You might also like
- 3 Windowing: 1 Alkuperäinen Signaali Ja Hanning Ikkuna..Document7 pages3 Windowing: 1 Alkuperäinen Signaali Ja Hanning Ikkuna..Jitendra DhimanNo ratings yet
- NVH Fallstudie Frequency AnalysisDocument5 pagesNVH Fallstudie Frequency Analysisreek_bhatNo ratings yet
- Icsps10 WindowDocument4 pagesIcsps10 WindowkondaraNo ratings yet
- Team5 FinalDocument24 pagesTeam5 Finalsathvika pingaliNo ratings yet
- Compression Techniques 12A) Data Compression Using Huffman CodingDocument6 pagesCompression Techniques 12A) Data Compression Using Huffman CodingbbmathiNo ratings yet
- Audio and Speech Processing - Prof - Muralikrishna HDocument28 pagesAudio and Speech Processing - Prof - Muralikrishna H123_JENo ratings yet
- Lab # 4Document11 pagesLab # 4Muhammad ZeeshanNo ratings yet
- Welch PSD Estimator Using Winows: SL - No. TitleDocument11 pagesWelch PSD Estimator Using Winows: SL - No. TitleSyeda AmeenaNo ratings yet
- Fourier - VibrationDocument4 pagesFourier - VibrationjjNo ratings yet
- Transactions Briefs: Analog Computation of Wavelet Transform Coefficients in Real-TimeDocument4 pagesTransactions Briefs: Analog Computation of Wavelet Transform Coefficients in Real-TimeHair MorenoNo ratings yet
- Generating artificial earthquake motions from response spectraDocument8 pagesGenerating artificial earthquake motions from response spectraAngel J. AliceaNo ratings yet
- PSCDocument4 pagesPSCkattaswamyNo ratings yet
- PSDDocument15 pagesPSDgarg_arpitNo ratings yet
- Signal Processing Onramp Quick ReferenceDocument6 pagesSignal Processing Onramp Quick ReferenceEugenio Tabilog IIINo ratings yet
- SSBoll 79Document4 pagesSSBoll 79Thanh Trung BuiNo ratings yet
- Desired Order Continuous Polynomial Time Window Functions For Harmonic AnalysisDocument7 pagesDesired Order Continuous Polynomial Time Window Functions For Harmonic AnalysisMurthy MandalikaNo ratings yet
- Swerleins AlgorithmDocument14 pagesSwerleins AlgorithmnomeNo ratings yet
- Lab 4Document8 pagesLab 4majjjiNo ratings yet
- Linear PredictionDocument5 pagesLinear PredictionFanfan16No ratings yet
- D Com Experiment 03Document11 pagesD Com Experiment 03Salim KhanNo ratings yet
- MATLAB Exercise - AMDF CalculationDocument5 pagesMATLAB Exercise - AMDF CalculationNiravSinghDabhiNo ratings yet
- Lab 10 (Open Ended Lab) SolvedDocument13 pagesLab 10 (Open Ended Lab) SolvedEaman SafdarNo ratings yet
- 01 SoftwareDocument4 pages01 SoftwareKamal Cruz LeNo ratings yet
- Me'Scopeves Application Note #1: The FFT, Leakage, and WindowingDocument8 pagesMe'Scopeves Application Note #1: The FFT, Leakage, and Windowingho-faNo ratings yet
- Documentatie PT A Scrie Aplicatii Analize MatlabDocument19 pagesDocumentatie PT A Scrie Aplicatii Analize MatlabAlin ArgeseanuNo ratings yet
- A4: Short-Time Fourier Transform (STFT) : Audio Signal Processing For Music ApplicationsDocument6 pagesA4: Short-Time Fourier Transform (STFT) : Audio Signal Processing For Music ApplicationsjcvoscribNo ratings yet
- Lab 03Document7 pagesLab 03Pitchaya Myotan EsNo ratings yet
- Power SpectraDocument3 pagesPower SpectraherfusNo ratings yet
- DSP Lab Manual Final FinalDocument89 pagesDSP Lab Manual Final FinalTaskeen JunaidNo ratings yet
- DSP Lab 3Document18 pagesDSP Lab 3syeddanishali4321No ratings yet
- Laboratory Report On Open-Ended Experiment-2 (Experiment-10)Document9 pagesLaboratory Report On Open-Ended Experiment-2 (Experiment-10)idk bruhNo ratings yet
- Rectangular Waveguide Through MatlabDocument6 pagesRectangular Waveguide Through MatlabSaloni AgarwalNo ratings yet
- Acoustic Echo Cancellation (AEC) - MATLAB & SimulinkDocument13 pagesAcoustic Echo Cancellation (AEC) - MATLAB & SimulinkMekuanent AmareNo ratings yet
- Digital Signal Processing Lab ReportDocument15 pagesDigital Signal Processing Lab ReportSankalp SharmaNo ratings yet
- DC Lab FileDocument28 pagesDC Lab FileKrish JainNo ratings yet
- AudioDocument2 pagesAudiowalikarim73No ratings yet
- Matlab Signal Processing ExamplesDocument20 pagesMatlab Signal Processing ExamplesKunchala AnilNo ratings yet
- Matlab Tutorial 2Document7 pagesMatlab Tutorial 2Shivram TabibuNo ratings yet
- The Time Domain Plot Shown Below Comes From 50 000 Values Recorded Every 2Document15 pagesThe Time Domain Plot Shown Below Comes From 50 000 Values Recorded Every 2Arnaud GirinNo ratings yet
- Mini Project Group 38Document23 pagesMini Project Group 38VijayNo ratings yet
- Efficient LED Control via Signal ProcessingDocument15 pagesEfficient LED Control via Signal ProcessingBryan LohNo ratings yet
- Software Defined Radio Lec 7 - Digital Generation of SignalsDocument24 pagesSoftware Defined Radio Lec 7 - Digital Generation of SignalsYermakov Vadim IvanovichNo ratings yet
- Aliasing Effects in Time and Frequency DomainDocument13 pagesAliasing Effects in Time and Frequency Domainaffan haqNo ratings yet
- The MathWorks - Demos - Dual-Tone Multi-Frequency (DTMF) Signal DetectionDocument4 pagesThe MathWorks - Demos - Dual-Tone Multi-Frequency (DTMF) Signal DetectionWinsweptNo ratings yet
- Ece603 Unified Electronics Laboratory Lab ManualDocument39 pagesEce603 Unified Electronics Laboratory Lab ManualSuneel JaganNo ratings yet
- Comparative Analysis Between DWT and WPD Techniques of Speech CompressionDocument9 pagesComparative Analysis Between DWT and WPD Techniques of Speech CompressionIOSRJEN : hard copy, certificates, Call for Papers 2013, publishing of journalNo ratings yet
- A New Silence Removal and Endpoint Detection Algorithm For Speech and Speaker Recognition ApplicationsDocument5 pagesA New Silence Removal and Endpoint Detection Algorithm For Speech and Speaker Recognition ApplicationsEng SmsmaNo ratings yet
- Ec 6511 Digital Signal Processing Lab ManualDocument88 pagesEc 6511 Digital Signal Processing Lab ManualSelva GanapathyNo ratings yet
- Programming Real-Time Embedded Systems - EPFLDocument40 pagesProgramming Real-Time Embedded Systems - EPFLKhoa NguyenNo ratings yet
- Yogendra Singh Rajpoot (1883930050) DSP FILEDocument42 pagesYogendra Singh Rajpoot (1883930050) DSP FILEYogendra Singh RajpootNo ratings yet
- Implementing FDTD TutorialDocument8 pagesImplementing FDTD Tutorialjohnnypie7No ratings yet
- Analysis and Synthesis of Speech Using MatlabDocument10 pagesAnalysis and Synthesis of Speech Using Matlabps1188No ratings yet
- Sinusoidal Synthesis of Speech Using MATLABDocument35 pagesSinusoidal Synthesis of Speech Using MATLABAkshay JainNo ratings yet
- Abstract 3. Power Spectral Density 4. Welch Method 5. Result 6. ConclusionDocument10 pagesAbstract 3. Power Spectral Density 4. Welch Method 5. Result 6. ConclusionSyeda AmeenaNo ratings yet
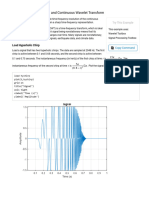
- Time-Frequency Analysis and Continuous Wavelet Transform - MATLAB & SimulinkDocument11 pagesTime-Frequency Analysis and Continuous Wavelet Transform - MATLAB & SimulinkmechsoftservicesNo ratings yet
- Digital Modulations using MatlabFrom EverandDigital Modulations using MatlabRating: 4 out of 5 stars4/5 (6)
- Digital and Kalman Filtering: An Introduction to Discrete-Time Filtering and Optimum Linear Estimation, Second EditionFrom EverandDigital and Kalman Filtering: An Introduction to Discrete-Time Filtering and Optimum Linear Estimation, Second EditionNo ratings yet
- Software Radio: Sampling Rate Selection, Design and SynchronizationFrom EverandSoftware Radio: Sampling Rate Selection, Design and SynchronizationNo ratings yet
- Digital Signal Processing: Instant AccessFrom EverandDigital Signal Processing: Instant AccessRating: 3.5 out of 5 stars3.5/5 (2)
- Ds/Cdma Successive Interference Cancellation: M. Winlab, P.O. Box 909 NJ 08855-0909Document10 pagesDs/Cdma Successive Interference Cancellation: M. Winlab, P.O. Box 909 NJ 08855-0909Vijay Shankar PandeyNo ratings yet
- XPol Panel iRCU 698–894 65° 16dBi 0°–10Document2 pagesXPol Panel iRCU 698–894 65° 16dBi 0°–10Romina VargasNo ratings yet
- Seminar ReportDocument21 pagesSeminar ReportKunjesh MehtaNo ratings yet
- Toshiba L630 L635 Laptop SchematicDocument56 pagesToshiba L630 L635 Laptop SchematicAgus Jhon80% (5)
- Configuring OSPF On Non-Broadcast NetworksDocument5 pagesConfiguring OSPF On Non-Broadcast NetworksWally RedsNo ratings yet
- MTI-ENTERPRISE HRB/2021 price quoteDocument1 pageMTI-ENTERPRISE HRB/2021 price quoteMohamad TofanNo ratings yet
- 323-1851-301.r1.2 - OME6500 Security and AdministrationDocument148 pages323-1851-301.r1.2 - OME6500 Security and AdministrationJonatn SilvaNo ratings yet
- PSD1Document8 pagesPSD1Naeem Ali SajadNo ratings yet
- Misuse of ReturnLossDocument5 pagesMisuse of ReturnLosschmscemNo ratings yet
- The Link Layer and Lans: Computer Networking: A Top Down ApproachDocument43 pagesThe Link Layer and Lans: Computer Networking: A Top Down ApproachmanaliNo ratings yet
- Naved Alam: CV For The Post of Assistant Professor in Electronics & Communication Engineering DepartmentDocument4 pagesNaved Alam: CV For The Post of Assistant Professor in Electronics & Communication Engineering DepartmentskgroupNo ratings yet
- Ebook - Cisco Router CommandsDocument5 pagesEbook - Cisco Router Commandsapi-383373271% (7)
- Dep LargeDocument621 pagesDep Largevimal_rajkNo ratings yet
- Case Study Nr.1 PDFDocument3 pagesCase Study Nr.1 PDFZemra ImeNo ratings yet
- Web Technology Notes Btech Csvtu 6th SemDocument14 pagesWeb Technology Notes Btech Csvtu 6th SemPari BhandarkarNo ratings yet
- 1 The FutureXNetwork WeldonDocument31 pages1 The FutureXNetwork Weldontony vncNo ratings yet
- BG 30 PDFDocument88 pagesBG 30 PDFp4i9e8r5100% (1)
- Why Upgrade 12-13-16Document23 pagesWhy Upgrade 12-13-16ArturoNo ratings yet
- Ais DebegDocument27 pagesAis DebegIgorNo ratings yet
- Tech Unveiled Cloudran EbookDocument48 pagesTech Unveiled Cloudran EbookgshirkovNo ratings yet
- 4.2 DSC DISTRESS COMMUNICATION Reading Comprehension Book 4.2Document2 pages4.2 DSC DISTRESS COMMUNICATION Reading Comprehension Book 4.2AdiNo ratings yet
- Code Blue AlarmDocument33 pagesCode Blue AlarmfajarNo ratings yet
- AWS Solutions Architect Associate Sample Questions SAA-C03Document5 pagesAWS Solutions Architect Associate Sample Questions SAA-C03charitha waravitaNo ratings yet
- Optimizer® Side-By-Side Dual Polarized Antenna, 1710-2700, 65deg, 17.1-18.3dbi, 1.3M, Vet, 0-12degDocument2 pagesOptimizer® Side-By-Side Dual Polarized Antenna, 1710-2700, 65deg, 17.1-18.3dbi, 1.3M, Vet, 0-12degКЕМТ ПП ДАТАNo ratings yet
- Wireshark 1Document3 pagesWireshark 1Ghani Adi NugrohoNo ratings yet
- CompTIA Premium SY0-401 v2016-04-11 by VCEplus 200q1752qDocument150 pagesCompTIA Premium SY0-401 v2016-04-11 by VCEplus 200q1752qAkanksha VermaNo ratings yet
- CCENT Cheat SheetDocument18 pagesCCENT Cheat SheetJim D'FotoNo ratings yet
- Cisco PTPDocument22 pagesCisco PTPMel7it87No ratings yet
- Teletronik Optical EquipmentDocument20 pagesTeletronik Optical EquipmentosamaokokNo ratings yet
- GTU Audio-Video Systems Course OverviewDocument3 pagesGTU Audio-Video Systems Course OverviewEr Ronak Patel100% (1)