You might also like
- Grade 7 ExamDocument3 pagesGrade 7 ExamMikko GomezNo ratings yet
- Checklist & Guideline ISO 22000Document14 pagesChecklist & Guideline ISO 22000Documentos Tecnicos75% (4)
- Mcom Sem 4 Project FinalDocument70 pagesMcom Sem 4 Project Finallaxmi iyer75% (4)
- Salary Prediction LinearRegressionDocument7 pagesSalary Prediction LinearRegressionYagnesh Vyas100% (1)
- Labpractice 2Document29 pagesLabpractice 2Rajashree Das100% (2)
- Logistic RegressionDocument8 pagesLogistic RegressionNipuniNo ratings yet
- Assignment 4Document5 pagesAssignment 4shellieratheeNo ratings yet
- Aries ProjectDocument6 pagesAries ProjectDivyansh BhadauriaNo ratings yet
- Generative AI Binary ClassificationDocument7 pagesGenerative AI Binary ClassificationCyborg UltraNo ratings yet
- Tutorial 2 - ClusteringDocument6 pagesTutorial 2 - ClusteringGupta Akshay100% (2)
- EDA - Session-4 - Numerical Data AnalysisDocument9 pagesEDA - Session-4 - Numerical Data Analysisjeeshu048No ratings yet
- 06 SeabornDocument13 pages06 SeabornAnonymous 001No ratings yet
- Boosting MllabDocument12 pagesBoosting Mllabbunsglazing135No ratings yet
- Sklearn - Datasets Pandas PD Sklearn - Model - Selection Graphviz Sklearn - Datasets Sklearn Sklearn Sklearn - Metrics Sklearn - Metrics Sklearn - Preprocessing Sklearn - Tree SklearnDocument4 pagesSklearn - Datasets Pandas PD Sklearn - Model - Selection Graphviz Sklearn - Datasets Sklearn Sklearn Sklearn - Metrics Sklearn - Metrics Sklearn - Preprocessing Sklearn - Tree SklearnNguyen Trung ThinhNo ratings yet
- Assignment 11Document7 pagesAssignment 11ankit mahto100% (1)
- malharDL 2 .Ipynb - ColabDocument6 pagesmalharDL 2 .Ipynb - Colabcsae99No ratings yet
- ML Lab-Assignment-5Document8 pagesML Lab-Assignment-5Ajeet SinghNo ratings yet
- Regression: Pyspark - SQLDocument5 pagesRegression: Pyspark - SQLAli AbdiNo ratings yet
- Linearregression 4Document3 pagesLinearregression 4api-559045701No ratings yet
- Content: From Import Import As Import Import Import AsDocument8 pagesContent: From Import Import As Import Import Import Asبشار الحسينNo ratings yet
- Backward && Forward Feature Selection PART-2Document6 pagesBackward && Forward Feature Selection PART-2Gabriel GheorgheNo ratings yet
- Project-Password Strength ClassifierDocument6 pagesProject-Password Strength ClassifierOlalekan SamuelNo ratings yet
- Assignment 6.1Document4 pagesAssignment 6.1dashNo ratings yet
- ML0101EN Clas K Nearest Neighbors CustCat Py v1Document11 pagesML0101EN Clas K Nearest Neighbors CustCat Py v1banicx100% (1)
- Some Important Function of Pandas LibraryDocument24 pagesSome Important Function of Pandas LibraryRania DirarNo ratings yet
- LogisticDocument5 pagesLogisticavnimote121No ratings yet
- Estiven - Hurtado.Santos - Regresión Con Varios AlgoritmosDocument16 pagesEstiven - Hurtado.Santos - Regresión Con Varios AlgoritmosEstiven Hurtado SantosNo ratings yet
- 10 Minutes To PandasDocument19 pages10 Minutes To PandasPraveen KandhalaNo ratings yet
- 19f0217 8B Assignment04Document12 pages19f0217 8B Assignment04Shahid Imran100% (1)
- Brain Tumor ClassificationDocument12 pagesBrain Tumor ClassificationUltra Bloch100% (1)
- TP1 SVMDocument2 pagesTP1 SVMwalid abaidiNo ratings yet
- Rajeshca 2Document5 pagesRajeshca 2V ChintuNo ratings yet
- Linear RegressionDocument15 pagesLinear RegressionNipuniNo ratings yet
- Basri 14002164 Tugas2-Binary PDFDocument4 pagesBasri 14002164 Tugas2-Binary PDFBasri100% (1)
- ML PracticalsDocument11 pagesML Practicals05. Yash DaroleNo ratings yet
- Digit Detection Using CNN 1683226190Document36 pagesDigit Detection Using CNN 1683226190Doruk ŞerbetçioğluNo ratings yet
- Loading The Dataset: 'Churn - Modelling - CSV'Document6 pagesLoading The Dataset: 'Churn - Modelling - CSV'Divyani ChavanNo ratings yet
- Untitled0.ipynb - ColaboratoryDocument5 pagesUntitled0.ipynb - Colaboratorychimatayaswanth555No ratings yet
- 20bce2251 VL2021220503859 Ast02Document10 pages20bce2251 VL2021220503859 Ast02TANMAY MEHROTRANo ratings yet
- Untitled 3Document4 pagesUntitled 3Kagade AjinkyaNo ratings yet
- PandasDocument16 pagesPandaslalkrishna123No ratings yet
- K Nearest NeighboursDocument4 pagesK Nearest Neighboursbunsglazing135No ratings yet
- Chapter 4 - Linear RegressionDocument25 pagesChapter 4 - Linear Regressionanshita100% (1)
- Using A Three Layer Deep Neural Network To Solve An Unsupervised Learning ProblemDocument13 pagesUsing A Three Layer Deep Neural Network To Solve An Unsupervised Learning ProblemShajon PaglaNo ratings yet
- I.P PracticalDocument48 pagesI.P PracticalKavoNo ratings yet
- Know Your Dataset: Season Holiday Weekday Workingday CNT 726 727 728 729 730Document1 pageKnow Your Dataset: Season Holiday Weekday Workingday CNT 726 727 728 729 730SHANTI ROKKANo ratings yet
- Bitcoin Price Prediction 5 - ColaboratoryDocument5 pagesBitcoin Price Prediction 5 - ColaboratorySisay ADNo ratings yet
- Py 13 30Document7 pagesPy 13 30Manuel SigüeñasNo ratings yet
- Assignment No - 6-1Document3 pagesAssignment No - 6-1Sid Chabukswar100% (1)
- Variosalgoritmos - Jupyter NotebookDocument9 pagesVariosalgoritmos - Jupyter NotebookPAULO CESAR CALDERON BERMUDO100% (1)
- Tutorial Pandas Bag-5Document11 pagesTutorial Pandas Bag-5NUR JAYANo ratings yet
- DL 3 KsDocument6 pagesDL 3 KsPriyanshu AgrawalNo ratings yet
- Question 8Document1 pageQuestion 8luong.hng43No ratings yet
- DLL 4Document26 pagesDLL 4Darshil RajNo ratings yet
- CNN Train MnistDocument3 pagesCNN Train Mnistrajbarhuliya65No ratings yet
- Ann 2Document8 pagesAnn 21314 Vishakha JagtapNo ratings yet
- Naive Bayes ProjectDocument5 pagesNaive Bayes ProjectNight MusicNo ratings yet
- Pandas NotesDocument54 pagesPandas NotesSáñtôsh KùmãrNo ratings yet
- Kecerdasan Artifisial Dan Masyarakat - M5Document8 pagesKecerdasan Artifisial Dan Masyarakat - M5Citra LarasatiNo ratings yet
- ArbolesRF UNIDocument3 pagesArbolesRF UNIALISON ELIZABETH HUAPAYA CAYCHONo ratings yet
- La Praktikum m3Document9 pagesLa Praktikum m3Ellga Yunita Nurul AzizahNo ratings yet
- Python Pandas Tutorial: Dataframe, Date Range, Slice What Is Pandas?Document7 pagesPython Pandas Tutorial: Dataframe, Date Range, Slice What Is Pandas?Anish kr SinghNo ratings yet
- Post Appraisal InterviewDocument3 pagesPost Appraisal InterviewNidhi D100% (1)
- My Personal Code of Ethics1Document1 pageMy Personal Code of Ethics1Princess Angel LucanasNo ratings yet
- Salads: 300 Salad Recipes For Rapid Weight Loss & Clean Eating (PDFDrive) PDFDocument1,092 pagesSalads: 300 Salad Recipes For Rapid Weight Loss & Clean Eating (PDFDrive) PDFDebora PanzarellaNo ratings yet
- Opc PPT FinalDocument22 pagesOpc PPT FinalnischalaNo ratings yet
- Playful Homeschool Planner - FULLDocument13 pagesPlayful Homeschool Planner - FULLamandalecuyer88No ratings yet
- Thermally Curable Polystyrene Via Click ChemistryDocument4 pagesThermally Curable Polystyrene Via Click ChemistryDanesh AzNo ratings yet
- Snapdragon 435 Processor Product Brief PDFDocument2 pagesSnapdragon 435 Processor Product Brief PDFrichardtao89No ratings yet
- Tribal Banditry in Ottoman Ayntab (1690-1730)Document191 pagesTribal Banditry in Ottoman Ayntab (1690-1730)Mahir DemirNo ratings yet
- Biological Beneficiation of Kaolin: A Review On Iron RemovalDocument8 pagesBiological Beneficiation of Kaolin: A Review On Iron RemovalValentin GnoumouNo ratings yet
- Oracle Forms & Reports 12.2.1.2.0 - Create and Configure On The OEL 7Document50 pagesOracle Forms & Reports 12.2.1.2.0 - Create and Configure On The OEL 7Mario Vilchis Esquivel100% (1)
- Azimuth Steueung - EngDocument13 pagesAzimuth Steueung - EnglacothNo ratings yet
- Leak Detection ReportDocument29 pagesLeak Detection ReportAnnMarie KathleenNo ratings yet
- MASONRYDocument8 pagesMASONRYJowelyn MaderalNo ratings yet
- Electives - ArchitDocument36 pagesElectives - Architkshitiz singhNo ratings yet
- Arens - Auditing and Assurance Services 15e-2Document17 pagesArens - Auditing and Assurance Services 15e-2Magdaline ChuaNo ratings yet
- Dalasa Jibat MijenaDocument24 pagesDalasa Jibat MijenaBelex ManNo ratings yet
- Product CatalogsDocument12 pagesProduct Catalogscab666No ratings yet
- The Homework Song FunnyDocument5 pagesThe Homework Song Funnyers57e8s100% (1)
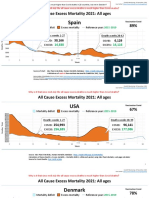
- Countries EXCESS DEATHS All Ages - 15nov2021Document21 pagesCountries EXCESS DEATHS All Ages - 15nov2021robaksNo ratings yet
- Radiation Safety Densitometer Baker PDFDocument4 pagesRadiation Safety Densitometer Baker PDFLenis CeronNo ratings yet
- HirePro Video Proctored Online-Instruction Sheet - Bain IndiaDocument1 pageHirePro Video Proctored Online-Instruction Sheet - Bain Indiaapoorv sharmaNo ratings yet
- Acute Coronary SyndromeDocument30 pagesAcute Coronary SyndromeEndar EszterNo ratings yet
- Linguistics Is Descriptive, Not Prescriptive.: Prescriptive Grammar. Prescriptive Rules Tell You HowDocument2 pagesLinguistics Is Descriptive, Not Prescriptive.: Prescriptive Grammar. Prescriptive Rules Tell You HowMonette Rivera Villanueva100% (1)
- Classifications of AssessmentsDocument11 pagesClassifications of AssessmentsClaire CatapangNo ratings yet
- Fss Presentation Slide GoDocument13 pagesFss Presentation Slide GoReinoso GreiskaNo ratings yet
- 2021-03 Trophy LagerDocument11 pages2021-03 Trophy LagerAderayo OnipedeNo ratings yet
- Richardson Heidegger PDFDocument18 pagesRichardson Heidegger PDFweltfremdheitNo ratings yet