You might also like
- CS252 Graduate Computer Architecture Multithreading / Vector Processing March 2, 2011Document26 pagesCS252 Graduate Computer Architecture Multithreading / Vector Processing March 2, 2011Kotesh DharavathNo ratings yet
- L 5 MulticoreDocument30 pagesL 5 MulticoreLekshmiNo ratings yet
- Hreads: Program Counter: RegistersDocument21 pagesHreads: Program Counter: RegistersRao AtifNo ratings yet
- Lecture12 PDFDocument11 pagesLecture12 PDFsukhna lakeNo ratings yet
- Module 1: PARALLEL AND DISTRIBUTED COMPUTINGDocument65 pagesModule 1: PARALLEL AND DISTRIBUTED COMPUTINGVandana M 19BCE1763No ratings yet
- Simultaneous Multithreading G Architecture: Virendra SinghDocument15 pagesSimultaneous Multithreading G Architecture: Virendra Singhsuresh sNo ratings yet
- OS Threads Unit 3 Copy 1Document34 pagesOS Threads Unit 3 Copy 1Abhinay YadavNo ratings yet
- ThreadsDocument25 pagesThreadsTâm LêNo ratings yet
- EE6304 Lecture12 TLPDocument70 pagesEE6304 Lecture12 TLPAshish SoniNo ratings yet
- Chapter 3 ProcessesDocument42 pagesChapter 3 ProcessesLusi ሉሲNo ratings yet
- Threads: M1 MOSIG - Operating System Design Renaud LachaizeDocument21 pagesThreads: M1 MOSIG - Operating System Design Renaud LachaizeImad IsmailNo ratings yet
- ThreadsDocument47 pagesThreads21PC12 - GOKUL DNo ratings yet
- 2.2 DD2356 ThreadsDocument22 pages2.2 DD2356 ThreadsDaniel AraújoNo ratings yet
- Instruction SchedulingDocument17 pagesInstruction Scheduling934916760No ratings yet
- 4 ThreadsDocument37 pages4 ThreadsAditi VermaNo ratings yet
- Lecture 3Document24 pagesLecture 3Pratik PatelNo ratings yet
- Thread (Operating System)Document17 pagesThread (Operating System)hashimkainatNo ratings yet
- Name: Abubakr & Haseeb Tariq Subject: Operating System Topic: Threads Types & Its IssuesDocument22 pagesName: Abubakr & Haseeb Tariq Subject: Operating System Topic: Threads Types & Its IssuesBilal Khan RindNo ratings yet
- Threads: Basic Theory and Libraries: Unit of Resource OwnershipDocument33 pagesThreads: Basic Theory and Libraries: Unit of Resource OwnershipSudheera PalihakkaraNo ratings yet
- Embedded Systems Overview: - RTOS/EOS Design ConceptDocument19 pagesEmbedded Systems Overview: - RTOS/EOS Design ConceptbravotolitsNo ratings yet
- 05 ThreadsDocument37 pages05 Threadsomnia amirNo ratings yet
- TLPDocument11 pagesTLPUmair KhalidNo ratings yet
- Threads: Covers Chapter#04 From TextbookDocument25 pagesThreads: Covers Chapter#04 From TextbookFootball King'sNo ratings yet
- Data Centre ArchitectureDocument16 pagesData Centre Architecture23mz02No ratings yet
- OS Unit 2Document6 pagesOS Unit 2Study WorkNo ratings yet
- Hardware Accleration For MLDocument26 pagesHardware Accleration For MLSai SumanthNo ratings yet
- Parallel Reservoir Simulation: User CourseDocument54 pagesParallel Reservoir Simulation: User CourseJian YangNo ratings yet
- Multi-Core Programming - Increasing Performance Through Software Multi-ThreadingDocument11 pagesMulti-Core Programming - Increasing Performance Through Software Multi-ThreadingKarthikNo ratings yet
- Threads Unit 3Document22 pagesThreads Unit 3kaushik prajapatiNo ratings yet
- Threads SMP Microkernel 1717827Document38 pagesThreads SMP Microkernel 1717827permasaNo ratings yet
- Threads: What Is A Thread?Document10 pagesThreads: What Is A Thread?Juan martin UribeNo ratings yet
- Threads in Operating SystemDocument103 pagesThreads in Operating SystemMonika SahuNo ratings yet
- ThreadsDocument20 pagesThreadsChandrakanthkp KoteNo ratings yet
- Operating System Lect12Document34 pagesOperating System Lect12gogochor5No ratings yet
- EGIRAFFE Rechner - Und Kommunikationsnetze VO - Bmark - Pruefungsfragenausarbeitung - 2019SSDocument54 pagesEGIRAFFE Rechner - Und Kommunikationsnetze VO - Bmark - Pruefungsfragenausarbeitung - 2019SSМилан МиросавNo ratings yet
- Unit 5Document29 pagesUnit 5Vanathi PriyadharshiniNo ratings yet
- OS Unit - IIDocument74 pagesOS Unit - IIDee ShanNo ratings yet
- Short Notes Operating Systems 1 11Document26 pagesShort Notes Operating Systems 1 11see thaNo ratings yet
- Threads 8Document11 pagesThreads 822je0189No ratings yet
- ThreadsDocument32 pagesThreadsGaurav GrimReaper RoyNo ratings yet
- Distributed SystemsDocument238 pagesDistributed SystemsOTMANE ER-RAGRAGUINo ratings yet
- System Programming - II ThreadsDocument46 pagesSystem Programming - II ThreadsAbdul Samad KhanNo ratings yet
- FPGA and OpenCLDocument31 pagesFPGA and OpenCLalejandro2112No ratings yet
- HPC Module 1Document48 pagesHPC Module 1firebazzNo ratings yet
- Cs837: Adv. Operating Systems: Dr. Mian M.HamayunDocument19 pagesCs837: Adv. Operating Systems: Dr. Mian M.HamayunShah ZaibNo ratings yet
- Simultaneous Multithreading: Pratyusa Manadhata, Vyas Sekar (Pratyus, Vyass) @cs - Cmu.eduDocument4 pagesSimultaneous Multithreading: Pratyusa Manadhata, Vyas Sekar (Pratyus, Vyass) @cs - Cmu.eduPalanikumarNo ratings yet
- Synchronization Public2Document89 pagesSynchronization Public2firefoxextslurperNo ratings yet
- Part 1 - Lecture 2 - Parallel HardwareDocument60 pagesPart 1 - Lecture 2 - Parallel HardwareAhmad AbbaNo ratings yet
- Computer Organization and Architecture Major Advances in ComputersDocument14 pagesComputer Organization and Architecture Major Advances in ComputersFehmi DenguirNo ratings yet
- Lec5 PDFDocument39 pagesLec5 PDFDaltonNo ratings yet
- ThreadsDocument24 pagesThreadsAjay Kumar RNo ratings yet
- Multi Core 15213 Sp07Document67 pagesMulti Core 15213 Sp07Nguyen van TruongNo ratings yet
- CS 3220: Operating Systems: InstructorDocument38 pagesCS 3220: Operating Systems: InstructorZeeshan WasiNo ratings yet
- 09 - Thread Level ParallelismDocument34 pages09 - Thread Level ParallelismSuganya Periasamy50% (2)
- Chapter 04Document20 pagesChapter 04Fauzan PrasetyoNo ratings yet
- Name: Abubakr & Haseeb Tariq Subject: Operating System Topic: Threads Types & Its IssuesDocument20 pagesName: Abubakr & Haseeb Tariq Subject: Operating System Topic: Threads Types & Its IssuesBilal Khan RindNo ratings yet
- Parallelism in MicroprocessorDocument17 pagesParallelism in MicroprocessorTowsifNo ratings yet
- Multi-Core ArchitecturesDocument43 pagesMulti-Core Architecturesvinotd1100% (1)
- SMT and CMP ArchitecturesDocument19 pagesSMT and CMP ArchitecturesChippyVijayanNo ratings yet
- CPHWF CpuDocument15 pagesCPHWF CpuAries Rhay CanonoyNo ratings yet
- Minimum Fee and Quality GuidelinesDocument9 pagesMinimum Fee and Quality GuidelinesLove SagarNo ratings yet
- A Micro-Project Report On ": MotherbordDocument29 pagesA Micro-Project Report On ": MotherbordPratik GadilkarNo ratings yet
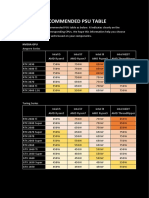
- Recommended Psu TableDocument2 pagesRecommended Psu TableFaisal Fikri HakimNo ratings yet
- Computer1 1st FinalDocument2 pagesComputer1 1st FinaljennifercoNo ratings yet
- Fanuc 21i - B Manual 1Document881 pagesFanuc 21i - B Manual 1umerfarooqNo ratings yet
- TSOP Memory 64/128MBDocument15 pagesTSOP Memory 64/128MBMinh TranNo ratings yet
- F5 6000J3038F16GX2 TZ5NDocument2 pagesF5 6000J3038F16GX2 TZ5Nw800w810No ratings yet
- Partition Wizard User ManualDocument246 pagesPartition Wizard User ManualМаксNo ratings yet
- Computer Storage EvolutionDocument2 pagesComputer Storage EvolutionRics SanchezNo ratings yet
- CPU S1g1 AMD: Dual Channel DDR2 So-Dimm X 2Document63 pagesCPU S1g1 AMD: Dual Channel DDR2 So-Dimm X 2sdsNo ratings yet
- Magz 790 Tomahawkwifiddr 4Document470 pagesMagz 790 Tomahawkwifiddr 4Citizen MNNo ratings yet
- Tiger SHARC ProcessorDocument36 pagesTiger SHARC ProcessorChintan PatelNo ratings yet
- Cpu Scheduling: by Noordiana Binti Kassim at Kasim / Mohd Hanif Bin Jofri / Ceds UthmDocument34 pagesCpu Scheduling: by Noordiana Binti Kassim at Kasim / Mohd Hanif Bin Jofri / Ceds UthmAmir AmjadNo ratings yet
- RJ45 WiringDocument1 pageRJ45 WiringJohn BrensekeNo ratings yet
- NRZI (Non Return To Zero Invert) Encoding & Decoding: (A) General ConceptDocument5 pagesNRZI (Non Return To Zero Invert) Encoding & Decoding: (A) General Conceptkurupati rakeshNo ratings yet
- How To Run CUDA CDocument6 pagesHow To Run CUDA CcseNo ratings yet
- LycanTweaksBuild PropGamingDocument3 pagesLycanTweaksBuild PropGamingBlessing Elohosa Paul IzekorNo ratings yet
- PV Array Combiner Box User Manual: PVS-8M-HV/ PVS-16M-HVDocument43 pagesPV Array Combiner Box User Manual: PVS-8M-HV/ PVS-16M-HVFarrukh MajeedNo ratings yet
- CSC232 - Chp1 (Compatibility Mode)Document50 pagesCSC232 - Chp1 (Compatibility Mode)Hassan HassanNo ratings yet
- Scheme of Work Ss2 First Term: Week Topic Central Processing Unit (CPU)Document13 pagesScheme of Work Ss2 First Term: Week Topic Central Processing Unit (CPU)Daniel ataikimNo ratings yet
- Lenovo V530-15ICB Tower Platform Specifications: Product Specifications Reference (PSREF)Document1 pageLenovo V530-15ICB Tower Platform Specifications: Product Specifications Reference (PSREF)Zsolt SzantoNo ratings yet
- CSS Hand Tools MorphDocument27 pagesCSS Hand Tools MorphJef VegaNo ratings yet
- Using The Swift Futura Remote Video UnitDocument12 pagesUsing The Swift Futura Remote Video UnitReza KühnNo ratings yet
- 8086 - 8088 - 80286 Assembly LanguageDocument408 pages8086 - 8088 - 80286 Assembly LanguagelordpinoyNo ratings yet
- En DM00071990Document239 pagesEn DM00071990Sameh GriraNo ratings yet
- 32 Bit Peripheral Library Guide - NEWDocument324 pages32 Bit Peripheral Library Guide - NEWgem1144aaNo ratings yet
- Chapter 08: Operating Systems and Utility ProgramsDocument27 pagesChapter 08: Operating Systems and Utility ProgramsMuhammad Iqbal Hanafri100% (1)
- TLE 8 Hand ToolsDocument3 pagesTLE 8 Hand ToolsnicoleNo ratings yet
- NX 1175S G8.CleanedDocument2 pagesNX 1175S G8.CleanedAldo Palomino BravoNo ratings yet