You might also like
- Improved Crash Detection Algorithm For Vehicle Crash DetectionDocument7 pagesImproved Crash Detection Algorithm For Vehicle Crash Detection文升No ratings yet
- Autonomous Driving System Based On Deep Q Learnig: Takafumi Okuyama, Tad Gonsalves Jaychand UpadhayDocument5 pagesAutonomous Driving System Based On Deep Q Learnig: Takafumi Okuyama, Tad Gonsalves Jaychand Upadhayerick quispe supoNo ratings yet
- Development of Autonomous Car-Part II: A Case Study On The Implementation of An Autonomous Driving System Based On Distributed ArchitectureDocument14 pagesDevelopment of Autonomous Car-Part II: A Case Study On The Implementation of An Autonomous Driving System Based On Distributed ArchitectureAli Ali AlialiNo ratings yet
- Steam Jet Refrigeration SystemDocument3 pagesSteam Jet Refrigeration Systematulyajyoti123100% (1)
- Driverless Car: Autonomous Driving Using Deep Reinforcement Learning in Urban EnvironmentDocument6 pagesDriverless Car: Autonomous Driving Using Deep Reinforcement Learning in Urban EnvironmentRenan PortoNo ratings yet
- A Survey of Technical Trends of ADAS and Autonomous DrivingDocument4 pagesA Survey of Technical Trends of ADAS and Autonomous DrivingFang YuanNo ratings yet
- Self-Driving Car Lane-Keeping Assist Using PID and Pure Pursuit ControlDocument6 pagesSelf-Driving Car Lane-Keeping Assist Using PID and Pure Pursuit ControlTiến Hoàng KimNo ratings yet
- Imitation Learning Approach For AI Driving Olympics Trained On Real-World and Simulation Data SimultaneouslyDocument5 pagesImitation Learning Approach For AI Driving Olympics Trained On Real-World and Simulation Data SimultaneouslyandreNo ratings yet
- Self Driving Car Using Aurdin and Rasberry PiDocument6 pagesSelf Driving Car Using Aurdin and Rasberry PiSahana GuddadNo ratings yet
- Application of Deep Learning To Develop An Autonomous VehicleDocument11 pagesApplication of Deep Learning To Develop An Autonomous VehicleSalman MNo ratings yet
- Self Driving CarsDocument8 pagesSelf Driving CarsNISHMA ELIZABETHNo ratings yet
- Self Driving Car Using Raspberry Pi: Keywords:Raspberry Pi, Lane Detection, Obstacle Detection, Opencv, Deep LearningDocument8 pagesSelf Driving Car Using Raspberry Pi: Keywords:Raspberry Pi, Lane Detection, Obstacle Detection, Opencv, Deep LearningKrishna KrishNo ratings yet
- Paper 1 MlisDocument19 pagesPaper 1 MlisDhruv SoniNo ratings yet
- Accurate, Low-Latency Visual Perception For Autonomous Racing: Challenges, Mechanisms, and Practical SolutionsDocument7 pagesAccurate, Low-Latency Visual Perception For Autonomous Racing: Challenges, Mechanisms, and Practical SolutionsDanika ShrivastavaNo ratings yet
- A Survey of Autonomous Driving:: Common Practices and Emerging TechnologiesDocument28 pagesA Survey of Autonomous Driving:: Common Practices and Emerging TechnologiesVishal ManwaniNo ratings yet
- Experiment 8 AISCDocument6 pagesExperiment 8 AISCfacad22886No ratings yet
- Autonomous Driving System Using Proximal Policy Optimization in Deep Reinforcement LearningDocument10 pagesAutonomous Driving System Using Proximal Policy Optimization in Deep Reinforcement LearningIAES IJAINo ratings yet
- Iot Format WordDocument13 pagesIot Format WordNikhil SnNo ratings yet
- CATVehicle RL GroupDocument8 pagesCATVehicle RL GroupFernando LópezNo ratings yet
- Convolutional Neural Network For A Self-Driving Car in A Virtual EnvironmentDocument6 pagesConvolutional Neural Network For A Self-Driving Car in A Virtual EnvironmentChandra LohithNo ratings yet
- Self-Driving Cars Using Genetic AlgorithmDocument6 pagesSelf-Driving Cars Using Genetic AlgorithmIJRASETPublicationsNo ratings yet
- IcetranAutonomous Car Driving One Possible Implementation Using Machine Learning AlgorithmDocument7 pagesIcetranAutonomous Car Driving One Possible Implementation Using Machine Learning AlgorithmSaif HaqueNo ratings yet
- Fast-Tracking Advanced Driver Assistance Systems (ADAS) and Autonomous Vehicles Development With SimulationDocument7 pagesFast-Tracking Advanced Driver Assistance Systems (ADAS) and Autonomous Vehicles Development With SimulationSiddharth ChauhanNo ratings yet
- Proximity Based Automatic Data Annotation For Autonomous DrivingDocument10 pagesProximity Based Automatic Data Annotation For Autonomous DrivingHaripriya PalemNo ratings yet
- 1.4mDocument8 pages1.4mDũng HoàngNo ratings yet
- A Deep Convolutional Neural Network Based Small Scale Test-Bed For Autonomous CarDocument5 pagesA Deep Convolutional Neural Network Based Small Scale Test-Bed For Autonomous CarPiash AnikNo ratings yet
- Ijet V4i3p31 PDFDocument5 pagesIjet V4i3p31 PDFInternational Journal of Engineering and TechniquesNo ratings yet
- 10 1109@icsec 2018 8712778Document4 pages10 1109@icsec 2018 8712778Anurag ChauhanNo ratings yet
- Accelerating The Training of Deep Reinforcement Learning in Autonomous DrivingDocument8 pagesAccelerating The Training of Deep Reinforcement Learning in Autonomous DrivingIAES IJAINo ratings yet
- CommaldsDocument8 pagesCommaldsFred LamertNo ratings yet
- 2013 Iv SRXDocument8 pages2013 Iv SRXSai Krishna KARANAMNo ratings yet
- Autonomous Vehicle: The Architecture Aspect of Self Driving CarDocument6 pagesAutonomous Vehicle: The Architecture Aspect of Self Driving CarmokhtarNo ratings yet
- Sensors: System, Design and Experimental Validation of Autonomous Vehicle in An Unconstrained EnvironmentDocument35 pagesSensors: System, Design and Experimental Validation of Autonomous Vehicle in An Unconstrained EnvironmentJM RamirezNo ratings yet
- Visual Detection and Deep Reinforcement Learning-Based Car Following and Energy Management For Hybrid Electric VehiclesDocument15 pagesVisual Detection and Deep Reinforcement Learning-Based Car Following and Energy Management For Hybrid Electric VehiclesWEIWEI YANGNo ratings yet
- Building CNN Model - Formatted PaperDocument7 pagesBuilding CNN Model - Formatted Paperoussama zemziNo ratings yet
- Drones 07 00682Document18 pagesDrones 07 00682ControlSI PeruNo ratings yet
- This Study Resource Was Shared Via: Title Submission: Sept 25 (Next Week) Presentations: Oct 2 (Next AI Class)Document5 pagesThis Study Resource Was Shared Via: Title Submission: Sept 25 (Next Week) Presentations: Oct 2 (Next AI Class)Saad khalilNo ratings yet
- Integration: Esraa Khatab, Ahmed Onsy, Martin Varley, Ahmed AbouelfaragDocument13 pagesIntegration: Esraa Khatab, Ahmed Onsy, Martin Varley, Ahmed Abouelfaragcaner beldekNo ratings yet
- A Comparative Study On Semantic Segmentation Algorithms For Autonomous Driving VehiclesDocument10 pagesA Comparative Study On Semantic Segmentation Algorithms For Autonomous Driving VehiclesIJRASETPublicationsNo ratings yet
- Tits 2020 2980855Document15 pagesTits 2020 2980855rahul rNo ratings yet
- J Matpr 2020 04 736Document8 pagesJ Matpr 2020 04 736atul bhagatNo ratings yet
- Easy DriveDocument14 pagesEasy Drivesreepranad DevarakondaNo ratings yet
- VTD Ebook WDocument40 pagesVTD Ebook WChus SanchezNo ratings yet
- Ai Based Autonomous CarDocument9 pagesAi Based Autonomous CarDionisie LefterNo ratings yet
- Unmanned Ground Vehicle Final Completed 1Document25 pagesUnmanned Ground Vehicle Final Completed 1Guruprasad BhagwatNo ratings yet
- Highly Automated Vehicles and Self-Driving Cars: Industry TutorialDocument7 pagesHighly Automated Vehicles and Self-Driving Cars: Industry TutorialJulius Fusic SNo ratings yet
- Design & Implementation of Real Time Autonomous Car by Using Image Processing & IoTDocument7 pagesDesign & Implementation of Real Time Autonomous Car by Using Image Processing & IoTTv BraviaNo ratings yet
- Vision-Based Front and Rear Surround Understanding Using Embedded ProcessorsDocument11 pagesVision-Based Front and Rear Surround Understanding Using Embedded Processorsnirikshith pNo ratings yet
- Deep Reinforcement Learning For Autonomous Driving A SurveyDocument18 pagesDeep Reinforcement Learning For Autonomous Driving A Survey祁朋No ratings yet
- Miniature Model of Autonomous Vehicle Using Arduino UNO and Open CVDocument14 pagesMiniature Model of Autonomous Vehicle Using Arduino UNO and Open CVIJRASETPublicationsNo ratings yet
- Machines 11 01068 v2Document14 pagesMachines 11 01068 v2dekerNo ratings yet
- Greenscore Vehicle Identification Using CNN (Convolutional Neural Network)Document11 pagesGreenscore Vehicle Identification Using CNN (Convolutional Neural Network)IJRASETPublicationsNo ratings yet
- Design and Fabrication of Auto Cart CarrierDocument4 pagesDesign and Fabrication of Auto Cart CarrierRAJESH MNo ratings yet
- Hydramini: An Fpga-Based Affordable Research and Education Platform For Autonomous DrivingDocument8 pagesHydramini: An Fpga-Based Affordable Research and Education Platform For Autonomous DrivingSMITH CAMILO QUEVEDONo ratings yet
- Research Paper On AI in DrivingDocument9 pagesResearch Paper On AI in DrivingIJRASETPublicationsNo ratings yet
- Helmet Detection On Two-Wheeler Riders Using Machine LearningDocument4 pagesHelmet Detection On Two-Wheeler Riders Using Machine LearningMelroy PereiraNo ratings yet
- On Board Complete Traffic Signalling System Using Image ProcessingDocument7 pagesOn Board Complete Traffic Signalling System Using Image ProcessingIJRASETPublicationsNo ratings yet
- Mobile Robotics, Moving Intelligence 109: Creative ControllerDocument6 pagesMobile Robotics, Moving Intelligence 109: Creative ControllerAdobe AdobeNo ratings yet
- Deep Convolutional Neural Networks Architecture For An Efficient Emergency Vehicle Classification in Real-Time Traffic MonitoringDocument11 pagesDeep Convolutional Neural Networks Architecture For An Efficient Emergency Vehicle Classification in Real-Time Traffic MonitoringIAES IJAINo ratings yet
- OpenGL Deep Dive: Expert Techniques and Performance Optimization: OpenGLFrom EverandOpenGL Deep Dive: Expert Techniques and Performance Optimization: OpenGLNo ratings yet
- Advances in Embedded Computer VisionFrom EverandAdvances in Embedded Computer VisionBranislav KisačaninNo ratings yet
- Diode Clippers and ClampersDocument16 pagesDiode Clippers and ClampersArohon DasNo ratings yet
- Shravan Jha Resume NewDocument1 pageShravan Jha Resume NewArohon DasNo ratings yet
- Problem StatementsDocument8 pagesProblem StatementsArohon DasNo ratings yet
- Train Ticket ChennaiDocument2 pagesTrain Ticket ChennaiArohon DasNo ratings yet
- Resources For JuniorsDocument3 pagesResources For JuniorsArohon DasNo ratings yet
- Learn C++ Programming - Beginner To Advance - Deep Dive in C++ Udemy Coupon & ReviewDocument4 pagesLearn C++ Programming - Beginner To Advance - Deep Dive in C++ Udemy Coupon & ReviewArohon DasNo ratings yet
- EnterDocument15 pagesEnterArohon DasNo ratings yet
- Weekly Basic TasksDocument7 pagesWeekly Basic TasksArohon DasNo ratings yet
- CT1 Question PaperDocument2 pagesCT1 Question PaperArohon DasNo ratings yet
- National Institute of Technology, Tiruchirappalli 2Document9 pagesNational Institute of Technology, Tiruchirappalli 2Arohon DasNo ratings yet
- Chapter 13 Recurrent Neural NetworksDocument46 pagesChapter 13 Recurrent Neural NetworksArohon DasNo ratings yet
- Series Voltage Negative Feedback AmplifierDocument4 pagesSeries Voltage Negative Feedback AmplifierArohon DasNo ratings yet
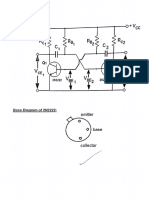
- Circuit Diagram:: Base Diagram of 2N2222Document6 pagesCircuit Diagram:: Base Diagram of 2N2222Arohon DasNo ratings yet
- Scheduling BODS Jobs Sequentially and ConditionDocument10 pagesScheduling BODS Jobs Sequentially and ConditionwicvalNo ratings yet
- Lecture 8 - Spectrum ManagementDocument39 pagesLecture 8 - Spectrum ManagementMohammad Yaseen KhanNo ratings yet
- Mission Magnum I Pump Spare PartsDocument2 pagesMission Magnum I Pump Spare PartsEleazar GallegosNo ratings yet
- ANT-AQU4518R9-1264 Datasheet PDFDocument2 pagesANT-AQU4518R9-1264 Datasheet PDFafton mohammadNo ratings yet
- By The Articles of Incorporation or By-Laws A Members May Vote by Proxy inDocument3 pagesBy The Articles of Incorporation or By-Laws A Members May Vote by Proxy incitizenNo ratings yet
- Machinery Safety OSHADocument14 pagesMachinery Safety OSHAYarenNo ratings yet
- Admiral Markets Uk LTD Client Complaints Handling ProcedureDocument3 pagesAdmiral Markets Uk LTD Client Complaints Handling ProcedureTensonNo ratings yet
- Arabic-English Legal GlossaryDocument13 pagesArabic-English Legal GlossaryAnas EbrahimNo ratings yet
- L7 Designing HCI Studies COMP1649Document31 pagesL7 Designing HCI Studies COMP1649Dhruv PatelNo ratings yet
- မြန်မာ - datastructures&algorithmsDocument114 pagesမြန်မာ - datastructures&algorithmsAlex SnowNo ratings yet
- Sample Topic Proposal For A Research PaperDocument8 pagesSample Topic Proposal For A Research Paperzmvhosbnd100% (1)
- Bdm100 Ecu FlasherDocument2 pagesBdm100 Ecu FlasherJaved IqbalNo ratings yet
- Motion in A Straight Line PDFDocument26 pagesMotion in A Straight Line PDFsujit21in4376100% (1)
- Elecrama ExhDocument44 pagesElecrama ExhMayank Dixit100% (1)
- GEPEA EUROPE - About USDocument3 pagesGEPEA EUROPE - About USRejaul AbedinNo ratings yet
- Reverse LogisticsDocument21 pagesReverse LogisticsParth V. PurohitNo ratings yet
- Membrane SpecsDocument10 pagesMembrane Specsadalcayde2514No ratings yet
- DTS-X Vs Dolby AtmosDocument3 pagesDTS-X Vs Dolby Atmoskar_21182No ratings yet
- PF2E Conversion Guide From PF1EDocument6 pagesPF2E Conversion Guide From PF1ElpokmNo ratings yet
- McDonald's Generic Strategy & Intensive Growth Strategies - Panmore InstituteDocument3 pagesMcDonald's Generic Strategy & Intensive Growth Strategies - Panmore InstituteLayyinahNo ratings yet
- AKG CS3 Discussion SystemDocument6 pagesAKG CS3 Discussion SystemSound Technology LtdNo ratings yet
- 6 ஆண்டு பிரியாவிடை உரைDocument12 pages6 ஆண்டு பிரியாவிடை உரைKUHAN A/L TAMILCHELVAN MoeNo ratings yet
- Shun Tillman Crime Prevention Specialist 3rd Precinct CCP/SAFE 3000 Minnehaha Ave South Minneapolis, MN 55406 Shun - Tillman@ci - Minneapolis.mn - UsDocument1 pageShun Tillman Crime Prevention Specialist 3rd Precinct CCP/SAFE 3000 Minnehaha Ave South Minneapolis, MN 55406 Shun - Tillman@ci - Minneapolis.mn - UssewardpNo ratings yet
- Υπόθεση (engl)Document10 pagesΥπόθεση (engl)coolmandia13No ratings yet
- IEEE Hybrid GroundingDocument27 pagesIEEE Hybrid GroundingAlfredo Castillo BarettNo ratings yet
- Professionalization of Pre-Service Teachers Through University-School PartnershipsDocument13 pagesProfessionalization of Pre-Service Teachers Through University-School Partnershipsurban7653No ratings yet
- Maulana Azad National Institute of Technology, BhopalDocument2 pagesMaulana Azad National Institute of Technology, BhopalNiteshNarukaNo ratings yet
- Av RemoveDocument616 pagesAv RemoveSlobodan VujnicNo ratings yet
- TracebackDocument2 pagesTracebackTim HinderkottNo ratings yet