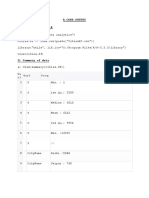
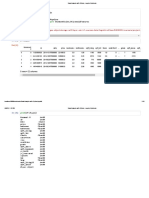
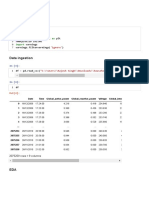
You might also like
- 2-2-Notice of Fault in DishonorDocument3 pages2-2-Notice of Fault in DishonorZIONCREDITGROUP100% (12)
- Real Estate Investment CalculationsDocument12 pagesReal Estate Investment CalculationsJorge Nunes100% (1)
- Project Linear RegressionDocument7 pagesProject Linear RegressionCalo SoftNo ratings yet
- Matts Advanced Well Control Kill Sheet Ra 07261Document21 pagesMatts Advanced Well Control Kill Sheet Ra 07261CARLOS RODRIGUEZNo ratings yet
- 3 Notice of RebuttalDocument2 pages3 Notice of RebuttalJonahs gospelNo ratings yet
- MR John Doe 522 Flinders ST, Melbourne VIC 3000: Summary of AccountsDocument4 pagesMR John Doe 522 Flinders ST, Melbourne VIC 3000: Summary of Accountsmohamed elmakhzni100% (2)
- Crockford NumbersDocument64 pagesCrockford NumbersalamotNo ratings yet
- SMDM Final - Jupyter NotebookDocument17 pagesSMDM Final - Jupyter NotebookDeepak Mahindra100% (1)
- Komatsu Pc27 Pc30 Pc35 Pc40 Pc50 Mr2 Shop ManualDocument20 pagesKomatsu Pc27 Pc30 Pc35 Pc40 Pc50 Mr2 Shop Manualdavid100% (51)
- Pricing Swap Default RiskDocument11 pagesPricing Swap Default RiskUmlol TitaniNo ratings yet
- Articles of Partnership For General PartnershipsDocument14 pagesArticles of Partnership For General PartnershipsJeson MalinaoNo ratings yet
- Digital Electronics For Engineering and Diploma CoursesFrom EverandDigital Electronics For Engineering and Diploma CoursesNo ratings yet
- Sugar MillDocument26 pagesSugar MillRaman AhitanNo ratings yet
- Experian White Paper Fintech Led Digital LendingDocument37 pagesExperian White Paper Fintech Led Digital LendingSiddharth RoyNo ratings yet
- Test Bank - Income Taxation-CparDocument5 pagesTest Bank - Income Taxation-CparStephanie Ann TubuNo ratings yet
- Risk ManagementDocument14 pagesRisk ManagementMichelle TNo ratings yet
- Blu Dayz Spa Business and Marketing Plan - International ManagementDocument39 pagesBlu Dayz Spa Business and Marketing Plan - International ManagementYannick Harvey100% (2)
- Dpdzero AssessmentDocument12 pagesDpdzero AssessmenthiteshNo ratings yet
- K MedoidsDocument10 pagesK Medoidsprerna sharmaNo ratings yet
- Buy Vs Rent Decision Assignment Given DataDocument4 pagesBuy Vs Rent Decision Assignment Given DataMOVIES SHOPNo ratings yet
- Dataset and Visualization: Ames Set UCI Machine Learning Datasets (Https://archive - Ics.uci - Edu/ml/index - PHP)Document4 pagesDataset and Visualization: Ames Set UCI Machine Learning Datasets (Https://archive - Ics.uci - Edu/ml/index - PHP)Hamed GholamiNo ratings yet
- HW 4 AndalibDocument23 pagesHW 4 AndalibAndalib ShamsNo ratings yet
- Yash Week 3 Uber Case StudyDocument38 pagesYash Week 3 Uber Case StudySunil KhambhojaNo ratings yet
- Decision TreeDocument12 pagesDecision TreeKagade AjinkyaNo ratings yet
- KPR Installment Payment Records TableDocument4 pagesKPR Installment Payment Records Tablerudy wibowoNo ratings yet
- Customer Retention in BankDocument27 pagesCustomer Retention in BankHarun ul Rasheed ShaikNo ratings yet
- Uber Data AnalysisDocument16 pagesUber Data Analysisamit jshNo ratings yet
- Business Research: Corporate Governance in Financial Institutions of BangladeshDocument31 pagesBusiness Research: Corporate Governance in Financial Institutions of BangladeshShahriar HaqueNo ratings yet
- Predict Impurity in Mined Ore - 1Document6 pagesPredict Impurity in Mined Ore - 1Prashant KumarNo ratings yet
- Respuestas de LINDODocument5 pagesRespuestas de LINDOJosé GalindoNo ratings yet
- Section B: R Programming OutputDocument19 pagesSection B: R Programming Outputprashantarora18No ratings yet
- Uber Data Analysis: Data Import and Sanity ChecksDocument16 pagesUber Data Analysis: Data Import and Sanity ChecksMeghapriya1234No ratings yet
- K-Nearest NeighborsDocument32 pagesK-Nearest NeighborsThành Cao ĐứcNo ratings yet
- Challenge MihaiDocument39 pagesChallenge MihaiMihai CătaNo ratings yet
- Simulation-Monte CarloDocument17 pagesSimulation-Monte CarloIGNo ratings yet
- Operations Management-II Case - Megacard CorporationDocument7 pagesOperations Management-II Case - Megacard CorporationDikshma PaulNo ratings yet
- VIVIENDA UNIFAMILIAR SkyCiv Report PDFDocument36 pagesVIVIENDA UNIFAMILIAR SkyCiv Report PDF@wongNo ratings yet
- Y - Bus Matrix For IEEE 14 BusDocument2 pagesY - Bus Matrix For IEEE 14 BusSiva KumarNo ratings yet
- Review Guide W/ Tables For Depreciation & TaxesDocument29 pagesReview Guide W/ Tables For Depreciation & Taxesjer7313No ratings yet
- GridDocument9 pagesGridLukas Nghiem Duy HaiNo ratings yet
- Kelompok 9 Rekayasa JalanDocument10 pagesKelompok 9 Rekayasa JalanMuh Fadhel AbrarNo ratings yet
- Nodel Demand Calculation of Zone 01 (Diet College Elsr) : 0.0017 3.0 (As Per CPHEEO Manual Population Below 50000)Document6 pagesNodel Demand Calculation of Zone 01 (Diet College Elsr) : 0.0017 3.0 (As Per CPHEEO Manual Population Below 50000)rajsedasariNo ratings yet
- 30 SepDocument13 pages30 SepSanjay KumarNo ratings yet
- R 0.07 FV 200,000 PV 125,000 142,597 Tenure 5Document12 pagesR 0.07 FV 200,000 PV 125,000 142,597 Tenure 5Sanjana AgarwalNo ratings yet
- Capstone Project Output - Hotel Room Pricing in Indian CitiesDocument23 pagesCapstone Project Output - Hotel Room Pricing in Indian CitiesShrey Shailesh ShahNo ratings yet
- Data Analysis With Python - Jupyter NotebookDocument10 pagesData Analysis With Python - Jupyter NotebookNitish RavuvariNo ratings yet
- Reading CSV Data Python ExampleDocument5 pagesReading CSV Data Python ExampleTamanna ManekNo ratings yet
- Decision Tree Regressor and Ensemble Techniques - RegressorsDocument18 pagesDecision Tree Regressor and Ensemble Techniques - RegressorsS ANo ratings yet
- Year ACCOUNT Balance at Start of Year Start of Year Deposit Interest Earned at Start of YearDocument19 pagesYear ACCOUNT Balance at Start of Year Start of Year Deposit Interest Earned at Start of YearAimen AyubNo ratings yet
- Balance Comprobacion 2020-2021 SOLES PSGDocument16 pagesBalance Comprobacion 2020-2021 SOLES PSGDiego Alonso Galvez CaloggeroNo ratings yet
- Pivot TableDocument7 pagesPivot Tableankit05101998No ratings yet
- S7 StudentDocument12 pagesS7 StudentSameer MajhiNo ratings yet
- DATA DCP 1 KP LamprganDocument379 pagesDATA DCP 1 KP LamprganNadiah KhairunnisaNo ratings yet
- BA 2802 - Principles of Finance Solutions To Problems For Recitation #5Document7 pagesBA 2802 - Principles of Finance Solutions To Problems For Recitation #5Eda Nur EvginNo ratings yet
- Extended - Basic Eda Python FellowDocument22 pagesExtended - Basic Eda Python FellowRosarioNo ratings yet
- DataWrangling - Jupyter NotebookDocument24 pagesDataWrangling - Jupyter NotebookYash ShindeNo ratings yet
- EDA Dumps 2 PDFDocument47 pagesEDA Dumps 2 PDFSamuel Lambrecht100% (1)
- EDA and Similarity of Transactions On CreditCardFraudDetectionDocument66 pagesEDA and Similarity of Transactions On CreditCardFraudDetectiongopisaiNo ratings yet
- 11-Cost Behavior AnalysisDocument34 pages11-Cost Behavior AnalysisVrgawan 12No ratings yet
- Capastone Project Taiwan Customer DefaultDocument36 pagesCapastone Project Taiwan Customer Defaultsumit kumar67% (3)
- Bhavik Excel CourceDocument13 pagesBhavik Excel Courceviraj shahNo ratings yet
- Solution PlusDocument5 pagesSolution PlusKanishka AdvaniNo ratings yet
- Day 2 Formulas and FunctionsDocument8 pagesDay 2 Formulas and FunctionsShubham KulkarniNo ratings yet
- Derivatives Test 3 SolnDocument12 pagesDerivatives Test 3 SolnHetviNo ratings yet
- American Airlines Flight Arrival Delay AnalysisDocument11 pagesAmerican Airlines Flight Arrival Delay AnalysisHyder MurtazaNo ratings yet
- Distribution and Network Models: 6.1 Transportation ProblemDocument28 pagesDistribution and Network Models: 6.1 Transportation ProblemUrbi Roy BarmanNo ratings yet
- Using Tensorflow To Predict Jet Numbers in Cern Proton Collisions (Evaluator-Omid-Baghcheh-Saraei)Document29 pagesUsing Tensorflow To Predict Jet Numbers in Cern Proton Collisions (Evaluator-Omid-Baghcheh-Saraei)David EsparzaArellanoNo ratings yet
- Raw Data Netincome Tax Rate Tax in Non-Slab System Tax in Slab SystemDocument6 pagesRaw Data Netincome Tax Rate Tax in Non-Slab System Tax in Slab SystemxxxNo ratings yet
- Task 2 - YehloDocument3 pagesTask 2 - YehlohiteshNo ratings yet
- Virtue Market Research AssignmentDocument3 pagesVirtue Market Research AssignmenthiteshNo ratings yet
- SQL Case Study 2Document6 pagesSQL Case Study 2hiteshNo ratings yet
- UI UX IIT GuwahatiDocument13 pagesUI UX IIT GuwahatihiteshNo ratings yet
- SQL Interview Questuons and AnswersDocument10 pagesSQL Interview Questuons and AnswershiteshNo ratings yet
- Ar BMWM 2018Document39 pagesAr BMWM 2018hiteshNo ratings yet
- Polymers 11 00461Document17 pagesPolymers 11 00461hiteshNo ratings yet
- Recycling of Hospital Waste PDFDocument5 pagesRecycling of Hospital Waste PDFhiteshNo ratings yet
- A Review On Brake Pad Materials and Methods of ProductionDocument7 pagesA Review On Brake Pad Materials and Methods of ProductionhiteshNo ratings yet
- Design and Development of NSUT Bio-Medical Waste ManagementDocument13 pagesDesign and Development of NSUT Bio-Medical Waste ManagementhiteshNo ratings yet
- Bio-Medical Waste Management (BMWM) Rules, 2016Document2 pagesBio-Medical Waste Management (BMWM) Rules, 2016hiteshNo ratings yet
- DR Avm Composite An IntroductionDocument46 pagesDR Avm Composite An IntroductionhiteshNo ratings yet
- Donation Letter BRVP SBIDocument1 pageDonation Letter BRVP SBIhiteshNo ratings yet
- Experiment - 1: OBJECTIVE - Study and Demonstration of Mechatronic System and ItsDocument8 pagesExperiment - 1: OBJECTIVE - Study and Demonstration of Mechatronic System and ItshiteshNo ratings yet
- Gearless Transmission: College of Engineering &technology Ghatikia, Bhubaneswar, Odisha - 751003, IndiaDocument32 pagesGearless Transmission: College of Engineering &technology Ghatikia, Bhubaneswar, Odisha - 751003, IndiahiteshNo ratings yet
- Competition Commission of IndiaDocument2 pagesCompetition Commission of Indiaankita_impressionNo ratings yet
- MatematikDocument13 pagesMatematikVinisha NishaNo ratings yet
- Gih Casestudy Usa Port-Of-miami TunnelDocument8 pagesGih Casestudy Usa Port-Of-miami TunnelibitzisNo ratings yet
- Destructive Rule of The BJP From1998 To 2004: Destructive Agricultural Polices Which Resulted in Farmers SuicidesDocument18 pagesDestructive Rule of The BJP From1998 To 2004: Destructive Agricultural Polices Which Resulted in Farmers Suicidesyogesh saxenaNo ratings yet
- Karen Tappert Indicted On Mortgage Rescue Scheme - California, Nevada and New MexicoDocument20 pagesKaren Tappert Indicted On Mortgage Rescue Scheme - California, Nevada and New Mexico83jjmackNo ratings yet
- 25 CFR Part 20 Regulations PDF FormatDocument41 pages25 CFR Part 20 Regulations PDF FormatacooninNo ratings yet
- AB1201 Course Outline 2014 - 2015 - Sem1Document7 pagesAB1201 Course Outline 2014 - 2015 - Sem1milkshakechocolateNo ratings yet
- Apollo Tyres Limited: Rating RationaleDocument4 pagesApollo Tyres Limited: Rating Rationaleragha_4544vNo ratings yet
- Lease Agreement of House Rent-1Document2 pagesLease Agreement of House Rent-1Ashu KunwarNo ratings yet
- CA Final Law Summary Notes As Per Companies Act 2013 2N80Q4UQDocument252 pagesCA Final Law Summary Notes As Per Companies Act 2013 2N80Q4UQSuppy P0% (1)
- Pay Slip: C4 & D6 Sipcot Industrial Complex Gummidipoondi-601 201, Tamilnadu, India. Phone: 044Document2 pagesPay Slip: C4 & D6 Sipcot Industrial Complex Gummidipoondi-601 201, Tamilnadu, India. Phone: 044Sridharan VenkatNo ratings yet
- iLLUSTRATION OF LUMP SUM LIQUIDATION FOR ENCODINGDocument14 pagesiLLUSTRATION OF LUMP SUM LIQUIDATION FOR ENCODINGMaria Kathreena Andrea AdevaNo ratings yet
- Deed AFFIDAVITDocument4 pagesDeed AFFIDAVITIndranilGhoshNo ratings yet
- LDNA Tool FinancialDocument2 pagesLDNA Tool FinancialJonathan Marc Fule CastilloNo ratings yet
- West Bengal Vat Act 2003 Amended Upto 28.05.14Document191 pagesWest Bengal Vat Act 2003 Amended Upto 28.05.14kavi_prakash6992No ratings yet
- Appendix GDocument3 pagesAppendix GYardie TreyBwoy100% (1)
- Income Collection Deposit System With ConversionDocument6 pagesIncome Collection Deposit System With ConversionDane LavegaNo ratings yet
- A Project Report On Technical Analysis at Share KhanDocument105 pagesA Project Report On Technical Analysis at Share KhanBabasab Patil (Karrisatte)100% (3)
- Critical Net WorthDocument3 pagesCritical Net WorthXicaveNo ratings yet
- Effect of Bank Credit On Small Scale Entrepreneurial Development in NigeriaDocument59 pagesEffect of Bank Credit On Small Scale Entrepreneurial Development in NigeriaJoshua Ayomide OyadokunNo ratings yet
- IFM3Document4 pagesIFM3Nattaporn PrakobpornNo ratings yet