You might also like
- The Not So Short Introduction To L Tex 2Ε: Orl Tex 2Ε In MinutesDocument104 pagesThe Not So Short Introduction To L Tex 2Ε: Orl Tex 2Ε In Minutesbartos021No ratings yet
- Latex IntroductionDocument171 pagesLatex IntroductionSandy TerpopeNo ratings yet
- The Not So Short Introduction To LaTeXDocument153 pagesThe Not So Short Introduction To LaTeXoetiker100% (3)
- (TeX Ebook) - Latex ManualDocument143 pages(TeX Ebook) - Latex ManualMauro ReisNo ratings yet
- Latex ManualDocument143 pagesLatex ManualGabriela MogosNo ratings yet
- The Not So Short Introduction To L Tex 2Ε: Orl Tex 2Ε In MinutesDocument153 pagesThe Not So Short Introduction To L Tex 2Ε: Orl Tex 2Ε In MinutesbhupsNo ratings yet
- The Not So Short Introduction To LaTeX2eDocument104 pagesThe Not So Short Introduction To LaTeX2eMirza HamedNo ratings yet
- The Not So Short Introduction To LatexDocument101 pagesThe Not So Short Introduction To Latexapi-3770733100% (1)
- Latex The Not So Short IntroductionDocument101 pagesLatex The Not So Short IntroductionArmando Treibich KohnNo ratings yet
- LaTeX Short GuideDocument101 pagesLaTeX Short GuideRómulo Del CarpioNo ratings yet
- Lshort A5Document146 pagesLshort A5Mallgi34100% (1)
- LshortDocument153 pagesLshortjamesNo ratings yet
- The Not So Short Introduction To L Tex 2Ε: Orl Tex 2Ε In MinutesDocument145 pagesThe Not So Short Introduction To L Tex 2Ε: Orl Tex 2Ε In Minutesapi-19731445No ratings yet
- Lshort A5Document163 pagesLshort A5mibblNo ratings yet
- A Winter Training Report On Automation Using PythonDocument29 pagesA Winter Training Report On Automation Using Pythonsandy jonsonNo ratings yet
- LyX EssentialsDocument24 pagesLyX EssentialsVinny Tagor100% (1)
- Tutorial Latex by SelenityDocument147 pagesTutorial Latex by SelenitycajascNo ratings yet
- LshortDocument171 pagesLshortCXBBANo ratings yet
- The Not So Short Introduction To Latex - T. Oetiker, ...Document165 pagesThe Not So Short Introduction To Latex - T. Oetiker, ...elvir.avdicevicNo ratings yet
- The Not So Short Introduction To L Tex 2Ε: Orl Tex 2Ε In MinutesDocument171 pagesThe Not So Short Introduction To L Tex 2Ε: Orl Tex 2Ε In MinutesfakihajNo ratings yet
- HowtolatexDocument8 pagesHowtolatexXibiu KaraiNo ratings yet
- LshortDocument153 pagesLshortEuler Horta MarinhoNo ratings yet
- The Not So Short Introduction To L Tex 2Ε: Orl Tex 2Ε In MinutesDocument171 pagesThe Not So Short Introduction To L Tex 2Ε: Orl Tex 2Ε In Minuteslexes26No ratings yet
- Template For SomethingDocument27 pagesTemplate For SomethinglachychartsNo ratings yet
- Latent Semantic AnalysisDocument15 pagesLatent Semantic Analysisjohn kayNo ratings yet
- Applied DWS2 ProgrammingDocument136 pagesApplied DWS2 ProgrammingEmrah ÖzcanNo ratings yet
- Howto UnicodeDocument9 pagesHowto UnicodedomielNo ratings yet
- A Super Brief, Yet Super Awesome, LaTeX Cheat SheetDocument10 pagesA Super Brief, Yet Super Awesome, LaTeX Cheat SheetsjenicakNo ratings yet
- Lshort Versi 11-10-2022Document298 pagesLshort Versi 11-10-2022paul taniwanNo ratings yet
- LshortDocument171 pagesLshortUxi MaiaNo ratings yet
- A Winter Training Report On Automation Using PythonDocument30 pagesA Winter Training Report On Automation Using Pythonsandy jonsonNo ratings yet
- TEXworks ManualDocument64 pagesTEXworks ManualTanuj ParasteNo ratings yet
- Writing A Paper in LatexDocument34 pagesWriting A Paper in LatexGurpreet SinghNo ratings yet
- Beamer ScriptDocument14 pagesBeamer ScripticyqqboyNo ratings yet
- The Not So Short Introduction To LATEXDocument171 pagesThe Not So Short Introduction To LATEXMa BuNo ratings yet
- The Not So Short Introduction To LaTeXDocument171 pagesThe Not So Short Introduction To LaTeXJoanne WuNo ratings yet
- Microsoft Outlook Outlook Express The Bat! Thunderbird Eudora Opera Web Interface OtherDocument12 pagesMicrosoft Outlook Outlook Express The Bat! Thunderbird Eudora Opera Web Interface Otheranon_660430481No ratings yet
- Lab 1Document7 pagesLab 1Nimra GhafoorNo ratings yet
- A Short Manual For Texworks: Lowering The Entry Barrier To The Tex WorldDocument74 pagesA Short Manual For Texworks: Lowering The Entry Barrier To The Tex Worldlexleo1000No ratings yet
- Steps in LaTeXDocument151 pagesSteps in LaTeXsreedeviishNo ratings yet
- Openoffice: December 8, 2008Document13 pagesOpenoffice: December 8, 2008sooraj kNo ratings yet
- Intelligent Dictionary Based Encryption and Compression AlgorithmDocument35 pagesIntelligent Dictionary Based Encryption and Compression Algorithmarjun c chandrathil100% (3)
- To Cascading Style Sheets: A Workbook & GuideDocument58 pagesTo Cascading Style Sheets: A Workbook & GuideAlejandro EstudianteNo ratings yet
- Python l1 Assignments Topgear 1Document3 pagesPython l1 Assignments Topgear 1Akansha AgrawalNo ratings yet
- Reading Material For Week 2Document15 pagesReading Material For Week 2karan godaraNo ratings yet
- TeXworks ManualDocument43 pagesTeXworks Manualvagver13No ratings yet
- L TEX WorkshopDocument12 pagesL TEX WorkshopAAYUSH SENAPATINo ratings yet
- Practical guide for coding: Coding Manual for Industry and product standard classification, generic and for warehouse guideline with Classification Plans and sample Tables for coding articles, products, price listsFrom EverandPractical guide for coding: Coding Manual for Industry and product standard classification, generic and for warehouse guideline with Classification Plans and sample Tables for coding articles, products, price listsNo ratings yet
- Excel 101: A Beginner's Guide for Mastering the Quintessence of Excel 2010-2019 in no time!From EverandExcel 101: A Beginner's Guide for Mastering the Quintessence of Excel 2010-2019 in no time!No ratings yet
- DSA Chapter 4Document79 pagesDSA Chapter 4beshahashenafe20No ratings yet
- DSA Chapter 6Document40 pagesDSA Chapter 6beshahashenafe20No ratings yet
- DSA Chapter 7Document91 pagesDSA Chapter 7beshahashenafe20No ratings yet
- DSA Lab Session 2Document2 pagesDSA Lab Session 2beshahashenafe20No ratings yet
- DSA Chapter 1Document54 pagesDSA Chapter 1beshahashenafe20No ratings yet
- Stat AssignmentDocument4 pagesStat Assignmentbeshahashenafe20No ratings yet
- Chapter 4 Distributed Database SystemsDocument69 pagesChapter 4 Distributed Database Systemsbeshahashenafe20No ratings yet
- Chapter 8Document42 pagesChapter 8beshahashenafe20No ratings yet
- Course OutlineDocument1 pageCourse Outlinebeshahashenafe20No ratings yet
- DSA Lab Session 9Document2 pagesDSA Lab Session 9beshahashenafe20No ratings yet
- Chapter 3 Database Integrity, Security and RecoveryDocument39 pagesChapter 3 Database Integrity, Security and Recoverybeshahashenafe20No ratings yet
- OOP Chapter 0Document34 pagesOOP Chapter 0beshahashenafe20No ratings yet
- Database System Development Life CycleDocument6 pagesDatabase System Development Life Cyclebeshahashenafe20100% (1)
- Chapter 1 Introduction To Object Oriented ProgrammingDocument43 pagesChapter 1 Introduction To Object Oriented Programmingbeshahashenafe20No ratings yet
- 1 IRIntroDocument95 pages1 IRIntrobeshahashenafe20No ratings yet
- Chapter 9Document14 pagesChapter 9beshahashenafe20No ratings yet
- DSA-Group Assignment - 2024 - UpdatedDocument5 pagesDSA-Group Assignment - 2024 - Updatedbeshahashenafe20No ratings yet
- Query Processing and OptimizationDocument22 pagesQuery Processing and Optimizationbeshahashenafe20No ratings yet
- Eco MidDocument14 pagesEco Midbeshahashenafe20No ratings yet
- Chapter - 5 - Introduction To Object Oriented ProgrammingDocument38 pagesChapter - 5 - Introduction To Object Oriented Programmingbeshahashenafe20No ratings yet
- Chap1 and 2Document62 pagesChap1 and 2beshahashenafe20No ratings yet
- ADB Lab Session Guiding NoteDocument18 pagesADB Lab Session Guiding Notebeshahashenafe20No ratings yet
- AccountingDocument13 pagesAccountingbeshahashenafe20No ratings yet
- Scott Entereprise Income Statement at December 31 2020: Cost of Goods SoldDocument2 pagesScott Entereprise Income Statement at December 31 2020: Cost of Goods Soldbeshahashenafe20No ratings yet
- Chapter 3Document120 pagesChapter 3beshahashenafe20No ratings yet
- Ch-3 (Planning Function)Document27 pagesCh-3 (Planning Function)beshahashenafe20No ratings yet
- Ch-6 (Staffing Function)Document25 pagesCh-6 (Staffing Function)beshahashenafe20No ratings yet
- Er DiagrammDocument2 pagesEr Diagrammbeshahashenafe20No ratings yet
- Hotel Management System in C++Document21 pagesHotel Management System in C++beshahashenafe20No ratings yet
- Deal Report Feb 14 - Apr 14Document26 pagesDeal Report Feb 14 - Apr 14BonviNo ratings yet
- Assembler Pass 2Document5 pagesAssembler Pass 2AnuNo ratings yet
- Rockaway Times 11818Document40 pagesRockaway Times 11818Peter J. MahonNo ratings yet
- Introduction-: Microprocessor 68000Document13 pagesIntroduction-: Microprocessor 68000margyaNo ratings yet
- B. Geoinformatics PDFDocument77 pagesB. Geoinformatics PDFmchakra720% (1)
- Turning PointsDocument2 pagesTurning Pointsapi-223780825No ratings yet
- B.SC BOTANY Semester 5-6 Syllabus June 2013Document33 pagesB.SC BOTANY Semester 5-6 Syllabus June 2013Barnali DuttaNo ratings yet
- Pt3 English Module 2018Document63 pagesPt3 English Module 2018Annie Abdul Rahman50% (4)
- Waterstop TechnologyDocument69 pagesWaterstop TechnologygertjaniNo ratings yet
- Pe 03 - Course ModuleDocument42 pagesPe 03 - Course ModuleMARIEL ASINo ratings yet
- Environmental Economics Pollution Control: Mrinal Kanti DuttaDocument253 pagesEnvironmental Economics Pollution Control: Mrinal Kanti DuttashubhamNo ratings yet
- An Exploration of The Ethno-Medicinal Practices Among Traditional Healers in Southwest Cebu, PhilippinesDocument7 pagesAn Exploration of The Ethno-Medicinal Practices Among Traditional Healers in Southwest Cebu, PhilippinesleecubongNo ratings yet
- Financial Accounting 2 SummaryDocument10 pagesFinancial Accounting 2 SummaryChoong Xin WeiNo ratings yet
- De Thi Hoc Ki 1 Mon Tieng Anh Lop 5 Co File NgheDocument10 pagesDe Thi Hoc Ki 1 Mon Tieng Anh Lop 5 Co File Nghetuyen truongNo ratings yet
- Role of Losses in Design of DC Cable For Solar PV ApplicationsDocument5 pagesRole of Losses in Design of DC Cable For Solar PV ApplicationsMaulidia HidayahNo ratings yet
- of Thesis ProjectDocument2 pagesof Thesis ProjectmoonNo ratings yet
- MRBR ATR 72 Rev18Document424 pagesMRBR ATR 72 Rev18Juan Forero OrtizNo ratings yet
- Classifications of AssessmentsDocument11 pagesClassifications of AssessmentsClaire CatapangNo ratings yet
- Ib History Command Term PostersDocument6 pagesIb History Command Term Postersapi-263601302100% (4)
- 3 Carbohydrates' StructureDocument33 pages3 Carbohydrates' StructureDilan TeodoroNo ratings yet
- Dalasa Jibat MijenaDocument24 pagesDalasa Jibat MijenaBelex ManNo ratings yet
- Rule 113 114Document7 pagesRule 113 114Shaila GonzalesNo ratings yet
- The Homework Song FunnyDocument5 pagesThe Homework Song Funnyers57e8s100% (1)
- 7400 IC SeriesDocument16 pages7400 IC SeriesRaj ZalariaNo ratings yet
- BNF Pos - StockmockDocument14 pagesBNF Pos - StockmockSatish KumarNo ratings yet
- IEC ShipsDocument6 pagesIEC ShipsdimitaringNo ratings yet
- Acute Coronary SyndromeDocument30 pagesAcute Coronary SyndromeEndar EszterNo ratings yet
- LetrasDocument9 pagesLetrasMaricielo Angeline Vilca QuispeNo ratings yet
- Damodaram Sanjivayya National Law University Visakhapatnam, A.P., IndiaDocument25 pagesDamodaram Sanjivayya National Law University Visakhapatnam, A.P., IndiaSumanth RoxtaNo ratings yet
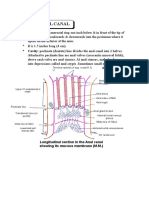
- Anatomy Anal CanalDocument14 pagesAnatomy Anal CanalBela Ronaldoe100% (1)