You might also like
- Grade 6 Harmony Course and Exercises PreviewDocument10 pagesGrade 6 Harmony Course and Exercises Previewwenwen16049988% (8)
- Essentials of Machine Learning AlgorithmsDocument15 pagesEssentials of Machine Learning AlgorithmsAndres ValenciaNo ratings yet
- Design of Bolted Beam Splice Connections According To EC3Document11 pagesDesign of Bolted Beam Splice Connections According To EC3Franklyn Genove100% (2)
- Machine Learning BitsDocument28 pagesMachine Learning Bitsvyshnavi100% (2)
- Curve Fitting With MatlabDocument38 pagesCurve Fitting With Matlabtanushrisharma100% (1)
- E-Tivity 2.2 Tharcisse 217010849Document7 pagesE-Tivity 2.2 Tharcisse 217010849Tharcisse Tossen TharryNo ratings yet
- WaveguideDocument32 pagesWaveguideBeverly Paman100% (2)
- Empilhadeira YALEDocument264 pagesEmpilhadeira YALEReinaldo Pimentel Sebastião75% (8)
- IMonitor User Guide IDX3Document264 pagesIMonitor User Guide IDX3WellingtonNo ratings yet
- Machine LearningDocument115 pagesMachine LearningRaja Meenakshi100% (4)
- Determining The Amount of Material Finer Than 75 - M (No. 200) Sieve in Soils by WashingDocument6 pagesDetermining The Amount of Material Finer Than 75 - M (No. 200) Sieve in Soils by WashingIecsa IngenieriaNo ratings yet
- ML Lab - Sukanya RajaDocument23 pagesML Lab - Sukanya RajaRick MitraNo ratings yet
- Chandigarh Group of Colleges College of Engineering Landran, MohaliDocument47 pagesChandigarh Group of Colleges College of Engineering Landran, Mohalitanvi wadhwaNo ratings yet
- ML Practical FileDocument43 pagesML Practical FilePankaj Singh100% (1)
- Data MiningDocument98 pagesData MiningJijeesh BaburajanNo ratings yet
- CS 601 Machine Learning Unit 5Document18 pagesCS 601 Machine Learning Unit 5Priyanka BhateleNo ratings yet
- Lab NN KNN SVMDocument13 pagesLab NN KNN SVMmaaian.iancuNo ratings yet
- Ebook To Become ML EngineerDocument21 pagesEbook To Become ML Engineerమయూ ఖNo ratings yet
- Data MiningDocument18 pagesData Miningayushchoudhary20289No ratings yet
- Broadly, There Are 3 Types of Machine Learning Algorithms.Document33 pagesBroadly, There Are 3 Types of Machine Learning Algorithms.hbk.hariharanNo ratings yet
- ML AlgorithmsDocument12 pagesML AlgorithmsShivendra ChandNo ratings yet
- Logistic RegressionDocument10 pagesLogistic RegressionChichi Jnr100% (1)
- Evaluation of Different ClassifierDocument4 pagesEvaluation of Different ClassifierTiwari VivekNo ratings yet
- Lecture 2: Basics and Definitions: Networks As Data ModelsDocument28 pagesLecture 2: Basics and Definitions: Networks As Data ModelsshardapatelNo ratings yet
- Machine Learning AssignmentsDocument3 pagesMachine Learning AssignmentsUjesh MauryaNo ratings yet
- 4 DataAnalyics Part1Document59 pages4 DataAnalyics Part1Ali Shana'aNo ratings yet
- Module2 Ids 240201 162026Document11 pagesModule2 Ids 240201 162026sachinsachitha1321No ratings yet
- Parameter EstimationDocument24 pagesParameter EstimationMina Arya100% (1)
- DS Unit 2 Essay AnswersDocument17 pagesDS Unit 2 Essay AnswersSavitha ElluruNo ratings yet
- 20dit073 Jay Prajapati MLDocument68 pages20dit073 Jay Prajapati MLJay PrajapatiNo ratings yet
- Tutorial For Machine LearningDocument14 pagesTutorial For Machine LearningRaji RamachandranNo ratings yet
- Commonly Used Machine Learning AlgorithmsDocument27 pagesCommonly Used Machine Learning Algorithmssbs Analytics19-21No ratings yet
- CS583 ClusteringDocument40 pagesCS583 ClusteringruoibmtNo ratings yet
- Whole ML PDF 1614408656Document214 pagesWhole ML PDF 1614408656Kshatrapati Singh100% (1)
- Q. 1) What Is Class Condition Density? (3 Marks) AnsDocument12 pagesQ. 1) What Is Class Condition Density? (3 Marks) AnsMrunal BhilareNo ratings yet
- Assignment 2 With ProgramDocument8 pagesAssignment 2 With ProgramPalash SarowareNo ratings yet
- Commonly Used Machine Learning AlgorithmsDocument38 pagesCommonly Used Machine Learning AlgorithmsashokmvanjareNo ratings yet
- Probabilistic Feature Selection and Classification Vector MachineDocument27 pagesProbabilistic Feature Selection and Classification Vector Machinenandini bubNo ratings yet
- Dar Unit-4Document23 pagesDar Unit-4Kalyan VarmaNo ratings yet
- Introduction To ML Partial 2 PDFDocument54 pagesIntroduction To ML Partial 2 PDFLesocrateNo ratings yet
- House Price Prediction Using Machine Learning in PythonDocument13 pagesHouse Price Prediction Using Machine Learning in PythonMayank Vasisth GandhiNo ratings yet
- g (y) = βo + β (Age) - (a)Document6 pagesg (y) = βo + β (Age) - (a)k767No ratings yet
- Model DefinitionDocument6 pagesModel Definitionk767No ratings yet
- Model Definition11Document6 pagesModel Definition11k767No ratings yet
- 9 Unsupervised Learning: 9.1 K-Means ClusteringDocument34 pages9 Unsupervised Learning: 9.1 K-Means ClusteringJavier RivasNo ratings yet
- Linear Regression - Numpy and SklearnDocument7 pagesLinear Regression - Numpy and SklearnArala FolaNo ratings yet
- Linear RegressionDocument29 pagesLinear RegressionSoubhav ChamanNo ratings yet
- Divide and ConquerDocument28 pagesDivide and ConquerAsafAhmadNo ratings yet
- Machine Learning NotesDocument6 pagesMachine Learning NotesNikhita NairNo ratings yet
- Mlaifile1 3Document27 pagesMlaifile1 3Krishna kumarNo ratings yet
- Types of Machine Learning: Supervised Learning: The Computer Is Presented With Example Inputs and TheirDocument50 pagesTypes of Machine Learning: Supervised Learning: The Computer Is Presented With Example Inputs and TheirJayesh GadewarNo ratings yet
- HW2 For Students PDFDocument5 pagesHW2 For Students PDFmsk123123No ratings yet
- Gradient Descent AlgorithmDocument5 pagesGradient Descent AlgorithmravinyseNo ratings yet
- Linear Regression Simple Technique For IDocument3 pagesLinear Regression Simple Technique For IbAxTErNo ratings yet
- Lab 4: Logistic Regression: PSTAT 131/231, Winter 2019Document10 pagesLab 4: Logistic Regression: PSTAT 131/231, Winter 2019vidish laheriNo ratings yet
- Interview Preparing - ML DraftDocument12 pagesInterview Preparing - ML Draftالريس حمادةNo ratings yet
- Data AnalysisDocument8 pagesData AnalysisTayar ElieNo ratings yet
- Implementing The Fuzzy C-Means Algorithm: by Gagarine YaikhomDocument15 pagesImplementing The Fuzzy C-Means Algorithm: by Gagarine YaikhomBachtiar AzharNo ratings yet
- Aakash S Project ReportDocument12 pagesAakash S Project ReportVivekNo ratings yet
- Machine Learning QNADocument1 pageMachine Learning QNApratikmovie999No ratings yet
- Data Cluster Algorithms in Product Purchase SaleanalysisDocument6 pagesData Cluster Algorithms in Product Purchase SaleanalysisQuenton CompasNo ratings yet
- Aychew ChernetDocument8 pagesAychew ChernetaychewchernetNo ratings yet
- TD2345Document3 pagesTD2345ashitaka667No ratings yet
- Line Drawing Algorithm: Mastering Techniques for Precision Image RenderingFrom EverandLine Drawing Algorithm: Mastering Techniques for Precision Image RenderingNo ratings yet
- Bab 1.2 Operasi Asas Aritmetik Yang Melibatkan IntegerDocument4 pagesBab 1.2 Operasi Asas Aritmetik Yang Melibatkan Integerg-78345632No ratings yet
- TSReader Software SupportDocument4 pagesTSReader Software SupportDramane BonkoungouNo ratings yet
- Unit 1.1 - System of Coplanar ForcesDocument35 pagesUnit 1.1 - System of Coplanar ForcesRohan100% (2)
- Alia AUF750 Non-Intrusive Ultrasonic FlowmeterDocument4 pagesAlia AUF750 Non-Intrusive Ultrasonic FlowmeterRexCrazyMindNo ratings yet
- DOKAFORMDocument8 pagesDOKAFORMpraupdNo ratings yet
- Thii 111Document62 pagesThii 111Tăng Anh TuấnNo ratings yet
- Person Name: NDT Management CoordinatorDocument4 pagesPerson Name: NDT Management CoordinatorDendy PratamaNo ratings yet
- MCS 024 Previous Year Question Papers by Ignouassignmentguru - 2Document66 pagesMCS 024 Previous Year Question Papers by Ignouassignmentguru - 2chandrakanthatsNo ratings yet
- 04 BM+CIV 2012 - Shoring and ScaffoldingDocument45 pages04 BM+CIV 2012 - Shoring and ScaffoldingDaniel AlemayehuNo ratings yet
- Discovering Computers 2010: Living in A Digital WorldDocument44 pagesDiscovering Computers 2010: Living in A Digital Worldnavin212No ratings yet
- VLSI 100 QuestionsDocument2 pagesVLSI 100 QuestionsAman BatraNo ratings yet
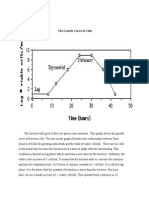
- The Growth Curve of CellsDocument3 pagesThe Growth Curve of CellsRisky KikiNo ratings yet
- Apostila GgplotDocument59 pagesApostila GgplotBreno Benvindo Dos AnjosNo ratings yet
- Q4 Formulating Hypothesis 2Document18 pagesQ4 Formulating Hypothesis 2Rhonalyn Angel GalanoNo ratings yet
- LCD 128x64 Tech12864GDocument10 pagesLCD 128x64 Tech12864GMarlon PerinNo ratings yet
- F TestDocument7 pagesF TestShamik MisraNo ratings yet
- Learn Kotlin - Data Types & Variables Cheatsheet - CodecademyDocument3 pagesLearn Kotlin - Data Types & Variables Cheatsheet - CodecademyIliasAhmedNo ratings yet
- Electrical Supply SustemDocument13 pagesElectrical Supply SustemZulHilmi ZakariaNo ratings yet
- 2344Document38 pages2344Bhavya BhavyaNo ratings yet
- Reverse OsmosisDocument18 pagesReverse OsmosisDIPAK VINAYAK SHIRBHATE67% (3)
- Effects of Dietary Single Cell Protein On African CatfishDocument5 pagesEffects of Dietary Single Cell Protein On African CatfishCoonzeeNo ratings yet
- Cost Estimation-Case Study PDFDocument11 pagesCost Estimation-Case Study PDFTausique Sheikh100% (1)
- Chemisty Unit PlanDocument6 pagesChemisty Unit Planapi-266413007No ratings yet
- DAC-4 Data Sheet E R13 20151005Document12 pagesDAC-4 Data Sheet E R13 20151005Ricardo Felipe Cortes MenayNo ratings yet