You might also like
- Model 255 Aerosol Generator (Metone)Document20 pagesModel 255 Aerosol Generator (Metone)Ali RizviNo ratings yet
- DeliciousDoughnuts Eguide PDFDocument35 pagesDeliciousDoughnuts Eguide PDFSofi Cherny83% (6)
- GPT2 From Scratch in PyTorchDocument13 pagesGPT2 From Scratch in PyTorchRkt SnNo ratings yet
- Keras - Functional APIDocument18 pagesKeras - Functional APInegisid126No ratings yet
- Excercise No. 4: Use Keras To Build An Auto Encoder Model For Dimensionality ReductionDocument4 pagesExcercise No. 4: Use Keras To Build An Auto Encoder Model For Dimensionality ReductionSHIVAM PATILNo ratings yet
- ClassesDocument2 pagesClassesheat massNo ratings yet
- Effects of Batches - Jupyter NotebookDocument73 pagesEffects of Batches - Jupyter Notebookjerry.sharma0312No ratings yet
- Chapter08 - Intro To DL For Computer VisionDocument10 pagesChapter08 - Intro To DL For Computer VisionJas LimNo ratings yet
- Trainina A NN BackpropagationDocument6 pagesTrainina A NN Backpropagationarun_1328No ratings yet
- Font Transfer 2 AutoencodersDocument78 pagesFont Transfer 2 Autoencoderscloud4nrjNo ratings yet
- Back Propogation TrainingDocument6 pagesBack Propogation Trainingarun_1328No ratings yet
- Image Caption2Document9 pagesImage Caption2MANAL BENNOUFNo ratings yet
- CV Project1Document11 pagesCV Project1Girish KumarNo ratings yet
- CodeDocument21 pagesCodefrhenrymatovuNo ratings yet
- Chapter 4 PPTDocument30 pagesChapter 4 PPTidNo ratings yet
- Initializing Input and Batch SizesDocument15 pagesInitializing Input and Batch SizesmkkadambiNo ratings yet
- Tarea - Predecir Dígitos Manuscritos Con SVM RadialDocument5 pagesTarea - Predecir Dígitos Manuscritos Con SVM RadialNuñez Velez MelisaNo ratings yet
- Assignment 3 DS5620Document11 pagesAssignment 3 DS5620humaragptNo ratings yet
- Pytorch 101: Deep Learning PHD Course 2017/2018Document19 pagesPytorch 101: Deep Learning PHD Course 2017/2018jae lynNo ratings yet
- SampleDocument6 pagesSamplewww.santhoshvjd123No ratings yet
- Assignment 2.3.1 Transfer LearningDocument7 pagesAssignment 2.3.1 Transfer LearningHockhin OoiNo ratings yet
- Neural Network With NumpyDocument5 pagesNeural Network With NumpyeduardoNo ratings yet
- Modules in PythonDocument71 pagesModules in PythonRudrik BhattNo ratings yet
- Training and EvaluationDocument20 pagesTraining and Evaluationnegisid126No ratings yet
- Lab 4-Image Segmentation Using U-NetDocument9 pagesLab 4-Image Segmentation Using U-Netmbjanjua35No ratings yet
- AssDocument5 pagesAssTaqwa ElsayedNo ratings yet
- PyTorch Crash Course 1713016363Document15 pagesPyTorch Crash Course 1713016363moussakallaabdoulayeNo ratings yet
- Ds FileDocument58 pagesDs Filetapcom19No ratings yet
- ADS Record ProgramsDocument12 pagesADS Record ProgramskuruvakavyapriyaNo ratings yet
- Installing Spark On Windows EnvironmentDocument16 pagesInstalling Spark On Windows EnvironmentDr Mohammed KamalNo ratings yet
- PythonfileDocument36 pagesPythonfilecollection58209No ratings yet
- Machine LearningDocument54 pagesMachine LearningJacobNo ratings yet
- ADS Record ProgramsDocument11 pagesADS Record ProgramskuruvakavyapriyaNo ratings yet
- Keras CheatSheet PGAADocument1 pageKeras CheatSheet PGAAPooja BhushanNo ratings yet
- Testing in Python - Unit Test & ScriptDocument5 pagesTesting in Python - Unit Test & ScriptE17CN2 ClcNo ratings yet
- Data Mining Assignment No. 1Document22 pagesData Mining Assignment No. 1NIRAV SHAHNo ratings yet
- Design A Neural Network For Classifying Movie ReviewsDocument5 pagesDesign A Neural Network For Classifying Movie Reviewshxd3945No ratings yet
- Pyan NetDocument4 pagesPyan NetnikonsugarNo ratings yet
- New Daa RahulDocument24 pagesNew Daa RahulAbcd XyzNo ratings yet
- Assignment 12Document4 pagesAssignment 12dashNo ratings yet
- Hendra Bayu - 12419795 - Robot M3Document5 pagesHendra Bayu - 12419795 - Robot M3DROKSTORENo ratings yet
- Final Print Py SparkDocument133 pagesFinal Print Py SparkShivaraj KNo ratings yet
- Deep Neural Network - Application 2layerDocument7 pagesDeep Neural Network - Application 2layerGijacis KhasengNo ratings yet
- PhythonDocument19 pagesPhythonKarthikNo ratings yet
- Network - Security LAB-3Document13 pagesNetwork - Security LAB-3SRM AP armyNo ratings yet
- Machine LearningDocument15 pagesMachine Learning5177RAJUNo ratings yet
- What Is The Difference Between Function and Method? Explain The Working of The Init Method With Suitable CodeDocument7 pagesWhat Is The Difference Between Function and Method? Explain The Working of The Init Method With Suitable CodeLikhith MNo ratings yet
- Day26 Class Operator Overloading ParamikoDocument7 pagesDay26 Class Operator Overloading ParamikoArun MmohantyNo ratings yet
- Visualizing Deep Neural Networks Classes and Features - AnkivilDocument58 pagesVisualizing Deep Neural Networks Classes and Features - AnkivilAndres Tuells JanssonNo ratings yet
- MainDocument1 pageMainNicolasNo ratings yet
- QLSTMvs LSTMDocument7 pagesQLSTMvs LSTMmohamedaligharbi20No ratings yet
- Aishwarya MiniProjectReport - SCDocument6 pagesAishwarya MiniProjectReport - SCAtharva Nitin ChandwadkarNo ratings yet
- BIA9Document5 pagesBIA9Daniel GyorfiNo ratings yet
- Capstone Project Report (Digit-Recognition Using CNN)Document11 pagesCapstone Project Report (Digit-Recognition Using CNN)seenuNo ratings yet
- Mark Goldstein mg3479 A2 CodeDocument4 pagesMark Goldstein mg3479 A2 Codejoziah43No ratings yet
- Inept KeyDocument7 pagesInept KeycviggiaNo ratings yet
- IR - 754 All PracticalDocument21 pagesIR - 754 All Practical754Durgesh VishwakarmaNo ratings yet
- Discrete Optimization: Assignments: KnapsackDocument14 pagesDiscrete Optimization: Assignments: KnapsackVictor Mariano LeiteNo ratings yet
- Python CprofileDocument5 pagesPython CprofilekhonelloNo ratings yet
- RECON BRX 2017 r2m2Document73 pagesRECON BRX 2017 r2m2paulNo ratings yet
- Code PDF MergedDocument32 pagesCode PDF MergedShamika ChariNo ratings yet
- FoP HPC Unit IIDocument107 pagesFoP HPC Unit IIAkshata ChopadeNo ratings yet
- HPC Chapter 1Document12 pagesHPC Chapter 1Akshata ChopadeNo ratings yet
- Assignment 3 CustomerDocument3 pagesAssignment 3 CustomerAkshata ChopadeNo ratings yet
- UntitledDocument5 pagesUntitledAkshata ChopadeNo ratings yet
- UntitledDocument1 pageUntitledAkshata ChopadeNo ratings yet
- Assignment No 07Document4 pagesAssignment No 07Akshata ChopadeNo ratings yet
- UntitledDocument2 pagesUntitledAkshata ChopadeNo ratings yet
- Prelims 5Document7 pagesPrelims 5Akshata ChopadeNo ratings yet
- UntitledDocument4 pagesUntitledAkshata ChopadeNo ratings yet
- DBMS NotesDocument6 pagesDBMS NotesAkshata ChopadeNo ratings yet
- Congenital Cardiac Disease: A Guide To Evaluation, Treatment and Anesthetic ManagementDocument87 pagesCongenital Cardiac Disease: A Guide To Evaluation, Treatment and Anesthetic ManagementJZNo ratings yet
- Scholastica: Mock 1Document14 pagesScholastica: Mock 1Fatema KhatunNo ratings yet
- JIS G 3141: Cold-Reduced Carbon Steel Sheet and StripDocument6 pagesJIS G 3141: Cold-Reduced Carbon Steel Sheet and StripHari0% (2)
- Progressive Muscle RelaxationDocument4 pagesProgressive Muscle RelaxationEstéphany Rodrigues ZanonatoNo ratings yet
- ELEVATOR DOOR - pdf1Document10 pagesELEVATOR DOOR - pdf1vigneshNo ratings yet
- Presentation About GyroscopesDocument24 pagesPresentation About GyroscopesgeenjunkmailNo ratings yet
- Final Project Strategic ManagementDocument2 pagesFinal Project Strategic ManagementMahrukh RasheedNo ratings yet
- How To Configure PowerMACS 4000 As A PROFINET IO Slave With Siemens S7Document20 pagesHow To Configure PowerMACS 4000 As A PROFINET IO Slave With Siemens S7kukaNo ratings yet
- How He Loves PDFDocument2 pagesHow He Loves PDFJacob BullockNo ratings yet
- Configuring BGP On Cisco Routers Lab Guide 3.2Document106 pagesConfiguring BGP On Cisco Routers Lab Guide 3.2skuzurov67% (3)
- Business Plan in BDDocument48 pagesBusiness Plan in BDNasir Hossen100% (1)
- A Survey On Security and Privacy Issues of Bitcoin-1Document39 pagesA Survey On Security and Privacy Issues of Bitcoin-1Ramineni HarshaNo ratings yet
- Recitation Math 001 - Term 221 (26166)Document36 pagesRecitation Math 001 - Term 221 (26166)Ma NaNo ratings yet
- Cisco UCS Adapter TroubleshootingDocument90 pagesCisco UCS Adapter TroubleshootingShahulNo ratings yet
- TriPac EVOLUTION Operators Manual 55711 19 OP Rev. 0-06-13Document68 pagesTriPac EVOLUTION Operators Manual 55711 19 OP Rev. 0-06-13Ariel Noya100% (1)
- Lamentation of The Old Pensioner FinalDocument17 pagesLamentation of The Old Pensioner FinalRahulNo ratings yet
- An Annotated Bibliography of Timothy LearyDocument312 pagesAn Annotated Bibliography of Timothy LearyGeetika CnNo ratings yet
- Activity Title: Learning Targets: Reference (S)Document5 pagesActivity Title: Learning Targets: Reference (S)Jhev LeopandoNo ratings yet
- PDFDocument10 pagesPDFerbariumNo ratings yet
- SachinDocument3 pagesSachinMahendraNo ratings yet
- Escaner Electromagnético de Faja Transportadora-Steel SPECTDocument85 pagesEscaner Electromagnético de Faja Transportadora-Steel SPECTEdwin Alfredo Eche QuirozNo ratings yet
- Mosfet Irfz44Document8 pagesMosfet Irfz44huynhsang1979No ratings yet
- (Jones) GoodwinDocument164 pages(Jones) Goodwinmount2011No ratings yet
- Rajiv Gandhi University of Health Sciences, Bengaluru, KarnatakaDocument9 pagesRajiv Gandhi University of Health Sciences, Bengaluru, KarnatakaNavin ChandarNo ratings yet
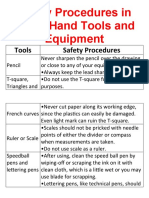
- Safety Procedures in Using Hand Tools and EquipmentDocument12 pagesSafety Procedures in Using Hand Tools and EquipmentJan IcejimenezNo ratings yet
- Rana2 Compliment As Social StrategyDocument12 pagesRana2 Compliment As Social StrategyRanaNo ratings yet
- Acer N300 ManualDocument50 pagesAcer N300 Manualc_formatNo ratings yet
- Triaxial Shear TestDocument10 pagesTriaxial Shear TestAfiqah Nu'aimiNo ratings yet