You might also like
- Digital Booklet - Britney Spears - Work B CH (Single)Document5 pagesDigital Booklet - Britney Spears - Work B CH (Single)Gâu EheheNo ratings yet
- Tree of Qliphoth: Temple of Ascending FlameDocument30 pagesTree of Qliphoth: Temple of Ascending FlameGatuo Angel ToniNo ratings yet
- Crack Studio 5000 Logixrar Sherlock Tools Annih PDFDocument5 pagesCrack Studio 5000 Logixrar Sherlock Tools Annih PDFPerla0% (1)
- TRAIN AI 2018 Andrej Karpathy TeslaDocument83 pagesTRAIN AI 2018 Andrej Karpathy TeslaFred Lamert100% (2)
- Perry's Maternal Child Nursing in CanadaDocument1,620 pagesPerry's Maternal Child Nursing in Canadagilbertwilliams1234No ratings yet
- QSAF0145 B - C-TPAT Internal Audit Report and Checklist - by Department (20191014)Document15 pagesQSAF0145 B - C-TPAT Internal Audit Report and Checklist - by Department (20191014)moctieudinh100% (1)
- Basic Survival Skills Training For Survival GroupsDocument5 pagesBasic Survival Skills Training For Survival GroupsevrazianNo ratings yet
- SIMPACK 代码输出功能Document17 pagesSIMPACK 代码输出功能loeliang100% (1)
- Tuning Solution V16.0.3.0Document16 pagesTuning Solution V16.0.3.0Amine HerbacheNo ratings yet
- Lec16 - AutoencodersDocument18 pagesLec16 - AutoencodersHoàng Anh NguyễnNo ratings yet
- OM Best Practices Guidelines V3.0Document98 pagesOM Best Practices Guidelines V3.0Enrique Balan RomeroNo ratings yet
- Dreamcast Architecture: Architecture of Consoles: A Practical Analysis, #9From EverandDreamcast Architecture: Architecture of Consoles: A Practical Analysis, #9No ratings yet
- Solutions and Solubility Practice Hon-18Document3 pagesSolutions and Solubility Practice Hon-18api-368121935No ratings yet
- Foxboro Ia ManualDocument99 pagesFoxboro Ia ManualLuis Orlando Rios MorenoNo ratings yet
- Airbnb 2018 PDFDocument8 pagesAirbnb 2018 PDFyodhisaputraNo ratings yet
- Chap1 IntroDocument13 pagesChap1 IntroTheophile KafandoNo ratings yet
- Barcode Image Generation LibraryDocument10 pagesBarcode Image Generation LibraryThomas Chinyama100% (2)
- Talk MLSS Part2Document97 pagesTalk MLSS Part2Neetha MaryNo ratings yet
- Object Detection and Recognition: Final Project TitleDocument6 pagesObject Detection and Recognition: Final Project TitleZeyad EtmanNo ratings yet
- Modue 2 - APPLICATIONS OF BPNDocument40 pagesModue 2 - APPLICATIONS OF BPNproject missionNo ratings yet
- CS480 Lecture November 09thDocument69 pagesCS480 Lecture November 09thRajeswariNo ratings yet
- Graphics Library in Java: Seminar Project Under The Guidance ofDocument17 pagesGraphics Library in Java: Seminar Project Under The Guidance ofAmit MaharanaNo ratings yet
- Btech Ec 7 Sem Digital Image Processing Nec 032 2016 17Document3 pagesBtech Ec 7 Sem Digital Image Processing Nec 032 2016 17Deepak SinghNo ratings yet
- Comparison Descartes ContextCaptureEditorDocument1 pageComparison Descartes ContextCaptureEditoroscarcmNo ratings yet
- Interactive Graphical Systems HT2002: What Is Interactive Computer Graphics ?Document12 pagesInteractive Graphical Systems HT2002: What Is Interactive Computer Graphics ?Oyadotun EstherNo ratings yet
- CS 4 IoDocument45 pagesCS 4 IoYousuf AliNo ratings yet
- Image RecognitionDocument47 pagesImage RecognitionFrancis MỹNo ratings yet
- 2023 AN2DL Lez 1 Image ClassificationDocument120 pages2023 AN2DL Lez 1 Image Classificationtripodi216No ratings yet
- Autoencoders - PresentationDocument18 pagesAutoencoders - PresentationPhenil BuchNo ratings yet
- Codejock Xtreme Suite Pro ActiveX 1531 Retail PDFDocument4 pagesCodejock Xtreme Suite Pro ActiveX 1531 Retail PDFBenNo ratings yet
- PackersDocument6 pagesPackersopenid_9V8YnhpL0% (1)
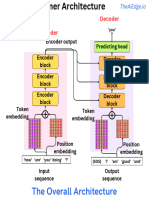
- The Transformer ArchitectureDocument9 pagesThe Transformer Architecturealexandre albalustroNo ratings yet
- Neural Networks - III: ICT3212 - Introduction To Intelligence Systems COM3303 - Artificial IntelligenceDocument44 pagesNeural Networks - III: ICT3212 - Introduction To Intelligence Systems COM3303 - Artificial IntelligencesowmiyaselvarajahNo ratings yet
- Task 1 Task 2 Task 3Document2 pagesTask 1 Task 2 Task 3Rameshkumar JayaramanNo ratings yet
- Ch10. Auto-Encoders: KH WongDocument104 pagesCh10. Auto-Encoders: KH WongOs MNo ratings yet
- C. George and JobDocument1 pageC. George and JobbnuihnNo ratings yet
- Algorithms and Data StructuresDocument29 pagesAlgorithms and Data StructuresErwin AcedilloNo ratings yet
- 2023 AN2DL Lez 3 CNN TL Data ScarcityDocument121 pages2023 AN2DL Lez 3 CNN TL Data Scarcitytripodi216No ratings yet
- C (Console I-O)Document8 pagesC (Console I-O)deep11680No ratings yet
- Graficas PDFDocument1 pageGraficas PDFCarlos Alberto GonzalezNo ratings yet
- Codejock Xtreme Toolkit Pro V16 Full Source RetailDocument3 pagesCodejock Xtreme Toolkit Pro V16 Full Source RetailsopianviaNo ratings yet
- Optical Character Recognation: Hakan AYKULU 20083263 Department of Computer EngineeringDocument10 pagesOptical Character Recognation: Hakan AYKULU 20083263 Department of Computer EngineeringHakan AykuluNo ratings yet
- The Technology Behind Playstation 2Document44 pagesThe Technology Behind Playstation 2romi hendrixNo ratings yet
- Myelin Foundry Pvt. LTDDocument12 pagesMyelin Foundry Pvt. LTDKady YadavNo ratings yet
- Steps in The ProcessDocument15 pagesSteps in The ProcessJanica Rheanne JapsayNo ratings yet
- LogicDesign 8 2Document21 pagesLogicDesign 8 2hwangmbwNo ratings yet
- CMG软件培训讲义 (三) BuilderDocument46 pagesCMG软件培训讲义 (三) BuilderjalestNo ratings yet
- Adobe After Effects CC 2014 64 Bit Crack VR ChingLiu Rar PDFDocument2 pagesAdobe After Effects CC 2014 64 Bit Crack VR ChingLiu Rar PDFJulieNo ratings yet
- Pygame Zero: e e R Z oDocument13 pagesPygame Zero: e e R Z ohetland vanhooglandNo ratings yet
- Pygame Zero: e e R Z oDocument13 pagesPygame Zero: e e R Z ohetland vanhooglandNo ratings yet
- Lecture Slides For Chapter 1 of Deep Learning Ian Goodfellow 2016-09-26Document13 pagesLecture Slides For Chapter 1 of Deep Learning Ian Goodfellow 2016-09-26Indra Kelana JayaNo ratings yet
- MachineLearningSlides PartOneDocument252 pagesMachineLearningSlides PartOneHasitha mNo ratings yet
- Features and Character Classifier: The Components That Made Tesseract SuccessfulDocument29 pagesFeatures and Character Classifier: The Components That Made Tesseract SuccessfulLuis Alberto Lamas LavinNo ratings yet
- Patricia Huanca MamaniDocument13 pagesPatricia Huanca MamaniPatricia MamaniNo ratings yet
- Study Materials - Denoising AutoencodersDocument7 pagesStudy Materials - Denoising AutoencodersDhaarani PushpamNo ratings yet
- SystemC-Tutorial Paderborn PDFDocument98 pagesSystemC-Tutorial Paderborn PDFPhan-128282No ratings yet
- Autoencoders (Slide-1) : Topics To Be Covered (Slide-2)Document10 pagesAutoencoders (Slide-1) : Topics To Be Covered (Slide-2)fake accountNo ratings yet
- EndsemDocument738 pagesEndsemVratikaNo ratings yet
- The Game Development ProcessDocument4 pagesThe Game Development ProcessrishiNo ratings yet
- Calculation: Question 2: ANN-Multi Layer Perceptron (05 Marks)Document2 pagesCalculation: Question 2: ANN-Multi Layer Perceptron (05 Marks)Hassan SheikhNo ratings yet
- CBIR Content Based Image RetrievalDocument31 pagesCBIR Content Based Image Retrievalandarivadu_561No ratings yet
- VFPX - FoxBarcodeDocument7 pagesVFPX - FoxBarcodeErre DiNo ratings yet
- Autoencoder: Tuan Nguyen - AI4EDocument35 pagesAutoencoder: Tuan Nguyen - AI4EHuy HoàngNo ratings yet
- Autoencoder: Tuan Nguyen - AI4EDocument35 pagesAutoencoder: Tuan Nguyen - AI4EHuy HoàngNo ratings yet
- CA I - Chapter 3 RISC V ProcessorDocument107 pagesCA I - Chapter 3 RISC V ProcessorViết BìnhNo ratings yet
- CEN456 NotesDocument70 pagesCEN456 NotesUthman AhmadNo ratings yet
- (Time: 3 HRS) (Max. Marks: 40)Document3 pages(Time: 3 HRS) (Max. Marks: 40)mulacNo ratings yet
- Hidden Line Removal: Unveiling the Invisible: Secrets of Computer VisionFrom EverandHidden Line Removal: Unveiling the Invisible: Secrets of Computer VisionNo ratings yet
- Hidden Surface Determination: Unveiling the Secrets of Computer VisionFrom EverandHidden Surface Determination: Unveiling the Secrets of Computer VisionNo ratings yet
- Manual Usuario Hiki User-Manual-5392612Document174 pagesManual Usuario Hiki User-Manual-5392612Rafael MunueraNo ratings yet
- Fundamental of Image ProcessingDocument23 pagesFundamental of Image ProcessingSyeda Umme Ayman ShoityNo ratings yet
- Master Thesis In-Depth InterviewsDocument5 pagesMaster Thesis In-Depth Interviewsrqopqlvcf100% (1)
- Aileen Flores Lesson Plan 2021Document8 pagesAileen Flores Lesson Plan 2021Sissay SemblanteNo ratings yet
- Kuliah 02 - Pengolahan Citra Digital Sampling Quantization 2Document18 pagesKuliah 02 - Pengolahan Citra Digital Sampling Quantization 2Zulkifli Nagh BalitanNo ratings yet
- Journal NeuroDocument15 pagesJournal Neurorwong1231No ratings yet
- Ebook PDF Consumer Behaviour Asia Pacific Edition by Wayne D Hoyer PDFDocument41 pagesEbook PDF Consumer Behaviour Asia Pacific Edition by Wayne D Hoyer PDFmarvin.tappen826100% (35)
- Information TechnologyDocument7 pagesInformation TechnologyDEVANAND ANo ratings yet
- Kotak Mahindra Bank: Presented by Navya.CDocument29 pagesKotak Mahindra Bank: Presented by Navya.CmaheshfbNo ratings yet
- Chapter OneDocument36 pagesChapter OneJeremiah Alhassan100% (1)
- SK 2015 Q PDFDocument4 pagesSK 2015 Q PDFAtlas ErnhardtNo ratings yet
- 01-PPS SMOI User Manual BodyDocument93 pages01-PPS SMOI User Manual BodyGuelahourou Joel SossieNo ratings yet
- Review of Process Parameters For Biodiesel Production From Different FeedstocksDocument9 pagesReview of Process Parameters For Biodiesel Production From Different FeedstocksHow Heoy GeokNo ratings yet
- Word 2016, Using Mail MergeDocument6 pagesWord 2016, Using Mail MergePelah Wowen DanielNo ratings yet
- Rationale of Employee Turnover: An Analysis of Banking Sector in NepalDocument8 pagesRationale of Employee Turnover: An Analysis of Banking Sector in Nepaltempmail5598No ratings yet
- Experiment No.1. (Monograph)Document3 pagesExperiment No.1. (Monograph)ayeza.sarwar2021No ratings yet
- The Marine WorkoutDocument7 pagesThe Marine WorkoutAndres Eco AldeanoNo ratings yet
- Top Tips For Marriage Habits For A Happy Marriage 2019Document2 pagesTop Tips For Marriage Habits For A Happy Marriage 2019Marcel Henri Pascal Patrice Moudiki KingueNo ratings yet
- Stroke - Wikipedia, The Free EncyclopediaDocument31 pagesStroke - Wikipedia, The Free EncyclopediaRhonskiiNo ratings yet
- En 1 6 009 M 146000Document22 pagesEn 1 6 009 M 146000David AriasNo ratings yet
- PI and PID Controller Tuning Rules - An OverviewDocument7 pagesPI and PID Controller Tuning Rules - An OverviewRobert VillavicencioNo ratings yet