You might also like
- Academic Writing and Publishing with ChatGPT: Writing Research Articles, Dissertations, and Thesis, as well as Tips for Publishing in Academic JournalsFrom EverandAcademic Writing and Publishing with ChatGPT: Writing Research Articles, Dissertations, and Thesis, as well as Tips for Publishing in Academic JournalsNo ratings yet
- Can Linguists Distinguish Between ChatGPT:AI and Human Writing? - A Study of Research Ethics and Academic PublishingDocument12 pagesCan Linguists Distinguish Between ChatGPT:AI and Human Writing? - A Study of Research Ethics and Academic PublishingStalin TrotskyNo ratings yet
- ChatGPT Reading Testing Items 2023Document14 pagesChatGPT Reading Testing Items 2023Phạm Thế NamNo ratings yet
- Futureinternet 15 00192Document24 pagesFutureinternet 15 00192MSR MSRNo ratings yet
- A Proposed Framework For Human-Like Language Processing of ChatGPT in Academic WritingDocument12 pagesA Proposed Framework For Human-Like Language Processing of ChatGPT in Academic WritingM.MahyoobNo ratings yet
- 1 s2.0 S2666920X23000772 MainDocument13 pages1 s2.0 S2666920X23000772 Mainalbertus tuhuNo ratings yet
- A Comprehensive Study of ChatGDocument24 pagesA Comprehensive Study of ChatGkrishnaponrameshNo ratings yet
- Theoritcal FrameworkDocument12 pagesTheoritcal FrameworkMeme maNo ratings yet
- ChattingAboutChatGPT PDFDocument10 pagesChattingAboutChatGPT PDFSrikandaprabanna balanNo ratings yet
- Openai Chatgpt Generated Literature Review: Digital Twin in HealthcareDocument10 pagesOpenai Chatgpt Generated Literature Review: Digital Twin in HealthcareBasavarajuNo ratings yet
- Seminar DevOPS Mohamed Nejjar SS23 03757306Document57 pagesSeminar DevOPS Mohamed Nejjar SS23 03757306Mohamed NejjarNo ratings yet
- ChatGPT ICALT 2023Document6 pagesChatGPT ICALT 2023Simeon IvanovNo ratings yet
- Concerns of ChatGPTDocument6 pagesConcerns of ChatGPTStir DremNo ratings yet
- A Chat (GPT) About The Future of Scientific PublishingDocument3 pagesA Chat (GPT) About The Future of Scientific Publishingraul kesumaNo ratings yet
- Openassistant Conversations - Democratizing Large Language Model AlignmentDocument44 pagesOpenassistant Conversations - Democratizing Large Language Model AlignmentSigveNo ratings yet
- ResearchPaper ChatGPTDocument10 pagesResearchPaper ChatGPTYeng Yee NgNo ratings yet
- chatgpt-in-and-for-second-language-acquisition-a-call-for-systematic-researchDocument6 pageschatgpt-in-and-for-second-language-acquisition-a-call-for-systematic-researchparawnareman99No ratings yet
- The Intelligent Technical Influence in Chat Generative Pre-Trained among Students for Modern Learning TraitsDocument11 pagesThe Intelligent Technical Influence in Chat Generative Pre-Trained among Students for Modern Learning TraitsSantiago Otero-PotosiNo ratings yet
- Analyzing The Role of Chatgpt As A Writing Assistant at Higher Education Level A Systematic Review 13605Document14 pagesAnalyzing The Role of Chatgpt As A Writing Assistant at Higher Education Level A Systematic Review 13605tom.janvierNo ratings yet
- 1 s2.0 S1075293523000533 MainDocument6 pages1 s2.0 S1075293523000533 Mainyyagmurr440886No ratings yet
- Chatting About Chat GPTDocument9 pagesChatting About Chat GPTrambo kunjumonNo ratings yet
- One-Class Learning for AI-Generated Essay DetectionDocument24 pagesOne-Class Learning for AI-Generated Essay DetectionJosh OcampoNo ratings yet
- Nanomanufacturing 03 00009Document4 pagesNanomanufacturing 03 00009youssef CHAFAINo ratings yet
- The Role of ChatGPT in Scientific Communication: Writing Better Scientific Review ArticlesDocument7 pagesThe Role of ChatGPT in Scientific Communication: Writing Better Scientific Review Articlestom.janvierNo ratings yet
- Unleashing the Potential of Conversational AI Amplifying Chat-GPTs Capabilities and Tackling Technical HurdlesDocument26 pagesUnleashing the Potential of Conversational AI Amplifying Chat-GPTs Capabilities and Tackling Technical HurdlesAnup Kumar PaulNo ratings yet
- ChatGPT in Academic Writing and Publishing A Comprehensive Guide 2023Document52 pagesChatGPT in Academic Writing and Publishing A Comprehensive Guide 2023Freddy FernandezNo ratings yet
- The Great TransformerDocument14 pagesThe Great TransformerjoakinenNo ratings yet
- AI vs. Human - Differentiation Analysis of Scientific Content GenerationDocument18 pagesAI vs. Human - Differentiation Analysis of Scientific Content GenerationSlinoslavNo ratings yet
- ChatGPT Scientific Text ComparisonDocument17 pagesChatGPT Scientific Text ComparisonJiahao MiNo ratings yet
- AI Has Learned To Write Can It Help Teach Students To Write WellDocument25 pagesAI Has Learned To Write Can It Help Teach Students To Write Wellmattgaren9115No ratings yet
- ChatGPT-35_as_writing_assistance_in_students_essaDocument6 pagesChatGPT-35_as_writing_assistance_in_students_essadogeonelove1No ratings yet
- ChatGPTDocument15 pagesChatGPTashimova.danaNo ratings yet
- ChatGPT A Comprehensive Review On Background, Applications, KeyDocument34 pagesChatGPT A Comprehensive Review On Background, Applications, Keybeatzmine20No ratings yet
- 1 s2.0 S2667345223000317 MainDocument10 pages1 s2.0 S2667345223000317 MainSurat PendaNo ratings yet
- A Framework For Cognitive Chatbots Based On Abductiv - 2023 - Cognitive SystemsDocument16 pagesA Framework For Cognitive Chatbots Based On Abductiv - 2023 - Cognitive SystemsJose CaicedoNo ratings yet
- ChatGPT MainText CleanDocument24 pagesChatGPT MainText Cleanclownlegacy2111No ratings yet
- The Use of Chatgpt As A Learning Tool To Improve Foreign Language Writing in A Multilingual and Multicultural ClassroomDocument8 pagesThe Use of Chatgpt As A Learning Tool To Improve Foreign Language Writing in A Multilingual and Multicultural Classroombesjana.memaNo ratings yet
- Software Process Modeling Languages A Systematic Literature ReviewDocument5 pagesSoftware Process Modeling Languages A Systematic Literature ReviewafdtovmhbNo ratings yet
- Navigating The Ethical Landscape Behind ChatgptDocument5 pagesNavigating The Ethical Landscape Behind ChatgptQuoNo ratings yet
- Examining Science Education in Chatgpt: An Exploratory Study of Generative Artificial IntelligenceDocument9 pagesExamining Science Education in Chatgpt: An Exploratory Study of Generative Artificial IntelligenceMr. DhimalNo ratings yet
- Title - Exploring The Cognitive Dynamics of ChatGPT - An Analysis of Language Generation and Interaction PatternsDocument2 pagesTitle - Exploring The Cognitive Dynamics of ChatGPT - An Analysis of Language Generation and Interaction PatternslolileeNo ratings yet
- Human Evaluation of Automatically Generated Text CDocument24 pagesHuman Evaluation of Automatically Generated Text CYunus Emre CoşkunNo ratings yet
- ChatGPT and The Future of Journal Reviews - A Feasibility StudyDocument7 pagesChatGPT and The Future of Journal Reviews - A Feasibility StudykrishnaponrameshNo ratings yet
- Acedemic Integrity in The Age of AIDocument12 pagesAcedemic Integrity in The Age of AIMalvikaNo ratings yet
- A Knowledge-Based Methodology For Building A Conversational Chatbot As An Intelligent TutorDocument13 pagesA Knowledge-Based Methodology For Building A Conversational Chatbot As An Intelligent TutorHang Tran100% (1)
- Summary of ChatGPT Related Research and Perspective Towards TH - 2023 - Meta RadDocument14 pagesSummary of ChatGPT Related Research and Perspective Towards TH - 2023 - Meta RadRiddhesh PatelNo ratings yet
- An Era of ChatGPT As A Significant Futuristic Support Tool A Study On FeaturesDocument8 pagesAn Era of ChatGPT As A Significant Futuristic Support Tool A Study On Featuresbeatzmine20No ratings yet
- ChatGPT A Brief Narrative ReviewDocument18 pagesChatGPT A Brief Narrative ReviewAmzad HossainNo ratings yet
- Gradient Flow Trend 2023 Report FinalDocument16 pagesGradient Flow Trend 2023 Report Finalricardo.santos.mendes3717No ratings yet
- Chat GPT For Professional English Course DevelopmeDocument14 pagesChat GPT For Professional English Course DevelopmeLyly Pc298No ratings yet
- Conversational AI For Natural Language PDocument9 pagesConversational AI For Natural Language PandjelaNo ratings yet
- Introduction and Evolution of ChatGPT A Large Language ModelDocument2 pagesIntroduction and Evolution of ChatGPT A Large Language ModelEvent ConciergeNo ratings yet
- Whatis Chat GPTDocument2 pagesWhatis Chat GPTRahulNo ratings yet
- Manfaat Kecerdasan Buatan ChatGPT Untuk Membantu Penulisan IlmiahDocument7 pagesManfaat Kecerdasan Buatan ChatGPT Untuk Membantu Penulisan Ilmiahsurohman.itkNo ratings yet
- Chat GPT: K.Ruchitha-217Z1A1222 P.Shanthi Sree-217Z1A1241Document8 pagesChat GPT: K.Ruchitha-217Z1A1222 P.Shanthi Sree-217Z1A1241Chinmayee EadunooriNo ratings yet
- Bullshit MienDocument2 pagesBullshit MienSimConicXNo ratings yet
- A Review of ChatGPT Applications in Education MarkDocument22 pagesA Review of ChatGPT Applications in Education Markdarylkaylesantos21No ratings yet
- A Multitask, Multilingual, Multimodal Evaluation of Chatgpt On Reasoning, Hallucination, and InteractivityDocument52 pagesA Multitask, Multilingual, Multimodal Evaluation of Chatgpt On Reasoning, Hallucination, and InteractivityKatherine TranNo ratings yet
- Computer Literature ReviewDocument8 pagesComputer Literature Reviewafdtywqae100% (1)
- Selection of Hazard Evaluation Techniques PDFDocument16 pagesSelection of Hazard Evaluation Techniques PDFdediodedNo ratings yet
- Risk Management Framework and ProcessDocument16 pagesRisk Management Framework and ProcessIuliana T.No ratings yet
- Tle Fos 9 11 q1 WK 7 d1Document6 pagesTle Fos 9 11 q1 WK 7 d1REYMOND SUMAYLONo ratings yet
- 10 - Bus 105 and 107-1Document400 pages10 - Bus 105 and 107-1Alao LateefNo ratings yet
- Status Signalling and Conspicuous Consumption: The Demand For Counterfeit Status GoodDocument5 pagesStatus Signalling and Conspicuous Consumption: The Demand For Counterfeit Status GoodMarliezel CaballeroNo ratings yet
- Thalassemia SyndromesDocument29 pagesThalassemia SyndromesIsaac MwangiNo ratings yet
- FSLDMDocument5 pagesFSLDMaiabbasi9615No ratings yet
- Guardian Reading - Avon Cosmetics Sellers Prosper in AfricaDocument4 pagesGuardian Reading - Avon Cosmetics Sellers Prosper in Africamiguelillo84eireNo ratings yet
- Group 2 - Chapter 3 4Document7 pagesGroup 2 - Chapter 3 4Mira AurumtinNo ratings yet
- Revit For Presentations Graphics That Pop - Class HandoutDocument15 pagesRevit For Presentations Graphics That Pop - Class HandoutAutodesk University100% (1)
- Notes BST - CH 1Document5 pagesNotes BST - CH 1Khushi KashyapNo ratings yet
- BengzonDocument5 pagesBengzonmceline19No ratings yet
- Organic ReactionsDocument73 pagesOrganic ReactionsKrishnaah Doraj100% (1)
- Mark Scheme (Results) : Summer 2018Document22 pagesMark Scheme (Results) : Summer 2018RafaNo ratings yet
- Ambien Withdrawal TreatmentDocument6 pagesAmbien Withdrawal TreatmentSurvival SabariNo ratings yet
- Transits of The Year 2008: Text by Robert HandDocument27 pagesTransits of The Year 2008: Text by Robert HandjasminnexNo ratings yet
- How Film Elements Build TensionDocument2 pagesHow Film Elements Build TensionBangga ErizalNo ratings yet
- Learning Activity Sheet in 3is (Inquiries, Investigation, Immersion)Document5 pagesLearning Activity Sheet in 3is (Inquiries, Investigation, Immersion)Roselyn Relacion LucidoNo ratings yet
- Strict Liability Offences ExplainedDocument7 pagesStrict Liability Offences ExplainedJoseph ClarkNo ratings yet
- Diareea Cronica Constipatia Cronica: Prof. Dr. Mircea DiculescuDocument33 pagesDiareea Cronica Constipatia Cronica: Prof. Dr. Mircea Diculescuasum_1987No ratings yet
- List of Islamic Schools in Toronto To Apply For JobsDocument5 pagesList of Islamic Schools in Toronto To Apply For JobsgetsaifurNo ratings yet
- Agoraphobia - Simmel and Kracauer - Anthony VidlerDocument16 pagesAgoraphobia - Simmel and Kracauer - Anthony VidlerArthur BuenoNo ratings yet
- Automatic Analysis of Annual Financial Reports: A Case StudyDocument11 pagesAutomatic Analysis of Annual Financial Reports: A Case StudyYuliana MargarettaNo ratings yet
- Moon Landing ConspiracyDocument17 pagesMoon Landing ConspiracyElianeSalamNo ratings yet
- Final Addendum to Report on Clergy AbuseDocument2 pagesFinal Addendum to Report on Clergy AbuseJustin BobbyNo ratings yet
- 2 - PaintingDocument26 pages2 - PaintingELLEN MASMODINo ratings yet
- Module 6 - Arabic LiteratureDocument26 pagesModule 6 - Arabic LiteratureFrancis TatelNo ratings yet
- Unit 11 Multiple Correlation: StructureDocument18 pagesUnit 11 Multiple Correlation: StructurePranav ViswanathanNo ratings yet
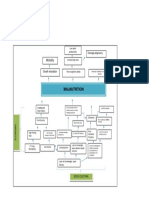
- Problem Tree Analysis MalnutritionDocument1 pageProblem Tree Analysis MalnutritionMho Dsb50% (6)
- Me Desires-Erotic PoetryDocument21 pagesMe Desires-Erotic PoetrygamahucherNo ratings yet
- Empires of the Word: A Language History of the WorldFrom EverandEmpires of the Word: A Language History of the WorldRating: 4 out of 5 stars4/5 (236)
- The Read-Aloud Family: Making Meaningful and Lasting Connections with Your KidsFrom EverandThe Read-Aloud Family: Making Meaningful and Lasting Connections with Your KidsRating: 5 out of 5 stars5/5 (205)
- The Read-Aloud Family: Making Meaningful and Lasting Connections with Your KidsFrom EverandThe Read-Aloud Family: Making Meaningful and Lasting Connections with Your KidsRating: 4.5 out of 5 stars4.5/5 (30)
- The Book Whisperer: Awakening the Inner Reader in Every ChildFrom EverandThe Book Whisperer: Awakening the Inner Reader in Every ChildRating: 4.5 out of 5 stars4.5/5 (56)
- Uncovering the Logic of English: A Common-Sense Approach to Reading, Spelling, and LiteracyFrom EverandUncovering the Logic of English: A Common-Sense Approach to Reading, Spelling, and LiteracyNo ratings yet
- Sight Words 3rd Grade Workbook (Baby Professor Learning Books)From EverandSight Words 3rd Grade Workbook (Baby Professor Learning Books)Rating: 5 out of 5 stars5/5 (1)
- Honey for a Child's Heart Updated and Expanded: The Imaginative Use of Books in Family LifeFrom EverandHoney for a Child's Heart Updated and Expanded: The Imaginative Use of Books in Family LifeRating: 4.5 out of 5 stars4.5/5 (122)
- Wild and Free Book Club: 28 Activities to Make Books Come AliveFrom EverandWild and Free Book Club: 28 Activities to Make Books Come AliveRating: 5 out of 5 stars5/5 (2)
- Essential Phonics For Adults To Learn English Fast: The Only Literacy Program You Will Need to Learn to Read QuicklyFrom EverandEssential Phonics For Adults To Learn English Fast: The Only Literacy Program You Will Need to Learn to Read QuicklyNo ratings yet
- 100 Days to Better English Reading Comprehension: Intermediate-Advanced ESL Reading and Vocabulary LessonsFrom Everand100 Days to Better English Reading Comprehension: Intermediate-Advanced ESL Reading and Vocabulary LessonsNo ratings yet
- Proven Speed Reading Techniques: Read More Than 300 Pages in 1 Hour. A Guide for Beginners on How to Read Faster With Comprehension (Includes Advanced Learning Exercises)From EverandProven Speed Reading Techniques: Read More Than 300 Pages in 1 Hour. A Guide for Beginners on How to Read Faster With Comprehension (Includes Advanced Learning Exercises)Rating: 4 out of 5 stars4/5 (9)
- Proust and the Squid: The Story and Science of the Reading BrainFrom EverandProust and the Squid: The Story and Science of the Reading BrainRating: 3.5 out of 5 stars3.5/5 (278)
- How to Read Poetry Like a Professor: A Quippy and Sonorous Guide to VerseFrom EverandHow to Read Poetry Like a Professor: A Quippy and Sonorous Guide to VerseRating: 4 out of 5 stars4/5 (56)
- Honey for a Child's Heart Updated and Expanded: The Imaginative Use of Books in Family LifeFrom EverandHoney for a Child's Heart Updated and Expanded: The Imaginative Use of Books in Family LifeRating: 4.5 out of 5 stars4.5/5 (106)
- Teach Reading with Orton-Gillingham: 72 Classroom-Ready Lessons to Help Struggling Readers and Students with Dyslexia Learn to Love ReadingFrom EverandTeach Reading with Orton-Gillingham: 72 Classroom-Ready Lessons to Help Struggling Readers and Students with Dyslexia Learn to Love ReadingRating: 5 out of 5 stars5/5 (1)
- ESL Reading Activities For Kids (6-13): Practical Ideas for the ClassroomFrom EverandESL Reading Activities For Kids (6-13): Practical Ideas for the ClassroomRating: 5 out of 5 stars5/5 (2)