You might also like
- How to Defeat Advanced Malware: New Tools for Protection and ForensicsFrom EverandHow to Defeat Advanced Malware: New Tools for Protection and ForensicsNo ratings yet
- 2021A Survey On Windows-Based Ransomware Taxonomy and Detection MechanismsDocument36 pages2021A Survey On Windows-Based Ransomware Taxonomy and Detection Mechanismsaulia rachmaNo ratings yet
- Research Paper 3Document5 pagesResearch Paper 3vijaykrishanmoorthyNo ratings yet
- 805-Article Text-3656-1-10-20220310Document16 pages805-Article Text-3656-1-10-20220310abolfazlshamsNo ratings yet
- Applsci 12 10755 v2Document12 pagesApplsci 12 10755 v2bee927172No ratings yet
- Mal WaresDocument48 pagesMal WaresMohammed HADJ MILOUDNo ratings yet
- 20 - Ransomware Detection Using Machine Learning - A SurveyDocument24 pages20 - Ransomware Detection Using Machine Learning - A SurveylcoqzxnmNo ratings yet
- Applsci 12 12941 v2Document22 pagesApplsci 12 12941 v2CARLOS ALEXIS ALVARADO SILVANo ratings yet
- HELDROIDDocument23 pagesHELDROIDLucas HélioNo ratings yet
- Sensors 22 01837 v2Document19 pagesSensors 22 01837 v2Kiwi NzNo ratings yet
- Machine Learning Algorithms and Frameworks in Ransomware DetectionDocument14 pagesMachine Learning Algorithms and Frameworks in Ransomware DetectionGnan Deep ReddyNo ratings yet
- A Survey On Malware Propagation, Analysis, and DetectionDocument20 pagesA Survey On Malware Propagation, Analysis, and DetectionIJCSDFNo ratings yet
- v1 CoveredDocument10 pagesv1 CoveredimeemkhNo ratings yet
- Static Malware Analysis Using Machine Learning Methods PDFDocument11 pagesStatic Malware Analysis Using Machine Learning Methods PDFMike RomeoNo ratings yet
- Ransomware, Threat and Detection Techniques: A Review: 2. Methodology of Literature ReviewDocument11 pagesRansomware, Threat and Detection Techniques: A Review: 2. Methodology of Literature ReviewNischal LgNo ratings yet
- A Forensic Analysis of Android Malware - How Is Malware Written and How It Could Be Detected?Document5 pagesA Forensic Analysis of Android Malware - How Is Malware Written and How It Could Be Detected?Tharindu RoshanaNo ratings yet
- Ransom WareDocument20 pagesRansom Warert1220011No ratings yet
- "I Was Told To Buy A Software or Lose My Computer. I Ignored It": A Study of RansomwareDocument20 pages"I Was Told To Buy A Software or Lose My Computer. I Ignored It": A Study of RansomwareMohit UpadhyayaNo ratings yet
- Electronics 11 03665 v2Document20 pagesElectronics 11 03665 v2Muhammad Alwan FauzanNo ratings yet
- A3-Static Malware Analysis To Identify Ransomware PropertiesDocument8 pagesA3-Static Malware Analysis To Identify Ransomware PropertiesAleja MoraNo ratings yet
- Research Article: Digital Forensics As Advanced Ransomware Pre-Attack Detection Algorithm For Endpoint Data ProtectionDocument16 pagesResearch Article: Digital Forensics As Advanced Ransomware Pre-Attack Detection Algorithm For Endpoint Data Protectionrosemary lawalNo ratings yet
- Al-Rimy Et Al - COSE - 2018 - Ransomware Threat Success Factors, Taxonomy and Countermeasures A Survey and Research DirectionsDocument23 pagesAl-Rimy Et Al - COSE - 2018 - Ransomware Threat Success Factors, Taxonomy and Countermeasures A Survey and Research DirectionsAleja MoraNo ratings yet
- Abs TrackDocument2 pagesAbs TrackAqil AzNo ratings yet
- The Best Protection at Every Level: Check Point Sandblast Zero-Day ProtectionDocument7 pagesThe Best Protection at Every Level: Check Point Sandblast Zero-Day ProtectionYohan FernandoNo ratings yet
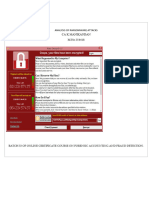
- Analysis of Ransomware AttacksDocument11 pagesAnalysis of Ransomware AttacksDanielleosunfeastNo ratings yet
- IBM Security Ransomware Client Engagement GuideDocument46 pagesIBM Security Ransomware Client Engagement GuideOmarNo ratings yet
- Electronics: Exploring Malware Behavior of Webpages Using Machine Learning Technique: An Empirical StudyDocument20 pagesElectronics: Exploring Malware Behavior of Webpages Using Machine Learning Technique: An Empirical StudyAnandapriya MohantaNo ratings yet
- 15709-Article Text-55876-2-10-20220114Document26 pages15709-Article Text-55876-2-10-20220114Marcel YapNo ratings yet
- Malware-Free Intrusion: A Novel Approach To Ransomware Infection VectorsDocument10 pagesMalware-Free Intrusion: A Novel Approach To Ransomware Infection VectorsNischal LgNo ratings yet
- Crimeware and Malware Based Business SystemsDocument13 pagesCrimeware and Malware Based Business SystemsBrinthapan ParathanNo ratings yet
- (IJETA-V7I5P3) :prateek NigamDocument8 pages(IJETA-V7I5P3) :prateek NigamIJETA - EighthSenseGroupNo ratings yet
- RansomewareDocument7 pagesRansomewarebery mansor osmanNo ratings yet
- 2012 JATIT LeeDocument11 pages2012 JATIT LeeUkAYsNo ratings yet
- Final DraftDocument6 pagesFinal Draftapi-325616189No ratings yet
- An Android Application Sandbox System For Suspicious Software DetectionDocument8 pagesAn Android Application Sandbox System For Suspicious Software DetectionelvictorinoNo ratings yet
- Detecting Ransomware With Alienvault UsmDocument6 pagesDetecting Ransomware With Alienvault UsmKhoa Nguyen Hong NguyenNo ratings yet
- Symmetry 14 02304 With CoverDocument12 pagesSymmetry 14 02304 With CoverIbrahim qashtaNo ratings yet
- Cyber Fraud - Detection and Analysis of The Crypto-RansomwareDocument8 pagesCyber Fraud - Detection and Analysis of The Crypto-RansomwareKuncham GeeteshNo ratings yet
- Malware Detection Using Convolutional Neural Network, A Deep Learning Framework: Comparative AnalysisDocument14 pagesMalware Detection Using Convolutional Neural Network, A Deep Learning Framework: Comparative AnalysisJeevabinding xeroxNo ratings yet
- Review On Malware, Types, and Its AnalysisDocument7 pagesReview On Malware, Types, and Its AnalysisIJRASETPublicationsNo ratings yet
- Cyber Fraud - Detection and Analysis of The Crypto-RansomwareDocument8 pagesCyber Fraud - Detection and Analysis of The Crypto-RansomwareKuncham GeeteshNo ratings yet
- Development of Malware Detection and Analysis ModeDocument50 pagesDevelopment of Malware Detection and Analysis Modejamessabraham2No ratings yet
- AFrameworkforAnalyzingRansomwareusingMachineLearning Con Notas - MHDocument9 pagesAFrameworkforAnalyzingRansomwareusingMachineLearning Con Notas - MHFreddy Daniel Bazante VelozNo ratings yet
- Research AgutiDocument3 pagesResearch AgutiNKINZI BITC2025No ratings yet
- Malware Analysis and Classification SurveyDocument9 pagesMalware Analysis and Classification SurveyHendreson KafodyaNo ratings yet
- An Overview of Social Engineering Malware Trends, Tactics, and ImplicationsDocument14 pagesAn Overview of Social Engineering Malware Trends, Tactics, and ImplicationsHieu TranNo ratings yet
- Multi-Layer Hidden Markov Model Based Intrusion Detection SystemDocument22 pagesMulti-Layer Hidden Markov Model Based Intrusion Detection SystemPramono PramonoNo ratings yet
- Secure For Handheld Devices Against Malicious Software in Mobile NetworksDocument10 pagesSecure For Handheld Devices Against Malicious Software in Mobile NetworksSurya SooriyaNo ratings yet
- U A N L Facultad de Ciencias Fisico MatematicasDocument5 pagesU A N L Facultad de Ciencias Fisico MatematicasAzBlexxNo ratings yet
- RansomwareDocument2 pagesRansomwareAgus TrucidoNo ratings yet
- Evaluating Large Language Models in Ransomware Negotiation A Comparative Analysis of Chat GPT and ClaudeDocument11 pagesEvaluating Large Language Models in Ransomware Negotiation A Comparative Analysis of Chat GPT and ClaudeimeemkhNo ratings yet
- Review On Mobile Threats andDocument9 pagesReview On Mobile Threats andijdpsNo ratings yet
- Malware: Concepts and PrinciplesDocument4 pagesMalware: Concepts and Principleshao gaoNo ratings yet
- Phattapp: A Phishing Attack Detection Application: April 2019Document6 pagesPhattapp: A Phishing Attack Detection Application: April 2019Santosh KBNo ratings yet
- Malware Detection: A Framework For Reverse Engineered Android Applications Through Machine Learning AlgorithmsDocument20 pagesMalware Detection: A Framework For Reverse Engineered Android Applications Through Machine Learning AlgorithmsKarthikeyan KolanjiNo ratings yet
- Mobile Threat Report Q1 2013 PDFDocument26 pagesMobile Threat Report Q1 2013 PDFbairagiNo ratings yet
- Detection and Avoidance of Ransomware: S.Mahmudha Fasheem, P.Kanimozhi, B.AkoramurthyDocument6 pagesDetection and Avoidance of Ransomware: S.Mahmudha Fasheem, P.Kanimozhi, B.AkoramurthyalexusmatrixNo ratings yet
- A Novel Method For Malware Detection On ML-based Visualization TechniqueDocument41 pagesA Novel Method For Malware Detection On ML-based Visualization Techniquejaime_parada3097No ratings yet
- Final Research - MergedDocument10 pagesFinal Research - MergedKANZA AKRAMNo ratings yet
- A Multi-Tier Streaming Analytics Model of 0-Day Ransomware Detection Using Machine LearningDocument23 pagesA Multi-Tier Streaming Analytics Model of 0-Day Ransomware Detection Using Machine LearningZahraaNo ratings yet
- Safeguards Scsem Network AssessmentDocument11 pagesSafeguards Scsem Network AssessmentmanojghorpadeNo ratings yet
- 6.0.1.2 Broadband Varieties InstructionsDocument2 pages6.0.1.2 Broadband Varieties InstructionsCloyd Romeo Villafuerte0% (1)
- Prices and Stocks Subject To Change Without Prior Notice, Please Check With Our Branches. .Document3 pagesPrices and Stocks Subject To Change Without Prior Notice, Please Check With Our Branches. .Kwinsi Agnes Ramirez - Delos ReyesNo ratings yet
- Microsoft Certshared Az-104 Exam Dumps 2022-May-01 by Truman 343q VceDocument29 pagesMicrosoft Certshared Az-104 Exam Dumps 2022-May-01 by Truman 343q VceJohnsonNo ratings yet
- FCM Services FeaturesDocument86 pagesFCM Services FeaturesTing ohn100% (1)
- Le Vieux Negre Et La Medaille PDF 1Document3 pagesLe Vieux Negre Et La Medaille PDF 1Clever Boy50% (2)
- Al55 Cctalk Scheda e Istruz. EngDocument3 pagesAl55 Cctalk Scheda e Istruz. EngProblem VelikiNo ratings yet
- Forest Hydro ExerciseDocument22 pagesForest Hydro ExerciseguilhermefronzaNo ratings yet
- WCF FundamentalsDocument39 pagesWCF FundamentalsAmit TiwariNo ratings yet
- Hadoop Administration Course Content PDFDocument4 pagesHadoop Administration Course Content PDFmarepallyNo ratings yet
- BLK MD Bas232sDocument21 pagesBLK MD Bas232sWinston JaramilloNo ratings yet
- KD21C ManualDocument18 pagesKD21C ManualKay AllgäuNo ratings yet
- Pass4sure: Everything You Need To Prepare, Learn & Pass Your Certification Exam EasilyDocument8 pagesPass4sure: Everything You Need To Prepare, Learn & Pass Your Certification Exam Easilysherif adfNo ratings yet
- Common Logging IN TIBCODocument3 pagesCommon Logging IN TIBCOMaheshitJtc100% (1)
- GlideRecord MethodsDocument33 pagesGlideRecord Methodsabdulkareem12891No ratings yet
- SIM 09 Mill 5AX: Siemens PLM SoftwareDocument15 pagesSIM 09 Mill 5AX: Siemens PLM SoftwareMario MTNo ratings yet
- Fire Event Commands....Document36 pagesFire Event Commands....Juan Carlos RomeroNo ratings yet
- Excel Assignment 3Document2 pagesExcel Assignment 3Sacmca 2017No ratings yet
- Netplan Product Overview: Network Planning and DesignDocument23 pagesNetplan Product Overview: Network Planning and DesignlikameleNo ratings yet
- Recording With AudacityDocument5 pagesRecording With AudacityMilokulaKatoNo ratings yet
- Systems Development and Documentation TechniquesDocument8 pagesSystems Development and Documentation TechniquesNoha KhaledNo ratings yet
- Cambridge International AS & A Level: Computer Science 9618/43 May/June 2021Document30 pagesCambridge International AS & A Level: Computer Science 9618/43 May/June 2021Brandon Chikandiwa100% (1)
- Editar Menu Contextual OperaDocument7 pagesEditar Menu Contextual OperaPedro José Suárez TorrealbaNo ratings yet
- CartconvDocument3 pagesCartconvoldmangoyaNo ratings yet
- Yahoo Data DownloadDocument6 pagesYahoo Data DownloadBruno NevesNo ratings yet
- DPR eDocument19 pagesDPR eHải Dương CT thí nghiệm điệnNo ratings yet
- Microprocessor& Micro ControllerDocument3 pagesMicroprocessor& Micro ControllersujithNo ratings yet
- FTP Exploits by Ankit FadiaDocument18 pagesFTP Exploits by Ankit Fadiapaul_17oct@yahoo.co.inNo ratings yet
- Siemens PLM Whats New in Fibersim 13 Fs Tcm1023 205728Document2 pagesSiemens PLM Whats New in Fibersim 13 Fs Tcm1023 205728rasgeetsinghNo ratings yet
- Course Plan - IMSDocument10 pagesCourse Plan - IMSanmolsupr.officialNo ratings yet
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindFrom EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindNo ratings yet
- Artificial Intelligence: The Insights You Need from Harvard Business ReviewFrom EverandArtificial Intelligence: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (104)
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldFrom EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldRating: 4.5 out of 5 stars4.5/5 (107)
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessFrom EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessNo ratings yet
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveFrom EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveNo ratings yet
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldFrom EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldRating: 4.5 out of 5 stars4.5/5 (55)
- Generative AI: The Insights You Need from Harvard Business ReviewFrom EverandGenerative AI: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (2)
- AI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceFrom EverandAI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceRating: 4 out of 5 stars4/5 (2)
- The AI Advantage: How to Put the Artificial Intelligence Revolution to WorkFrom EverandThe AI Advantage: How to Put the Artificial Intelligence Revolution to WorkRating: 4 out of 5 stars4/5 (7)
- Machine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepFrom EverandMachine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepRating: 4.5 out of 5 stars4.5/5 (19)
- Your AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsFrom EverandYour AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsNo ratings yet
- Midjourney Mastery - The Ultimate Handbook of PromptsFrom EverandMidjourney Mastery - The Ultimate Handbook of PromptsRating: 4.5 out of 5 stars4.5/5 (2)
- HBR's 10 Must Reads on AI, Analytics, and the New Machine AgeFrom EverandHBR's 10 Must Reads on AI, Analytics, and the New Machine AgeRating: 4.5 out of 5 stars4.5/5 (69)
- Who's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesFrom EverandWho's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesRating: 4.5 out of 5 stars4.5/5 (13)
- Demystifying Prompt Engineering: AI Prompts at Your Fingertips (A Step-By-Step Guide)From EverandDemystifying Prompt Engineering: AI Prompts at Your Fingertips (A Step-By-Step Guide)Rating: 4 out of 5 stars4/5 (1)
- Artificial Intelligence: A Guide for Thinking HumansFrom EverandArtificial Intelligence: A Guide for Thinking HumansRating: 4.5 out of 5 stars4.5/5 (30)
- 2084: Artificial Intelligence and the Future of HumanityFrom Everand2084: Artificial Intelligence and the Future of HumanityRating: 4 out of 5 stars4/5 (81)
- Mastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)From EverandMastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)No ratings yet
- Artificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.From EverandArtificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.Rating: 4 out of 5 stars4/5 (15)