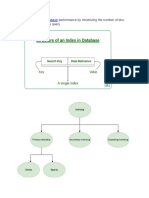
You might also like
- Data Structures Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesFrom EverandData Structures Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNo ratings yet
- Indexing in DBMSDocument5 pagesIndexing in DBMSashxolva23No ratings yet
- Unit-6 Storage StrategiesDocument43 pagesUnit-6 Storage StrategiesShiv PatelNo ratings yet
- IndexingDocument6 pagesIndexingprapadhya uppalapatiNo ratings yet
- Indexing in DBMSDocument12 pagesIndexing in DBMSSravanti BagchiNo ratings yet
- 10 File Organization in DBMSDocument15 pages10 File Organization in DBMSiamchirecNo ratings yet
- CIT 401 Lecture NoteDocument46 pagesCIT 401 Lecture NoteDaniel IzevbuwaNo ratings yet
- CO3 Notes IndexingDocument11 pagesCO3 Notes IndexingNani YagneshwarNo ratings yet
- DBMS QB 5 AnsDocument25 pagesDBMS QB 5 AnsRam AnandNo ratings yet
- What is Indexing in DatabasesDocument7 pagesWhat is Indexing in DatabasesafzhussainNo ratings yet
- Dmbs New Slides Unit 2Document28 pagesDmbs New Slides Unit 2Yasir AhmadNo ratings yet
- Database Index PDFDocument6 pagesDatabase Index PDFAnanya GetahunNo ratings yet
- DBMS Indexing B - Tree To B Tree (197222, 197125, 197155)Document41 pagesDBMS Indexing B - Tree To B Tree (197222, 197125, 197155)VamsiNo ratings yet
- dbms notesDocument21 pagesdbms noteskeisukebajiii18No ratings yet
- Indexes in DatabaseDocument38 pagesIndexes in DatabaseSobia Batool100% (1)
- File Organization MethodsDocument22 pagesFile Organization MethodsAastha ChauhanNo ratings yet
- DBMS Unit VDocument17 pagesDBMS Unit VKeshava VarmaNo ratings yet
- UNITDocument58 pagesUNITK RANJITH REDDYNo ratings yet
- Assignment (DS)Document8 pagesAssignment (DS)Gaurav GuptaNo ratings yet
- Indexing in DBMS - Ordered Indices, Primary Index, Dense Index, Sparse Index, Secondary IndexDocument7 pagesIndexing in DBMS - Ordered Indices, Primary Index, Dense Index, Sparse Index, Secondary Indexkaramthota bhaskar naikNo ratings yet
- IndexesDocument4 pagesIndexesAustin AgbasonNo ratings yet
- What Is An IndexDocument4 pagesWhat Is An IndexNiLa UdayakumarNo ratings yet
- Indexing PDFDocument6 pagesIndexing PDFraysubha123100% (1)
- DBMS - R2017 - Anna UniversityDocument20 pagesDBMS - R2017 - Anna UniversityShanmughapriyaNo ratings yet
- Assignment 3Document4 pagesAssignment 3Navin KumarNo ratings yet
- Inls 623 - Database Systems Ii - File Structures, Indexing, and HashingDocument41 pagesInls 623 - Database Systems Ii - File Structures, Indexing, and HashingAkriti AgrawalNo ratings yet
- Data Structure Database Table Columns of A Database Table LookupsDocument3 pagesData Structure Database Table Columns of A Database Table LookupsRohit KhuranaNo ratings yet
- Introduction Dbms Unit3Document9 pagesIntroduction Dbms Unit3Pawan SharmaNo ratings yet
- SelfUnit2Document18 pagesSelfUnit2Ayush NighotNo ratings yet
- IndeDocument10 pagesIndeRajNo ratings yet
- SQL Server IndexesDocument5 pagesSQL Server Indexesvangappan2No ratings yet
- Unit5 File OrganizationDocument112 pagesUnit5 File OrganizationPinkyNo ratings yet
- A655398144 - 23361 - 19 - 2018 - Database Unit 6Document12 pagesA655398144 - 23361 - 19 - 2018 - Database Unit 6cheppanu dengeyNo ratings yet
- CMP 312Document2 pagesCMP 312vyktoriaNo ratings yet
- 8 UnitDocument25 pages8 UnitRohit kumarNo ratings yet
- Database Indexing Types and StructuresDocument8 pagesDatabase Indexing Types and StructuresVijay KumarNo ratings yet
- DBMS-U5 NotesDocument16 pagesDBMS-U5 NotesMadhulatha 786No ratings yet
- Indexing ImprovesDocument5 pagesIndexing ImprovesAyesha Latif LatifNo ratings yet
- Chap. 2 File Organization and Indexing: Abel J.P. GomesDocument20 pagesChap. 2 File Organization and Indexing: Abel J.P. GomesAbhinav AgnihotriNo ratings yet
- FILE ORGANIZATION IN DBMSDocument10 pagesFILE ORGANIZATION IN DBMSMani MalaNo ratings yet
- ISAM vs Hash IndexingDocument17 pagesISAM vs Hash IndexingPurna Nanda Siva JPNo ratings yet
- How Does Database Indexing WorkDocument4 pagesHow Does Database Indexing WorkSantosh KumarNo ratings yet
- DBMS - File Organization, Indexing and Hashing NotesDocument19 pagesDBMS - File Organization, Indexing and Hashing NotesKomal RamtekeNo ratings yet
- Lesson 4 - IndexingDocument6 pagesLesson 4 - IndexingtholambugollaictNo ratings yet
- Unit 7: Indexing and Hashing: Dhanashree HuddedarDocument26 pagesUnit 7: Indexing and Hashing: Dhanashree HuddedarArchit AnandNo ratings yet
- Dense Indexing Tegneque: in DbmsDocument7 pagesDense Indexing Tegneque: in DbmsFatima IrfanNo ratings yet
- M12 Indexing in DBMSDocument18 pagesM12 Indexing in DBMSNadia AuroraNo ratings yet
- Difference Between Clustered and Non-Clustered IndexDocument7 pagesDifference Between Clustered and Non-Clustered IndexSIDDHANT WAGHANNANo ratings yet
- Prelims 5Document7 pagesPrelims 5Akshata ChopadeNo ratings yet
- SQL Server Index BasicsDocument5 pagesSQL Server Index BasicsshashankniecNo ratings yet
- Data StructureDocument16 pagesData StructurePawan VermaNo ratings yet
- 2Document1 page2mdhanjalah08No ratings yet
- MODULE-5 DBMS CS208 NOTES - Ktuassist - inDocument11 pagesMODULE-5 DBMS CS208 NOTES - Ktuassist - inVaisakh GopinathNo ratings yet
- UNIT-6 Important Questions & AnswersDocument20 pagesUNIT-6 Important Questions & Answerskarumuri mehernadhNo ratings yet
- Indexed Sequential FileDocument2 pagesIndexed Sequential FileStudy MailNo ratings yet
- Single Level IndexingDocument9 pagesSingle Level IndexingNerin ErinNo ratings yet
- NetworksDocument3 pagesNetworksChrispine OtienoNo ratings yet
- DS Question Bank SET-ADocument8 pagesDS Question Bank SET-AMADHULIKA SHARMANo ratings yet
- Ignou Bca Cs 06 Solved Assignment 2012Document10 pagesIgnou Bca Cs 06 Solved Assignment 2012Vikas SengarNo ratings yet
- DB2 ManualDocument82 pagesDB2 ManualSenthill RamasamyNo ratings yet
- Deep LearningDocument45 pagesDeep Learningnigel989No ratings yet
- Com 312 (Database Design)Document6 pagesCom 312 (Database Design)ABDULQUADRI SULAIMANNo ratings yet
- Communication TheoryDocument5 pagesCommunication TheoryJulie Ann GernaNo ratings yet
- 178 hw4 PDFDocument3 pages178 hw4 PDFJonathan NguyenNo ratings yet
- Vip90 - Tailieudacbietdocdien DochieuchudechatgptDocument22 pagesVip90 - Tailieudacbietdocdien DochieuchudechatgptMai NguyễnNo ratings yet
- Image Registration and GeoreferrencingDocument30 pagesImage Registration and GeoreferrencingEd DreadNo ratings yet
- Deep Speech 2: End-to-End Speech Recognition in English and MandarinDocument10 pagesDeep Speech 2: End-to-End Speech Recognition in English and MandarinJose Luis Rojas ArandaNo ratings yet
- AIML 2nd IA Question BankDocument2 pagesAIML 2nd IA Question BankKalyan G VNo ratings yet
- Asymptotic NotationsDocument29 pagesAsymptotic NotationsTejaswi Kariya RathiNo ratings yet
- Kedar Tatwawadi: EducationDocument1 pageKedar Tatwawadi: EducationKiran ModiNo ratings yet
- AI and Firm PerformanceDocument18 pagesAI and Firm PerformancesatthgurujiNo ratings yet
- Precision, Recall and ROC CurvesDocument17 pagesPrecision, Recall and ROC CurvesDr. Maryam ZaffarNo ratings yet
- Chapter 6Document10 pagesChapter 6anon_501297660No ratings yet
- Girma Moges 2020Document83 pagesGirma Moges 2020SamNo ratings yet
- Elements of CommunicationDocument5 pagesElements of CommunicationGerald John Paz0% (1)
- Tied-State HMMs + Introduction To NN-based AMsDocument37 pagesTied-State HMMs + Introduction To NN-based AMsSammy KNo ratings yet
- What Is Ai TechnologyDocument23 pagesWhat Is Ai TechnologyRyan FabianNo ratings yet
- Hybrid Approach For Facial Expression Recognition Using Convolutional Neural Networks and SVMDocument21 pagesHybrid Approach For Facial Expression Recognition Using Convolutional Neural Networks and SVMSTEMM 2022No ratings yet
- EPR-MOGA-XL: Data-Driven Modelling ToolDocument2 pagesEPR-MOGA-XL: Data-Driven Modelling ToolVignesh Kumar NagarajanNo ratings yet
- Techniques For Predictive Modeling: Learning Objectives For Chapter 6Document19 pagesTechniques For Predictive Modeling: Learning Objectives For Chapter 6Captain AyubNo ratings yet
- Syncretism and Hybridization in Contemporary Mexican Art: Nanodrizas and Plantas NómadasDocument22 pagesSyncretism and Hybridization in Contemporary Mexican Art: Nanodrizas and Plantas NómadasGabriela MunguíaNo ratings yet
- Dimension Reduction: P Adraig Cunningham University College DublinDocument24 pagesDimension Reduction: P Adraig Cunningham University College DublinRam VivekNo ratings yet
- SOP-CSE IIT Ropar (PHD)Document2 pagesSOP-CSE IIT Ropar (PHD)Shivam ShuklaNo ratings yet
- Pb2 AI SetADocument5 pagesPb2 AI SetAmethesmrtyNo ratings yet
- FrameworkDocument6 pagesFrameworksounavaaa29138No ratings yet
- Machine Learning: April 2022Document32 pagesMachine Learning: April 2022Rajachandra VoodigaNo ratings yet
- Regression Analysis in Machine Learning - JavatpointDocument1 pageRegression Analysis in Machine Learning - Javatpointleak naNo ratings yet
- Handwritten Digit Recognition Using Convolutional Neural NetworksDocument6 pagesHandwritten Digit Recognition Using Convolutional Neural NetworkssososNo ratings yet
- Brain Tumor Classification Based On Fine-Tuned Models and The Ensemble MethodDocument17 pagesBrain Tumor Classification Based On Fine-Tuned Models and The Ensemble MethodPAVITHRA M 1974312No ratings yet
- Analytical Tuning Method For Cascade Control System Via Multi-Scale Control SchemeDocument26 pagesAnalytical Tuning Method For Cascade Control System Via Multi-Scale Control SchemeFelipe BravoNo ratings yet