You might also like
- Introduction to Proof in Abstract MathematicsFrom EverandIntroduction to Proof in Abstract MathematicsRating: 5 out of 5 stars5/5 (1)
- Pro-Drop 1989Document23 pagesPro-Drop 1989ka6kaNo ratings yet
- Layman's Transformation of String Theory: Plotting The Arcanum In SpreadsheetsFrom EverandLayman's Transformation of String Theory: Plotting The Arcanum In SpreadsheetsNo ratings yet
- On Operationalizing Syntactic Complexity: Benedikt M. Szmrecs AnyiDocument8 pagesOn Operationalizing Syntactic Complexity: Benedikt M. Szmrecs AnyiDiego GruenfeldNo ratings yet
- Sprouse 07Document12 pagesSprouse 07shamyNo ratings yet
- Osvaldo Jaeggli and Kenneth 1. SafirDocument44 pagesOsvaldo Jaeggli and Kenneth 1. SafirYuri PotiNo ratings yet
- Chomsky On BindingDocument47 pagesChomsky On BindingthangdaotaoNo ratings yet
- Ebert & Koronkiewicz 2018Document42 pagesEbert & Koronkiewicz 2018zzzzz zzzzz zzzzzNo ratings yet
- Chomsky, N. (1980) - Binding PDFDocument47 pagesChomsky, N. (1980) - Binding PDFZhi ChenNo ratings yet
- Modelling Second Language Performance: Integrating Complexity, Accuracy, Fluency, and LexisDocument23 pagesModelling Second Language Performance: Integrating Complexity, Accuracy, Fluency, and LexisenviNo ratings yet
- Carston R Wilson D 2007 A Unitary Approach To Lexical PragmaticsDocument43 pagesCarston R Wilson D 2007 A Unitary Approach To Lexical PragmaticsAna Cifuentes OrozcoNo ratings yet
- Chomsky - Studies On Semantics in Generative GrammarDocument103 pagesChomsky - Studies On Semantics in Generative Grammardharmavid100% (2)
- Defining language constructs CAFDocument12 pagesDefining language constructs CAFAhmadNo ratings yet
- Comparing and Combining Semantic Verb ClassificationsDocument34 pagesComparing and Combining Semantic Verb ClassificationsDiniNo ratings yet
- 3 Converging Evidence II: More On The Association of Verbs and ConstructionsDocument14 pages3 Converging Evidence II: More On The Association of Verbs and ConstructionsPaulo PilarNo ratings yet
- Grammaticality, Acceptability, Possible Words and Large Corpora-4Document21 pagesGrammaticality, Acceptability, Possible Words and Large Corpora-4Ντάνιελ ΦωςNo ratings yet
- TCDocument4 pagesTCAhmed Shams AhadNo ratings yet
- Collocation SDocument35 pagesCollocation SmiprofesorjaviNo ratings yet
- DA Marija MilojkovicDocument23 pagesDA Marija MilojkovicMarija MilojkovicNo ratings yet
- Experimental data reveals varying degrees of idiom acceptabilityDocument27 pagesExperimental data reveals varying degrees of idiom acceptabilityصفا منذرNo ratings yet
- Blocking and Paradigm Gaps: Itamar KastnerDocument42 pagesBlocking and Paradigm Gaps: Itamar KastnerLaura StiglianoNo ratings yet
- Reading Complexity Judgments: Episode 1: Gholam Reza Haji Pour NezhadDocument7 pagesReading Complexity Judgments: Episode 1: Gholam Reza Haji Pour Nezhadapi-27788847No ratings yet
- A Framework for Formalising Variable Meaning of Vague TermsDocument18 pagesA Framework for Formalising Variable Meaning of Vague TermsEdilson RodriguesNo ratings yet
- 50-Something Years of Work On CollocationsDocument29 pages50-Something Years of Work On CollocationsCennet EkiciNo ratings yet
- El Lexicón Generativo James PustejovskyDocument34 pagesEl Lexicón Generativo James PustejovskyJoel Arturo Pedraza NicolasNo ratings yet
- Frazier 2004 LinguaDocument25 pagesFrazier 2004 LinguaAmanda MartinezNo ratings yet
- A Probabilistic Constraints Approach To Language Acquisition and ProcessingDocument31 pagesA Probabilistic Constraints Approach To Language Acquisition and ProcessingFirdauz AbdullahNo ratings yet
- Clarifying the Notion of Linguistic ParametersDocument15 pagesClarifying the Notion of Linguistic ParametersAntonio CodinaNo ratings yet
- Acceptability judgments influenced by additivity and working memoryDocument6 pagesAcceptability judgments influenced by additivity and working memoryshivagoleNo ratings yet
- A Semantic Theory of AdverbsDocument27 pagesA Semantic Theory of AdverbsGuillermo GarridoNo ratings yet
- (SFL) Modal ConstructionDocument10 pages(SFL) Modal ConstructionLatifNo ratings yet
- Unit 10 Corpora and Language Studies pt3 - 3Document16 pagesUnit 10 Corpora and Language Studies pt3 - 3MotivatioNetNo ratings yet
- Brandom Dynamics PlainDocument26 pagesBrandom Dynamics PlainbtimNo ratings yet
- The MIT Press American Academy of Arts & Sciences: Info/about/policies/terms - JSPDocument11 pagesThe MIT Press American Academy of Arts & Sciences: Info/about/policies/terms - JSPAbdeljalil ElgourNo ratings yet
- A Bayesian Hybrid Method For Context-Sensitive Spelling CorrectionDocument15 pagesA Bayesian Hybrid Method For Context-Sensitive Spelling CorrectionYash Kumar Singh Jha ae19b016No ratings yet
- Making Sense of Semantic Ambiguity in Lexical AccessDocument15 pagesMaking Sense of Semantic Ambiguity in Lexical AccessMay LenyNo ratings yet
- ChomskyDocument48 pagesChomskyJunitia Dewi VoaNo ratings yet
- Resolving Word Meanings in IRDocument8 pagesResolving Word Meanings in IRPaslas CisurupanNo ratings yet
- Weak vs. Strong Definite Articles: Meaning and Form Across LanguagesDocument38 pagesWeak vs. Strong Definite Articles: Meaning and Form Across LanguagesẢnh MaiNo ratings yet
- Variation MorphosyntaxDocument20 pagesVariation Morphosyntaxkatharina metaNo ratings yet
- The Generative LexiconDocument33 pagesThe Generative LexiconLaura StiglianoNo ratings yet
- Experimenting With Wh-Movement in Spanish PDFDocument9 pagesExperimenting With Wh-Movement in Spanish PDFZuriñe Frías CobiánNo ratings yet
- Computational Analysis - Building A Shared World - Mapping Distributional To Model-Theoretic Semantic Spaces - 2015Document11 pagesComputational Analysis - Building A Shared World - Mapping Distributional To Model-Theoretic Semantic Spaces - 2015Chris TanasescuNo ratings yet
- Learning Expressive Models For Word Sense Disambiguation: Lucia Specia Mark Stevenson Maria Das Graças V. NunesDocument8 pagesLearning Expressive Models For Word Sense Disambiguation: Lucia Specia Mark Stevenson Maria Das Graças V. Nunesmusic2850No ratings yet
- An Introduction To Optimality Theory in SyntaxDocument21 pagesAn Introduction To Optimality Theory in Syntaxfarah JallowNo ratings yet
- Reseña Whyonly Us, Language and Evolution 10 - 92.4progovacDocument5 pagesReseña Whyonly Us, Language and Evolution 10 - 92.4progovacpihuma4176No ratings yet
- 1 PBDocument16 pages1 PBAhmad Rama RamadhanNo ratings yet
- 601 Chap2Document70 pages601 Chap2Akinlabi OyindamolaNo ratings yet
- Word Order Acceptability and Choice in GermanDocument18 pagesWord Order Acceptability and Choice in GermanViktória ČechotovskáNo ratings yet
- Cutler 1983 Lexical ComplexityDocument37 pagesCutler 1983 Lexical ComplexitymarcosNo ratings yet
- Modelos Actuales de AgreeDocument34 pagesModelos Actuales de AgreeCésar RamosNo ratings yet
- Chen Main Josh IDocument8 pagesChen Main Josh Ibobster124uNo ratings yet
- English and French Causal Connectives in Contrast: Sandrine Zufferey and Bruno CartoniDocument19 pagesEnglish and French Causal Connectives in Contrast: Sandrine Zufferey and Bruno CartoniNgọc Trân PhanNo ratings yet
- Contrastive Linguistics-Translation Studies-Machine TranslationsDocument53 pagesContrastive Linguistics-Translation Studies-Machine Translationsneed_information100% (1)
- Shifting Variation - Érica. García (1985)Document36 pagesShifting Variation - Érica. García (1985)Olga Roxana RiscoNo ratings yet
- (2014) (Ronan) Light Verb Constructions in The History of English PDFDocument20 pages(2014) (Ronan) Light Verb Constructions in The History of English PDFjoseNo ratings yet
- Contractions DraftDocument68 pagesContractions DraftjumanNo ratings yet
- Bridging approaches based on truth, coherence and relevanceDocument28 pagesBridging approaches based on truth, coherence and relevanceAndreea-Raluca ManeaNo ratings yet
- The syntax and pragmatics of embedded yes/no questionsDocument20 pagesThe syntax and pragmatics of embedded yes/no questionsSara EldalyNo ratings yet
- A-Maze of Natural Stories Comprehension and SurpriDocument34 pagesA-Maze of Natural Stories Comprehension and Surprir4980201No ratings yet
- Grammar in The Law PDFDocument8 pagesGrammar in The Law PDFdinadinicNo ratings yet
- GG 54 Dys 102014 560 BDocument1 pageGG 54 Dys 102014 560 BThe palitana PatrikaNo ratings yet
- In The High Court of Gujarat at Ahmedabad Special Civil Application No. 16442 of 2017Document1 pageIn The High Court of Gujarat at Ahmedabad Special Civil Application No. 16442 of 2017The palitana PatrikaNo ratings yet
- D - 2017 GJHC240116962017 201Document2 pagesD - 2017 GJHC240116962017 201The palitana PatrikaNo ratings yet
- ST - Joseph's College of Engineering 1 ISO 9001:2008Document18 pagesST - Joseph's College of Engineering 1 ISO 9001:2008PurushothamNo ratings yet
- Proprties of MatterDocument24 pagesProprties of Matterrishithhr rajeevNo ratings yet
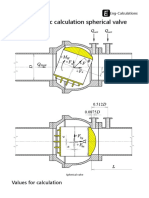
- Hydrodynamic Calculation Spherical ValveDocument34 pagesHydrodynamic Calculation Spherical ValveEng-CalculationsNo ratings yet
- Research - Grade 12Document4 pagesResearch - Grade 12JJ Angelo ChongNo ratings yet
- GECMAT Assignment 3Document9 pagesGECMAT Assignment 3Rheysalyn Mae DespiNo ratings yet
- Estadio de NollaDocument13 pagesEstadio de NollaCATALINA VASQUEZ LOPEZ100% (1)
- Btech Mech 7 Sem Mechanical Vibration Pme7j001 2020Document3 pagesBtech Mech 7 Sem Mechanical Vibration Pme7j001 2020Soumya SanjibNo ratings yet
- Super Cheatsheet Deep LearningDocument13 pagesSuper Cheatsheet Deep LearningcidsantNo ratings yet
- Notes For Abstract AlgebraDocument2 pagesNotes For Abstract AlgebraSankalp ChauhanNo ratings yet
- Find the equation of a parabola given its focus and directrixDocument1 pageFind the equation of a parabola given its focus and directrixpeteNo ratings yet
- 9709 w15 Ms 42Document7 pages9709 w15 Ms 42yuke kristinaNo ratings yet
- Consolidation by FEM PDFDocument25 pagesConsolidation by FEM PDFAstrid AubryNo ratings yet
- Conservation of Energy LabDocument6 pagesConservation of Energy LabAneesh Malhotra0% (1)
- CH 6 Fungsi TransferDocument13 pagesCH 6 Fungsi TransferMuhammad Abdul JamilNo ratings yet
- I-Day 35Document3 pagesI-Day 35Rainman InsanityNo ratings yet
- Oil-Base Mud Contamination in Gas-Condensate SamplesDocument67 pagesOil-Base Mud Contamination in Gas-Condensate SamplesJesseNo ratings yet
- Analysis of The Influence of Price Perceptions, Product Quality and E-WOM On Purchasing Decisions at Shopee With Trust As MediationDocument10 pagesAnalysis of The Influence of Price Perceptions, Product Quality and E-WOM On Purchasing Decisions at Shopee With Trust As MediationInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- RT MDocument6 pagesRT MShikhar NigamNo ratings yet
- Torque Equation of Three Phase Induction Motor - Electrical4UDocument14 pagesTorque Equation of Three Phase Induction Motor - Electrical4Ukaustav choudhuryNo ratings yet
- NAVIFORCE Watch Catalogue in USD - Updated in 20240104Document47 pagesNAVIFORCE Watch Catalogue in USD - Updated in 20240104Perez PerezNo ratings yet
- PML Basics PDFDocument90 pagesPML Basics PDFJorge Enrique Reyes SztayzelNo ratings yet
- GloveDocument10 pagesGlovetareqeee15100% (1)
- Reflection with MirrorsDocument4 pagesReflection with MirrorsSenenNo ratings yet
- Automatically allocate planned and actual indirect activities using keysDocument4 pagesAutomatically allocate planned and actual indirect activities using keysSudharsan PonnambalamNo ratings yet
- Practice ProblemsDocument4 pagesPractice ProblemsPalash dasNo ratings yet
- DLL Mathematics-6 Q3 W6Document10 pagesDLL Mathematics-6 Q3 W6Sheryl Ilagan Del RosarioNo ratings yet
- Iaetsd-Searl Effect PDFDocument7 pagesIaetsd-Searl Effect PDFiaetsdiaetsdNo ratings yet
- Mechanical Measurements and Control System-1-194 - 1-97 PDFDocument97 pagesMechanical Measurements and Control System-1-194 - 1-97 PDFElangoNo ratings yet
- Euler Master Us All PDFDocument2 pagesEuler Master Us All PDFBenNo ratings yet
- Work - Energy - PowerDocument9 pagesWork - Energy - PowermaryNo ratings yet
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormFrom EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormRating: 5 out of 5 stars5/5 (5)
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsFrom EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsRating: 4.5 out of 5 stars4.5/5 (3)
- Calculus Workbook For Dummies with Online PracticeFrom EverandCalculus Workbook For Dummies with Online PracticeRating: 3.5 out of 5 stars3.5/5 (8)
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.From EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Rating: 5 out of 5 stars5/5 (1)
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeFrom EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeRating: 4 out of 5 stars4/5 (2)
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingFrom EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingRating: 4.5 out of 5 stars4.5/5 (21)
- Mental Math Secrets - How To Be a Human CalculatorFrom EverandMental Math Secrets - How To Be a Human CalculatorRating: 5 out of 5 stars5/5 (3)
- Strategies for Problem Solving: Equip Kids to Solve Math Problems With ConfidenceFrom EverandStrategies for Problem Solving: Equip Kids to Solve Math Problems With ConfidenceNo ratings yet
- Assessment Prep for Common Core Mathematics, Grade 6From EverandAssessment Prep for Common Core Mathematics, Grade 6Rating: 5 out of 5 stars5/5 (1)