet
- Spam Detection ThesisDocument6 pagesSpam Detection Thesiszyxnlmikd100% (2)
- DeepTrading With TensorFlow 3 - TodoTraderDocument10 pagesDeepTrading With TensorFlow 3 - TodoTraderalypatyNo ratings yet
- Lay-Off Analysis & Prediction System-1Document9 pagesLay-Off Analysis & Prediction System-1Param JoshiNo ratings yet
- MLT CAT II (1) (1)Document37 pagesMLT CAT II (1) (1)shivanitamilvanan533068No ratings yet
- Fedeval-Llm: Federated Evaluation of Large Language Models On Downstream Tasks With Collective WisdomDocument17 pagesFedeval-Llm: Federated Evaluation of Large Language Models On Downstream Tasks With Collective Wisdomhoutatsu16No ratings yet
- Project TitleDocument4 pagesProject TitleIezma MadzinNo ratings yet
- Module 3Document13 pagesModule 3aiswaryaprathapan22No ratings yet
- Artificial Intelligence in Drug Design: Alexander Heifetz EditorDocument526 pagesArtificial Intelligence in Drug Design: Alexander Heifetz EditoredgarNo ratings yet