You might also like
- تقارير مختبر محركات احتراق داخليDocument19 pagesتقارير مختبر محركات احتراق داخليwesamNo ratings yet
- EJ2SEMANA3Document14 pagesEJ2SEMANA3fuck off we need limitsNo ratings yet
- SVM K NN MLP With Sklearn Jupyter NoteBoDocument22 pagesSVM K NN MLP With Sklearn Jupyter NoteBoAhm TharwatNo ratings yet
- Question 8Document1 pageQuestion 8luong.hng43No ratings yet
- "Feature Names:" "Target Names:" "/nfirst 10 Rows of X:/N": From ImportDocument6 pages"Feature Names:" "Target Names:" "/nfirst 10 Rows of X:/N": From Import19C089 SHAAMBHAVI SNo ratings yet
- A-Simple-Neural-Network-From-Scratch - Jupyter NotebookDocument9 pagesA-Simple-Neural-Network-From-Scratch - Jupyter NotebookThambi SmithNo ratings yet
- Lecture 21Document138 pagesLecture 21Tev WallaceNo ratings yet
- Lab05 Object SegmentationDocument27 pagesLab05 Object SegmentationDũng HiNo ratings yet
- Training and EvaluationDocument20 pagesTraining and Evaluationnegisid126No ratings yet
- Ann 1Document20 pagesAnn 11314 Vishakha JagtapNo ratings yet
- Lab04 Object SegmentationDocument29 pagesLab04 Object SegmentationDũng HiNo ratings yet
- Keras - Functional APIDocument18 pagesKeras - Functional APInegisid126No ratings yet
- 20MIS1025 - DecisionTree - Ipynb - ColaboratoryDocument4 pages20MIS1025 - DecisionTree - Ipynb - ColaboratorySandip DasNo ratings yet
- Deep-Learning-Keras-Tensorflow - 1.1.1 Perceptron and Adaline - Ipynb at Master Leriomaggio - Deep-Learning-Keras-TensorflowDocument11 pagesDeep-Learning-Keras-Tensorflow - 1.1.1 Perceptron and Adaline - Ipynb at Master Leriomaggio - Deep-Learning-Keras-Tensorflowme andan buscandoNo ratings yet
- Content: From Import Import As Import Import Import AsDocument8 pagesContent: From Import Import As Import Import Import Asبشار الحسينNo ratings yet
- ArbolesRF UNIDocument3 pagesArbolesRF UNIALISON ELIZABETH HUAPAYA CAYCHONo ratings yet
- Lab02-Object SegmentationDocument31 pagesLab02-Object SegmentationDũng HiNo ratings yet
- Assignment 12Document4 pagesAssignment 12dashNo ratings yet
- Transfer Learning For Image Classification in PytorchDocument13 pagesTransfer Learning For Image Classification in PytorchMinusha TehaniNo ratings yet
- Alzheimers Classification 2Document17 pagesAlzheimers Classification 2chimatayaswanth555No ratings yet
- Ai/Ml Lab-4: Name: Pratik Jadhav PRN: 20190802050Document5 pagesAi/Ml Lab-4: Name: Pratik Jadhav PRN: 20190802050testNo ratings yet
- Effects of Batches - Jupyter NotebookDocument73 pagesEffects of Batches - Jupyter Notebookjerry.sharma0312No ratings yet
- Aries ProjectDocument6 pagesAries ProjectDivyansh BhadauriaNo ratings yet
- Lab01 Object SegmentationDocument24 pagesLab01 Object SegmentationDũng HiNo ratings yet
- PythonfileDocument36 pagesPythonfilecollection58209No ratings yet
- Lab - 5 (CB - En.u4ece22115)Document5 pagesLab - 5 (CB - En.u4ece22115)Daejuswaram GopinathNo ratings yet
- 3 SVM - Jupyter NotebookDocument4 pages3 SVM - Jupyter Notebookvenkatesh mNo ratings yet
- Bigan - Final - Jupyter NotebookDocument19 pagesBigan - Final - Jupyter Notebookjerry.sharma0312No ratings yet
- DL 8Document6 pagesDL 8Siddesh PingaleNo ratings yet
- Plotting Decision Regions - MlxtendDocument5 pagesPlotting Decision Regions - Mlxtendakhi016733No ratings yet
- 22MCA1008 - Varun ML LAB ASSIGNMENTSDocument41 pages22MCA1008 - Varun ML LAB ASSIGNMENTSS Varun (RA1931241020133)100% (1)
- Initializing Input and Batch SizesDocument15 pagesInitializing Input and Batch SizesmkkadambiNo ratings yet
- Machine Learning LAB: Practical-1Document24 pagesMachine Learning LAB: Practical-1Tsering Jhakree100% (1)
- 5 Random Forest - Jupyter NotebookDocument2 pages5 Random Forest - Jupyter Notebookvenkatesh mNo ratings yet
- Machine Learning With SQLDocument12 pagesMachine Learning With SQLprince krish100% (1)
- Untitled66 - Jupyter NotebookDocument2 pagesUntitled66 - Jupyter NotebookGopala krishna SeelamneniNo ratings yet
- Lanaro G. - Python High Performance, Second Edition - 2017Document264 pagesLanaro G. - Python High Performance, Second Edition - 2017lasa greenNo ratings yet
- Lecture 22Document64 pagesLecture 22Tev WallaceNo ratings yet
- PS Project - Jupyter NotebookDocument6 pagesPS Project - Jupyter NotebookM. Mobeen KhattakNo ratings yet
- Tarea - Predecir Dígitos Manuscritos Con SVM RadialDocument5 pagesTarea - Predecir Dígitos Manuscritos Con SVM RadialNuñez Velez MelisaNo ratings yet
- JAVIER KMeans Clustering Jupyter NotebookDocument7 pagesJAVIER KMeans Clustering Jupyter NotebookAlleah LayloNo ratings yet
- PL IiDocument43 pagesPL IiRohan 7No ratings yet
- MachineDocument45 pagesMachineGagan Sharma100% (1)
- Ml-A2 CodeDocument5 pagesMl-A2 CodeBECOC362Atharva UtekarNo ratings yet
- WLeaf Disease Classification - ResNet50.ipynb - ColaboratoryDocument12 pagesWLeaf Disease Classification - ResNet50.ipynb - ColaboratoryTefeNo ratings yet
- CodesDocument6 pagesCodesVamshi KrishnaNo ratings yet
- 1 An Introduction To Machine Learning With Scikit LearnDocument2 pages1 An Introduction To Machine Learning With Scikit Learnkehinde.ogunleye007No ratings yet
- ML Lab ProgramsDocument23 pagesML Lab ProgramsRoopa 18-19-36No ratings yet
- DMML2023 Lecture05 19jan2023Document17 pagesDMML2023 Lecture05 19jan2023arindamsinharayNo ratings yet
- ML Lab6Document4 pagesML Lab6Pankaj MandloiNo ratings yet
- ML Shristi FileDocument49 pagesML Shristi FileRAVI PARKASHNo ratings yet
- Principal Component Analysis Notes : InfoDocument22 pagesPrincipal Component Analysis Notes : InfoVALMICK GUHANo ratings yet
- Planar Data Classification With One Hidden Layer v5Document19 pagesPlanar Data Classification With One Hidden Layer v5sn3fruNo ratings yet
- 16BCB0126 VL2018195002535 Pe003Document40 pages16BCB0126 VL2018195002535 Pe003MohitNo ratings yet
- CorrectionDocument3 pagesCorrectionbougmazisoufyaneNo ratings yet
- C1 W2 Lab05 Sklearn GD SolnDocument3 pagesC1 W2 Lab05 Sklearn GD SolnSrinidhi PNo ratings yet
- 4 Decision Tree - Jupyter NotebookDocument2 pages4 Decision Tree - Jupyter Notebookvenkatesh mNo ratings yet
- ML - Practical FileDocument15 pagesML - Practical FileJatin MathurNo ratings yet
- 12-3-Praktik Deep Learning Dengan PythonDocument8 pages12-3-Praktik Deep Learning Dengan PythonSeptica TiaraNo ratings yet
- Daftar Lampiran Coding Python RecognizeDocument7 pagesDaftar Lampiran Coding Python RecognizeResha Noviane PutriNo ratings yet
- Seminar3 enDocument7 pagesSeminar3 enandreiNo ratings yet
- EM0505 3.0v1 Introduction To Sophos EmailDocument19 pagesEM0505 3.0v1 Introduction To Sophos EmailemendozaNo ratings yet
- Cerebrum - Product Sheet + Protocol List V2.2Document10 pagesCerebrum - Product Sheet + Protocol List V2.2Tony PerezNo ratings yet
- Jun Jul 2021Document32 pagesJun Jul 2021Lai Kok UeiNo ratings yet
- Entrepreneurial Skills-II: in This Chapter..Document34 pagesEntrepreneurial Skills-II: in This Chapter..TECH-A -TRONICSNo ratings yet
- Hero Pleasure Scooter Part Catalogue Mar 2010 EditionDocument78 pagesHero Pleasure Scooter Part Catalogue Mar 2010 EditionAmanNo ratings yet
- Cie-III Verilog HDL QPDocument2 pagesCie-III Verilog HDL QPvijayarani.katkamNo ratings yet
- First Order Logic: Artificial Intelligence COSC-3112 Ms. Humaira AnwerDocument24 pagesFirst Order Logic: Artificial Intelligence COSC-3112 Ms. Humaira AnwerKhizrah RafiqueNo ratings yet
- Medium-Low Speed AD LiDAR Perception Solution Brochure EN 20200312Document2 pagesMedium-Low Speed AD LiDAR Perception Solution Brochure EN 20200312nazi1945No ratings yet
- Construction Planning and SchedulingDocument70 pagesConstruction Planning and SchedulingDessalegn AyenewNo ratings yet
- Developing A Social Media Strategy: © RB Consulting 2010Document12 pagesDeveloping A Social Media Strategy: © RB Consulting 2010edetpickin1No ratings yet
- FINANOTECH Registration Form PMP Certification Training Cohort January 2023Document21 pagesFINANOTECH Registration Form PMP Certification Training Cohort January 2023Abhi CaullychurnNo ratings yet
- Principles of Electric Circuits - FloydDocument40 pagesPrinciples of Electric Circuits - FloydhdjskhdkjsNo ratings yet
- Love Marriage Specialist PanditDocument3 pagesLove Marriage Specialist PanditLove marriage specialist panditNo ratings yet
- Interview Management - ORCDocument4 pagesInterview Management - ORCAbdulrhmanHaddadyNo ratings yet
- Lubuklinggau Price 2017Document59 pagesLubuklinggau Price 2017akhmad hidayatNo ratings yet
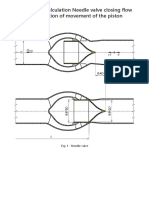
- Hydrodynamic Calculation Needle Valve Closing Flow Against The Direction of Movement of The PistonDocument23 pagesHydrodynamic Calculation Needle Valve Closing Flow Against The Direction of Movement of The Pistonmet-calcNo ratings yet
- Multi DIALOG MDM - MDT. MDM 10-20kVA Single - Single-Phase and Three - Single-Phase MDT 10-80kVA Three - Three-Phase NETWORK RANGEDocument8 pagesMulti DIALOG MDM - MDT. MDM 10-20kVA Single - Single-Phase and Three - Single-Phase MDT 10-80kVA Three - Three-Phase NETWORK RANGEMARCOS LARA ROMERO DE AVILANo ratings yet
- Yellampalli S. Wireless Sensor Networks - Design, Deployment..2021Document314 pagesYellampalli S. Wireless Sensor Networks - Design, Deployment..2021Myster SceneNo ratings yet
- Comprehensive Comparison of 99 Efficient Totem-Pole PFC With Fixed PWM or Variable TCM Switching FrequencyDocument8 pagesComprehensive Comparison of 99 Efficient Totem-Pole PFC With Fixed PWM or Variable TCM Switching FrequencyMuhammad Arsalan FarooqNo ratings yet
- Reflection PaperDocument2 pagesReflection PaperKatrina DeveraNo ratings yet
- Tech M Service LetterDocument1 pageTech M Service LetterRahul upadhyayNo ratings yet
- Pvi 7200 Wind Interface 0Document20 pagesPvi 7200 Wind Interface 0KarbonKaleNo ratings yet
- 247248-The Histiry and Culture of The Indian People, The Vedic Age Vol I - DjvuDocument620 pages247248-The Histiry and Culture of The Indian People, The Vedic Age Vol I - DjvuDeja ImagenationNo ratings yet
- U19EC416 DSP Lab SyllabusDocument2 pagesU19EC416 DSP Lab SyllabusRamesh MallaiNo ratings yet
- TÜV Rheinland Academy: 2021 Professional Training Schedule - Virtual ClassroomDocument3 pagesTÜV Rheinland Academy: 2021 Professional Training Schedule - Virtual ClassroomAaron ValdezNo ratings yet
- All Worksheets MYSQLDocument33 pagesAll Worksheets MYSQLSample1No ratings yet
- Face Recognition - HLD - V1Document4 pagesFace Recognition - HLD - V1SuryaNo ratings yet
- Maintenance Instructions For Voltage Detecting SystemDocument1 pageMaintenance Instructions For Voltage Detecting Systemيوسف خضر النسورNo ratings yet