You might also like
- Hacking of Computer Networks: Full Course on Hacking of Computer NetworksFrom EverandHacking of Computer Networks: Full Course on Hacking of Computer NetworksNo ratings yet
- PDF Analysis CheatsheetDocument4 pagesPDF Analysis Cheatsheetroot.localhost00No ratings yet
- Analyzing Microsoft Office DocumentsDocument10 pagesAnalyzing Microsoft Office DocumentsThe Hungry QuokkaNo ratings yet
- Extract Hidden Data From PDFDocument2 pagesExtract Hidden Data From PDFNicoleNo ratings yet
- Practical 1Document10 pagesPractical 1tafadzwavictor.chipereNo ratings yet
- Failed To Find PDF File SDFDocument2 pagesFailed To Find PDF File SDFStephenNo ratings yet
- A Pattern Recognition System For Malicious PDF Files DetectionDocument15 pagesA Pattern Recognition System For Malicious PDF Files DetectionReckon IndepthNo ratings yet
- File Analysis Forensics Tools and TechniqueDocument2 pagesFile Analysis Forensics Tools and TechniqueSiddhesh KarekarNo ratings yet
- Malware AnalysisDocument21 pagesMalware AnalysisAyush rawal100% (1)
- PDF MalwareDocument7 pagesPDF MalwareSunil RangaswamyNo ratings yet
- Computer Forensics Based On What I Have Read: Definition of Computer ForensicsDocument4 pagesComputer Forensics Based On What I Have Read: Definition of Computer ForensicsLama Baajour MokdadNo ratings yet
- Welcome To MSIT: Check ListDocument4 pagesWelcome To MSIT: Check ListSuraj NarangNo ratings yet
- Analysing Malicious Microsoft Office and Adobe PDF DocumentsDocument6 pagesAnalysing Malicious Microsoft Office and Adobe PDF DocumentsSanjana chowdaryNo ratings yet
- Fundamentals of Programming AssignmentDocument13 pagesFundamentals of Programming AssignmentMashood AhmadNo ratings yet
- Exploit Js Pdfka IpDocument2 pagesExploit Js Pdfka IpMichaelNo ratings yet
- Lab 3 COMP1475 2018 19Document2 pagesLab 3 COMP1475 2018 19id.xrp.alphaNo ratings yet
- Malware AnalysisDocument15 pagesMalware AnalysisJosue OuattaraNo ratings yet
- Audit PDF / Read PDF With Peepdf - Analyze & Modify PDF FilesDocument2 pagesAudit PDF / Read PDF With Peepdf - Analyze & Modify PDF FilesDongDuongICTNo ratings yet
- Linux System Programming Part 1 - Linux Basics: IBA Bulgaria 2018Document18 pagesLinux System Programming Part 1 - Linux Basics: IBA Bulgaria 2018Калоян ТотевNo ratings yet
- BackdoorDocument15 pagesBackdoortechNo ratings yet
- File HandlingDocument15 pagesFile HandlingMANJUBASHINI.B MIT-AP/CSENo ratings yet
- File PdfboxDocument2 pagesFile PdfboxMatthewNo ratings yet
- eCXD Labs PDFDocument285 pageseCXD Labs PDFRachid Moyse PolaniaNo ratings yet
- Analyzing Malicious Document FilesDocument1 pageAnalyzing Malicious Document Filesmaria jesus gonzalez torresNo ratings yet
- Practical LinuxDocument62 pagesPractical LinuxIsha TripathiNo ratings yet
- 21.2.11 Lab - Encrypting and Decrypting Data Using A Hacker ToolDocument5 pages21.2.11 Lab - Encrypting and Decrypting Data Using A Hacker ToolGee CloudNo ratings yet
- Data Files and Storage (Internal/External Storage) Smart Application DevelopmentDocument21 pagesData Files and Storage (Internal/External Storage) Smart Application DevelopmentDr-Adeel AsgharNo ratings yet
- Exploit PDF 51Document2 pagesExploit PDF 51JessicaNo ratings yet
- Lab 2Document5 pagesLab 2Vadim CiubotaruNo ratings yet
- Ilovepdf MergedDocument12 pagesIlovepdf MergedjercemesquivelNo ratings yet
- Malicious Activity Detection 1697702706Document13 pagesMalicious Activity Detection 1697702706Rishabh JoshiNo ratings yet
- Readme ZyboDocument2 pagesReadme Zyboyassinema1992No ratings yet
- A4 Resume ParserDocument1 pageA4 Resume ParserMunthitra ThadthapongNo ratings yet
- Expose Redacted PDF InformationDocument2 pagesExpose Redacted PDF InformationMoisesNo ratings yet
- 01 Enisa Network Forensics ToolsetDocument32 pages01 Enisa Network Forensics ToolsetMorion BortaNo ratings yet
- Internet Security CheatsheetsDocument8 pagesInternet Security CheatsheetsdinoNo ratings yet
- Corrupt Files - Prof CDocument10 pagesCorrupt Files - Prof CHarley QuinnNo ratings yet
- MOBISEC 2020 - 05 - Real-World Android AppsDocument22 pagesMOBISEC 2020 - 05 - Real-World Android AppsaaaaaaNo ratings yet
- "Hacking With Metasploit" TutorialDocument18 pages"Hacking With Metasploit" TutorialDaniel E. RamosNo ratings yet
- Filetype PDF Intex Google HackingDocument1 pageFiletype PDF Intex Google HackingVictoria100% (1)
- Medium-Com-@peacefDocument8 pagesMedium-Com-@peacefkurashNo ratings yet
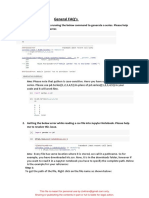
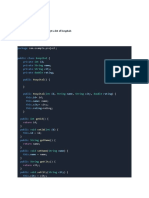
- FAQ PreWorkDocument6 pagesFAQ PreWorkShehroz KhanNo ratings yet
- SANS Analysing Malicious Docs Cheat SheetDocument1 pageSANS Analysing Malicious Docs Cheat SheetagnaldooliNo ratings yet
- Cyber Defense Forensic Analyst - Real World Hands-On ExamplesDocument17 pagesCyber Defense Forensic Analyst - Real World Hands-On ExamplesSandeep Kumar SeeramNo ratings yet
- Hack Like A Pro - How To Embed A Backdoor Connection in An Innocent-Looking PDF Null ByteDocument27 pagesHack Like A Pro - How To Embed A Backdoor Connection in An Innocent-Looking PDF Null ByteDarthFerenczyNo ratings yet
- Analyzing Data Using Python - Importing, Exporting, Analyzing Data With PandasDocument50 pagesAnalyzing Data Using Python - Importing, Exporting, Analyzing Data With Pandasmartin napangaNo ratings yet
- Penetration Testing of Password Protected DocumentsDocument22 pagesPenetration Testing of Password Protected DocumentsulrichkomnNo ratings yet
- Cortex Hands On Investigation and Threat Hunting WorkshopDocument57 pagesCortex Hands On Investigation and Threat Hunting Workshopdbf75No ratings yet
- Python PDF 2: Writing and Manipulating A PDF With Pypdf2 and ReportlabDocument22 pagesPython PDF 2: Writing and Manipulating A PDF With Pypdf2 and ReportlabDuh HuhNo ratings yet
- Filetype PDF ActionscriptDocument2 pagesFiletype PDF ActionscriptTrudellNo ratings yet
- Remote and Local File Inclusion ExplainedDocument6 pagesRemote and Local File Inclusion Explainedanon-4476100% (2)
- Digital Forensics With Kali Lin - Shiva v. N. ParasramDocument536 pagesDigital Forensics With Kali Lin - Shiva v. N. ParasramstroganovborisNo ratings yet
- EHDF Ut2Document12 pagesEHDF Ut2Faizal KhanNo ratings yet
- Linux Basic CommandsDocument34 pagesLinux Basic CommandsBrasil TerraplanistaNo ratings yet
- MR YARN - Lab 2 - Cloud - Updated-V2.0Document22 pagesMR YARN - Lab 2 - Cloud - Updated-V2.0bender1686No ratings yet
- Investigating Windows 10Document6 pagesInvestigating Windows 10api-545804212No ratings yet
- SIN UD1 Activities ENGDocument3 pagesSIN UD1 Activities ENGJOSELUISNo ratings yet
- Explorer PDF Generation Information Disclosure VulnerabilityDocument2 pagesExplorer PDF Generation Information Disclosure VulnerabilityDeniceNo ratings yet
- ITSC203 Lab3bDocument10 pagesITSC203 Lab3bktftj5ydfvNo ratings yet
- Binary FilesDocument10 pagesBinary FilesYashpal MishraNo ratings yet
- Vicomp Blue ReaderDocument14 pagesVicomp Blue ReaderIgi SiviNo ratings yet
- CS441-Lab-04 Node Js BasicsDocument4 pagesCS441-Lab-04 Node Js BasicsMuhammad QubaisNo ratings yet
- Android App DevelopmentDocument26 pagesAndroid App DevelopmentDivyajeet SinghNo ratings yet
- PDF HCP OData Provisioning en USDocument30 pagesPDF HCP OData Provisioning en USsreekanth_seelamNo ratings yet
- Linux 9-16 ExamsDocument14 pagesLinux 9-16 ExamsScribdTranslationsNo ratings yet
- CSS Cheat SheetDocument5 pagesCSS Cheat SheetPeterlogeNo ratings yet
- Dmitri Tsumak BSC ThesisDocument48 pagesDmitri Tsumak BSC Thesismohamed bilhageNo ratings yet
- Jdegtdelete - Allimage/ Jdegtdelete - Allimagekeystr: SyntaxDocument4 pagesJdegtdelete - Allimage/ Jdegtdelete - Allimagekeystr: SyntaxRaveRaveNo ratings yet
- About HTML: Prof. David RossiterDocument8 pagesAbout HTML: Prof. David Rossiterlieth-4No ratings yet
- Breakdown AssistantDocument23 pagesBreakdown AssistantRajat kumarNo ratings yet
- Grade 7 Information TechnologyDocument94 pagesGrade 7 Information Technologysintayhu simeNo ratings yet
- BRKCRS 1452Document90 pagesBRKCRS 1452saqer_11No ratings yet
- Data Sheet 6AV2123-2MB03-0AX0: General InformationDocument9 pagesData Sheet 6AV2123-2MB03-0AX0: General InformationEkanit ChuaykoedNo ratings yet
- Summer Training Report Sample PDFDocument38 pagesSummer Training Report Sample PDFAnita PrasadNo ratings yet
- Building Python Microservices FastapiDocument420 pagesBuilding Python Microservices FastapiJean CarlosNo ratings yet
- TAFJ DistributionDocument11 pagesTAFJ DistributionShaqif Hasan SajibNo ratings yet
- Cheat Sheet - DOM: What Is The DOM?Document3 pagesCheat Sheet - DOM: What Is The DOM?scribd accountNo ratings yet
- Week2 2Document8 pagesWeek2 2Thanh Huyền CaoNo ratings yet
- Updated Manual MWT 2020 5Document87 pagesUpdated Manual MWT 2020 5simNo ratings yet
- Spring Boot Hospital ListDocument25 pagesSpring Boot Hospital ListHemant Kushwaha100% (1)
- ICF 9 1st SummativeDocument2 pagesICF 9 1st Summativeallan tomasNo ratings yet
- Getting Started Documentation: Set Up EnvironmentDocument9 pagesGetting Started Documentation: Set Up EnvironmentAleksNo ratings yet
- R ProgrammingDocument5 pagesR ProgrammingSourav NayakNo ratings yet
- CVE-2020-14882 - Oracle WebLogic Remote Code Execution Vulnerability Exploited in The Wild - Blog - 2020-11-30 - 15-29 - A6151ff9Document933 pagesCVE-2020-14882 - Oracle WebLogic Remote Code Execution Vulnerability Exploited in The Wild - Blog - 2020-11-30 - 15-29 - A6151ff9Alessandro BocchinoNo ratings yet
- Symantec Data Loss Prevention Installation Guide For Linux: Last Updated: September 24, 2020Document105 pagesSymantec Data Loss Prevention Installation Guide For Linux: Last Updated: September 24, 2020artreisNo ratings yet
- Company Overview: IB5k Job Description Full Stack / Ruby DeveloperDocument2 pagesCompany Overview: IB5k Job Description Full Stack / Ruby DeveloperDeneme Deneme AsNo ratings yet
- Subham Chakraborty ResumeDocument1 pageSubham Chakraborty ResumetankuliNo ratings yet
- Lightning and LWC Interview QuestionsDocument9 pagesLightning and LWC Interview QuestionslakshmiumaNo ratings yet
- Akamai Splunk SIEM Splunk ConnectorDocument12 pagesAkamai Splunk SIEM Splunk ConnectorZoumana DiomandeNo ratings yet
- Really Friendly Git IntroDocument26 pagesReally Friendly Git Introscribd1comNo ratings yet