You might also like
- GADAG DoctorsDocument8 pagesGADAG DoctorsSumanth100% (2)
- Case 31 Digest GR 224498Document1 pageCase 31 Digest GR 224498Lorden Farrel100% (1)
- EDD X Bobobox CompressedDocument27 pagesEDD X Bobobox CompressedSpk ForteNo ratings yet
- 19CS413 LabManualDocument42 pages19CS413 LabManualGurunathanNo ratings yet
- CS3491 - Artificial Intelligence and Machine LearningDocument34 pagesCS3491 - Artificial Intelligence and Machine Learningparanjothi karthikNo ratings yet
- LAB Manual Part A: Experiment No.02Document12 pagesLAB Manual Part A: Experiment No.02BiatchNo ratings yet
- Ail&Ml Lab RecordDocument65 pagesAil&Ml Lab Recordbigbizzar123No ratings yet
- Aiml Lab Manual Upto DTDocument40 pagesAiml Lab Manual Upto DTsuganyacse24No ratings yet
- Lab Manual For AimlDocument27 pagesLab Manual For AimlDIYA MEERANo ratings yet
- AI and ML Lab ManualDocument29 pagesAI and ML Lab ManualRoobesh RoobeshNo ratings yet
- CS1503 AI Lab-1Document29 pagesCS1503 AI Lab-1dharunNo ratings yet
- Artificial Intelligence Lab File CompressDocument19 pagesArtificial Intelligence Lab File Compresskanta deviNo ratings yet
- Ai Record - 65Document20 pagesAi Record - 65SidharthNo ratings yet
- Dependency Graph and Bernstein ConditionsDocument39 pagesDependency Graph and Bernstein ConditionsSurbhi JainNo ratings yet
- Ai&ml Record (22-23)Document37 pagesAi&ml Record (22-23)Jesu VinNo ratings yet
- AIT Lab ManualDocument38 pagesAIT Lab ManualHari KrishnaNo ratings yet
- A Algorithm: Department of Computer Science & Engineering, NIT SrinagarDocument4 pagesA Algorithm: Department of Computer Science & Engineering, NIT SrinagarTaabishNo ratings yet
- Surya CadfsdDocument15 pagesSurya CadfsdSidharthNo ratings yet
- LAB Manual Part A: Experiment No.03Document8 pagesLAB Manual Part A: Experiment No.03BiatchNo ratings yet
- Uninformed Search AlgorithmsDocument58 pagesUninformed Search AlgorithmsAnkur GuptaNo ratings yet
- A60 AI Experiment03Document8 pagesA60 AI Experiment03BiatchNo ratings yet
- Lab Manual For AimlDocument28 pagesLab Manual For AimlDIYA MEERANo ratings yet
- Bscs-402 Data Structure Lab 5: Object 1Document8 pagesBscs-402 Data Structure Lab 5: Object 1Muhammad Anas RashidNo ratings yet
- CS3491 Ai & ML Lab ManualDocument57 pagesCS3491 Ai & ML Lab ManualDilipNo ratings yet
- AI Lab Manual For V 5SEM PDFDocument83 pagesAI Lab Manual For V 5SEM PDFsabiha.mahveenNo ratings yet
- 02 SystemVerilogLecture1Document31 pages02 SystemVerilogLecture1Mihaela ScanteianuNo ratings yet
- Exp 4Document6 pagesExp 4Agin LokeyNo ratings yet
- 3 - Stack Applications-Expression Conversion and EvaluationDocument18 pages3 - Stack Applications-Expression Conversion and Evaluationnaveen dsNo ratings yet
- Ishan Adhaulia: Assignment - 2Document12 pagesIshan Adhaulia: Assignment - 2Ishan AdhauliaNo ratings yet
- 2.3.3 Graph TraversingDocument19 pages2.3.3 Graph TraversingSomesh RamanNo ratings yet
- Dsa Lab ManualDocument77 pagesDsa Lab ManualPubg by yadnyavalk live streamersNo ratings yet
- Import Pandas As PDDocument10 pagesImport Pandas As PDnihalparteti26No ratings yet
- NAME: Kushal Singh REG - NO.: RA1911003030129 Subject: Artificial IntelligenceDocument11 pagesNAME: Kushal Singh REG - NO.: RA1911003030129 Subject: Artificial IntelligenceMitali MathurNo ratings yet
- Dsa 1Document136 pagesDsa 1Pratham MekhaleNo ratings yet
- ST - Mod3 - Chapter 9 - PathTesting - Part1Document22 pagesST - Mod3 - Chapter 9 - PathTesting - Part1Veenaxi PainginkarNo ratings yet
- Daa Lab Worksheet 3.1 (19bcs1880)Document10 pagesDaa Lab Worksheet 3.1 (19bcs1880)Sachin SinghNo ratings yet
- LAB 3: Binary Tree and Binary Search Tree EX1Document33 pagesLAB 3: Binary Tree and Binary Search Tree EX1Cao Minh Quang100% (1)
- MST-Solution Latest 2025Document12 pagesMST-Solution Latest 2025bndianonymousNo ratings yet
- Preeti Soni Lecturer (C S E) Rsrrcet Bhilai, C.GDocument61 pagesPreeti Soni Lecturer (C S E) Rsrrcet Bhilai, C.GBhupesh PandeyNo ratings yet
- DAA Module-2Document23 pagesDAA Module-2Krittika HegdeNo ratings yet
- Format of Sample ProjectDocument16 pagesFormat of Sample ProjectPiyushNo ratings yet
- Algorithm: Algorithm For Void InsertDocument10 pagesAlgorithm: Algorithm For Void InsertUtsyo ChakrabortyNo ratings yet
- 19MID0069 - Adv Algo - ETH DA-1Document21 pages19MID0069 - Adv Algo - ETH DA-1M puneethNo ratings yet
- 3.0 State Space Representation of ProblemsDocument18 pages3.0 State Space Representation of ProblemsnikwplayNo ratings yet
- Pig QueriesDocument5 pagesPig QueriesdudeNo ratings yet
- Applications of Bfs Algorithm: Backward Skip 10splay Videoforward Skip 10SDocument4 pagesApplications of Bfs Algorithm: Backward Skip 10splay Videoforward Skip 10SNitin KashyapNo ratings yet
- Ads ManualDocument53 pagesAds ManualRohit KumarNo ratings yet
- Ai LP-II Lab ManualDocument42 pagesAi LP-II Lab ManualAbubaker QureshiNo ratings yet
- A Star Ai and ML LabDocument3 pagesA Star Ai and ML LabHitesh Son SonNo ratings yet
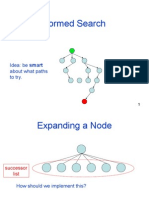
- Informed Search: Idea: Be Smart About What Paths To TryDocument31 pagesInformed Search: Idea: Be Smart About What Paths To Trytalhaaftab728No ratings yet
- Espanillo Midterm Exam Data Structure 2it2Document10 pagesEspanillo Midterm Exam Data Structure 2it2pia espanilloNo ratings yet
- Na Practical 2Document7 pagesNa Practical 22132145No ratings yet
- IAT-III Question Paper With Solution of 18CS71 Artificial Intelligence and Machine Learning (AI - ML) Jan-2022-Dr.P.Kavitha and Mr.G.Radha KrishnanDocument6 pagesIAT-III Question Paper With Solution of 18CS71 Artificial Intelligence and Machine Learning (AI - ML) Jan-2022-Dr.P.Kavitha and Mr.G.Radha KrishnanBrundaja D NNo ratings yet
- CSE221 Lab Assignment 04 Spring 2024: Submission GuidelinesDocument19 pagesCSE221 Lab Assignment 04 Spring 2024: Submission GuidelinesFAHAD NADIM ZIADNo ratings yet
- Ai - PFDocument30 pagesAi - PFIshan GadiNo ratings yet
- AI&SCnoww ContentDocument11 pagesAI&SCnoww ContentElliot AldersonNo ratings yet
- ComputerDocument37 pagesComputerPalakNo ratings yet
- Ai Practical FileDocument14 pagesAi Practical FileSo JaNo ratings yet
- CSE221 Lab 04 Graph Summer 2023Document19 pagesCSE221 Lab 04 Graph Summer 2023Ahnaf ShahriarNo ratings yet
- 19BCS2206 (Worksheet 3.1)Document5 pages19BCS2206 (Worksheet 3.1)NIKHIL SHARMANo ratings yet
- Ai&ml RecordDocument57 pagesAi&ml Recordhemapardeep8No ratings yet
- Aiml PDFDocument6 pagesAiml PDFJan JanNo ratings yet
- A Survey of Computational Physics: Introductory Computational ScienceFrom EverandA Survey of Computational Physics: Introductory Computational ScienceNo ratings yet
- Value Chain Analysis of Goat in South Omo Zone, SNNPR, EthiopiaDocument13 pagesValue Chain Analysis of Goat in South Omo Zone, SNNPR, EthiopiaPremier PublishersNo ratings yet
- NestléDocument2 pagesNestléMariana DíazNo ratings yet
- CoA PMA600HD GBDocument19 pagesCoA PMA600HD GBLuiz Marcos De OliveiraNo ratings yet
- Dragon #92 - Ecology of The EttinDocument3 pagesDragon #92 - Ecology of The EttinGeorge KrashosNo ratings yet
- Pump Suction Pipe Design ConsiderationsDocument7 pagesPump Suction Pipe Design ConsiderationsAbdulrahman Al HuribyNo ratings yet
- AHAN End of Project Factsheet - ENGDocument2 pagesAHAN End of Project Factsheet - ENGNaughty VongNo ratings yet
- The Spice House Beverage MenuDocument7 pagesThe Spice House Beverage MenuTan MaiNo ratings yet
- Guide For Alternative Inhalers During Stock Shortages Related To Coronavirus (COVID-19)Document2 pagesGuide For Alternative Inhalers During Stock Shortages Related To Coronavirus (COVID-19)Devs AbdouNo ratings yet
- National Health Policies and Community HealthcareDocument14 pagesNational Health Policies and Community Healthcareatharva sawantNo ratings yet
- Process Structure Property Relationship of Meltblown NVDocument12 pagesProcess Structure Property Relationship of Meltblown NVMusical Black DiaryNo ratings yet
- Basic Defrost Controller Installation Guide: Basic Controller For Refrigerated Cabinets, With Energy-Saving StrategiesDocument2 pagesBasic Defrost Controller Installation Guide: Basic Controller For Refrigerated Cabinets, With Energy-Saving StrategiesNelson DiazNo ratings yet
- Nightingale Institute of Nursing Noida: Seminar ON Code of Ethics Subject: Advance Nursing PracticeDocument11 pagesNightingale Institute of Nursing Noida: Seminar ON Code of Ethics Subject: Advance Nursing Practicesahib singhNo ratings yet
- Botany - 1 (E.m) - 1,2,3,4,5,8,11,13Document149 pagesBotany - 1 (E.m) - 1,2,3,4,5,8,11,13Suresh BabuNo ratings yet
- Bearing Lubrication Quick Reference Guide: Grease CompatibilityDocument4 pagesBearing Lubrication Quick Reference Guide: Grease CompatibilitySamuel PagottoNo ratings yet
- Ap Environmental Science Course DescriptionDocument27 pagesAp Environmental Science Course Descriptionapi-366056267No ratings yet
- This Study Resource Was: in A NutshellDocument2 pagesThis Study Resource Was: in A NutshellAdam Cuenca100% (3)
- Soya MSDSDocument3 pagesSoya MSDSmarkos_za3817100% (1)
- ASTM 1556-4 - Chloride Penetration OverviewDocument15 pagesASTM 1556-4 - Chloride Penetration OverviewRavi SinghNo ratings yet
- Path EmqsDocument9 pagesPath EmqsmuhannedNo ratings yet
- Calorific Value and Bomb's CalorimeterDocument10 pagesCalorific Value and Bomb's Calorimeterparvezalamkhan62% (13)
- ROHANDocument10 pagesROHANRohan HundareNo ratings yet
- Teaching Teachers About Emotion Regulation in The ClassroomDocument12 pagesTeaching Teachers About Emotion Regulation in The ClassroomPRIMARIA CSTNo ratings yet
- Steam Power PlantDocument56 pagesSteam Power PlantصصNo ratings yet
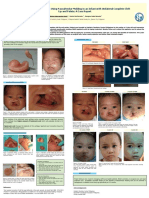
- Benefits of Early Treatment Using Nasoalveolar Molding in An Infant With Unilateral Complete Cleft Lip and Palate A Case ReportDocument1 pageBenefits of Early Treatment Using Nasoalveolar Molding in An Infant With Unilateral Complete Cleft Lip and Palate A Case ReportGabriellaMariaNo ratings yet
- Polycoat Rbe PDFDocument2 pagesPolycoat Rbe PDFAmer GonzalesNo ratings yet
- R171 Vario Roof Troubleshooting TreeDocument30 pagesR171 Vario Roof Troubleshooting TreeBadi TrsatNo ratings yet
- Chromosomalabnormalities 150413160537 Conversion Gate01Document25 pagesChromosomalabnormalities 150413160537 Conversion Gate01John MccartneyNo ratings yet