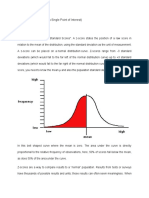
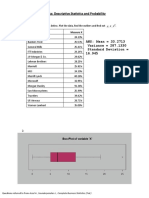
You might also like
- Z ScoresDocument27 pagesZ ScoresSoma San JoseNo ratings yet
- Standard Deviation and Its ApplicationsDocument8 pagesStandard Deviation and Its Applicationsanon_882394540100% (1)
- Hypothesis TestingDocument44 pagesHypothesis Testinganpyaa100% (1)
- Sample Size for Analytical Surveys, Using a Pretest-Posttest-Comparison-Group DesignFrom EverandSample Size for Analytical Surveys, Using a Pretest-Posttest-Comparison-Group DesignNo ratings yet
- SMDM Project Report-Survi GhuraDocument26 pagesSMDM Project Report-Survi GhuraAshish Gupta100% (1)
- Analysis Interpretation and Use of Test DataDocument50 pagesAnalysis Interpretation and Use of Test DataJayson EsperanzaNo ratings yet
- Normal Random VariableDocument8 pagesNormal Random VariableLoraine Buen FranciscoNo ratings yet
- Lesson 3 - T-Distribution (Module)Document26 pagesLesson 3 - T-Distribution (Module)charmaine marasigan100% (1)
- Standard Scores and The Normal Curve: Report Presentation byDocument38 pagesStandard Scores and The Normal Curve: Report Presentation byEmmanuel AbadNo ratings yet
- Describing Data Numerically - Activity-SKDocument6 pagesDescribing Data Numerically - Activity-SKShamari DavisNo ratings yet
- Normal DistributionDocument29 pagesNormal DistributionMohamed Abd El-MoniemNo ratings yet
- Descriptive Statistics MBADocument7 pagesDescriptive Statistics MBAKritika Jaiswal100% (2)
- Fulgar - 9040 Standard Normal DistributionDocument29 pagesFulgar - 9040 Standard Normal Distributioneugene louie ibarraNo ratings yet
- Z-Score: Definition, Calculation and InterpretationDocument5 pagesZ-Score: Definition, Calculation and Interpretationppkuldeep4No ratings yet
- Z - ScoreDocument12 pagesZ - ScoreSam SamNo ratings yet
- Z ScoreDocument1 pageZ ScoreAltamas RehanNo ratings yet
- Report Educl-MeasurementDocument21 pagesReport Educl-MeasurementLorna Dollisen Labrada - MiguelaNo ratings yet
- (Assignment) (Business) (International Analysis)Document4 pages(Assignment) (Business) (International Analysis)Sheraz Aslam SherazNo ratings yet
- Module Using The Empirical RuleDocument14 pagesModule Using The Empirical RuleIzyle CabrigaNo ratings yet
- Basic Stats InformationDocument16 pagesBasic Stats InformationShankar SubramanianNo ratings yet
- Assessment in Learning 1 Standard Scores I. ObjectivesDocument3 pagesAssessment in Learning 1 Standard Scores I. ObjectivesSymon FeolinoNo ratings yet
- Normal Distribution1Document8 pagesNormal Distribution1ely san100% (1)
- Normal DistributionDocument8 pagesNormal DistributionMai MomayNo ratings yet
- 13 ZscoresDocument13 pages13 ZscoresMhelvyn RamiscalNo ratings yet
- Normal Curve PowerpointDocument18 pagesNormal Curve PowerpointKatherine PanganibanNo ratings yet
- Written Report Z-ScoresDocument3 pagesWritten Report Z-ScoresEilishNo ratings yet
- 5 Z&NormalDocument33 pages5 Z&NormalRosemarie GasparNo ratings yet
- BS-chapter3-2021-Z - Score or STD ScoreDocument17 pagesBS-chapter3-2021-Z - Score or STD ScorefarwaNo ratings yet
- Saint Joseph College Senior High School Department Tunga-Tunga, Maasin City, Southern Leyte 6600 PhilippinesDocument11 pagesSaint Joseph College Senior High School Department Tunga-Tunga, Maasin City, Southern Leyte 6600 PhilippinesJimkenneth RanesNo ratings yet
- Normal Probability Curve: Dr. Kuldeep KaurDocument36 pagesNormal Probability Curve: Dr. Kuldeep KaurKanchan ManhasNo ratings yet
- Normal Probability Curve: Dr. K Uldeep KaurDocument37 pagesNormal Probability Curve: Dr. K Uldeep KaurK M TripathiNo ratings yet
- Ambo University Waliso Campus: Statistics For MGT I: Normal Distributions (Continuous Probability Distributions)Document121 pagesAmbo University Waliso Campus: Statistics For MGT I: Normal Distributions (Continuous Probability Distributions)keransotadeseNo ratings yet
- Statistics - Own CompilationDocument20 pagesStatistics - Own Compilationbogdan_de_romaniaNo ratings yet
- Z-Score Problems With The Normal Model: ObjectiveDocument24 pagesZ-Score Problems With The Normal Model: ObjectiveCleverton da VeigaNo ratings yet
- Normal 30Document2 pagesNormal 30Kerdid SimbolonNo ratings yet
- Lecture 3 Notes - PSYC 204Document8 pagesLecture 3 Notes - PSYC 204SerenaNo ratings yet
- Chapter 8 - Confidence Interval EstimationDocument5 pagesChapter 8 - Confidence Interval EstimationcleofecaloNo ratings yet
- Lesson 8 Mathematics in The Modern World October 19 2021Document10 pagesLesson 8 Mathematics in The Modern World October 19 2021Reabels FranciscoNo ratings yet
- Z Score Z Table LectureDocument5 pagesZ Score Z Table Lecturecurimao.403101150053No ratings yet
- Z-Score TableDocument8 pagesZ-Score TableThy Trương PhươngNo ratings yet
- Normal Distribution and Probability Distribution FunctionDocument5 pagesNormal Distribution and Probability Distribution Functionvs6886No ratings yet
- Understanding Z-Scores: Many Different Normal DistributionsDocument6 pagesUnderstanding Z-Scores: Many Different Normal Distributionslope pecayoNo ratings yet
- 6-10 Las in Statistics and ProbabilityDocument14 pages6-10 Las in Statistics and ProbabilityDindo HiocoNo ratings yet
- Z Test FormulaDocument6 pagesZ Test FormulaE-m FunaNo ratings yet
- Measures of DispersionDocument11 pagesMeasures of DispersionKristen Imie Dungog LacapagNo ratings yet
- Descriptive StatisticsDocument5 pagesDescriptive StatisticsEmelson VertucioNo ratings yet
- Presentation 7 Chap6Document17 pagesPresentation 7 Chap6Kevin NyakundiNo ratings yet
- Normal DistributionDocument29 pagesNormal Distributionatul_rockstarNo ratings yet
- Position/e/z - Scores - 1: Above or Below Mean. Data SetDocument2 pagesPosition/e/z - Scores - 1: Above or Below Mean. Data SetJed HernandezNo ratings yet
- Week 5Document55 pagesWeek 5Yumi Ryu TatsuNo ratings yet
- Math11 SP Q3 M4 PDFDocument16 pagesMath11 SP Q3 M4 PDFJessa Banawan EdulanNo ratings yet
- Week 05Document23 pagesWeek 05Javeria EhteshamNo ratings yet
- Lesson 5 Z ScoreDocument32 pagesLesson 5 Z ScoreLala CkeeNo ratings yet
- A. The Standard Normal DistributionDocument9 pagesA. The Standard Normal DistributionAlexa LeeNo ratings yet
- Normal Distribution OverviewDocument3 pagesNormal Distribution OverviewDarshan MDNo ratings yet
- WWW Social Research Methods Net KB Statdesc PHPDocument87 pagesWWW Social Research Methods Net KB Statdesc PHPNexBengson100% (1)
- Some Basic Null Hypothesis TestsDocument19 pagesSome Basic Null Hypothesis TestsSudhir JainNo ratings yet
- Continuous Probability DistributionDocument14 pagesContinuous Probability DistributionMbuguz BeNel MuyaNo ratings yet
- STAT100 Fall19 Test 2 ANSWERS Practice Problems PDFDocument23 pagesSTAT100 Fall19 Test 2 ANSWERS Practice Problems PDFabutiNo ratings yet
- Normal DistributionDocument13 pagesNormal DistributionMarvin Dionel BathanNo ratings yet
- Standard Deviation - Wikipedia, The Free EncyclopediaDocument12 pagesStandard Deviation - Wikipedia, The Free EncyclopediaManoj BorahNo ratings yet
- Price List - 111123-2Document20 pagesPrice List - 111123-2akshayNo ratings yet
- StationaryDocument3 pagesStationaryakshayNo ratings yet
- Xerox S2 Board 2020Document5 pagesXerox S2 Board 2020akshayNo ratings yet
- Xerox S1 Board 2020Document6 pagesXerox S1 Board 2020akshayNo ratings yet
- Xerox History Board 2020Document5 pagesXerox History Board 2020akshayNo ratings yet
- Formula Sheet SOCI 1005Document6 pagesFormula Sheet SOCI 1005Katyayani RamnathNo ratings yet
- Chapter 6 - Utilization of Assessment Data Module 11Document6 pagesChapter 6 - Utilization of Assessment Data Module 11Jessa EscarealNo ratings yet
- Cheating Formula Statistics - Final ExamDocument4 pagesCheating Formula Statistics - Final ExamM.Ilham PratamaNo ratings yet
- Q3 - Summative Test2 - Statprob 2022 2023Document2 pagesQ3 - Summative Test2 - Statprob 2022 2023Christian Lloyd ReandinoNo ratings yet
- Topics: Descriptive Statistics and Probability: Name of Company Measure XDocument4 pagesTopics: Descriptive Statistics and Probability: Name of Company Measure XSimarjeet SinghNo ratings yet
- HW 03 220Document5 pagesHW 03 220zhang JayantNo ratings yet
- Statistics For Class 10 PDFDocument8 pagesStatistics For Class 10 PDFAjay SinghNo ratings yet
- Learning Competencies:: at The End of The Chapter, The Learner Should Be Able ToDocument29 pagesLearning Competencies:: at The End of The Chapter, The Learner Should Be Able ToJhanna Miegh RentilloNo ratings yet
- Mean Median and Skew Correcting A Textbook RuleDocument14 pagesMean Median and Skew Correcting A Textbook RuleSatya Swaroop SwainNo ratings yet
- Dpna Tik s1 Genap 2021-2022Document4 pagesDpna Tik s1 Genap 2021-2022gusvani aulia putriNo ratings yet
- LESSON 4 Normal DistributionDocument60 pagesLESSON 4 Normal DistributionCarbon CopyNo ratings yet
- Central TendencyDocument38 pagesCentral TendencyPronomy ProchetaNo ratings yet
- COT No. 4sampling Distribution With ReplacementDocument15 pagesCOT No. 4sampling Distribution With Replacementedward louie serranoNo ratings yet
- Quiz Test of First and Third ChapterDocument2 pagesQuiz Test of First and Third ChapterHaFizSNKNo ratings yet
- 17C - PowerPoint - Standard DeviationDocument9 pages17C - PowerPoint - Standard DeviationPeter LeeNo ratings yet
- North South University: Assignment Using IBM SPS' Course Code: Bus 511.3 Course Title: Business Statistics Spring 2021Document18 pagesNorth South University: Assignment Using IBM SPS' Course Code: Bus 511.3 Course Title: Business Statistics Spring 2021Rashìd RanaNo ratings yet
- SP Las 15Document12 pagesSP Las 15Kyle Andre CabaneroNo ratings yet
- Data and SummarizationDocument57 pagesData and SummarizationAKSHAY NANGIANo ratings yet
- 18BCE10291 - Outliers AssignmentDocument10 pages18BCE10291 - Outliers AssignmentvikramNo ratings yet
- 2.1 Measures of Central TendencyDocument54 pages2.1 Measures of Central TendencyWeb Best WabiiNo ratings yet
- Problem Set 10 (With Instructions) : Regression AnalysisDocument6 pagesProblem Set 10 (With Instructions) : Regression AnalysisLily TranNo ratings yet
- Rocinante 36 Marengo 32 Mileage (KM/LTR) Top Speed (KM/HR) Mileage (KM/LTR) Top Speed (KM/HR)Document3 pagesRocinante 36 Marengo 32 Mileage (KM/LTR) Top Speed (KM/HR) Mileage (KM/LTR) Top Speed (KM/HR)prakhar jainNo ratings yet
- Normal DistributionDocument1 pageNormal DistributionKRISHNA PRASATH SNo ratings yet
- Information Fusion: Ronald R. Yager, Naif AlajlanDocument9 pagesInformation Fusion: Ronald R. Yager, Naif AlajlanSatyendra NarayanNo ratings yet
- Measure of Central Tendency - QuestionsDocument14 pagesMeasure of Central Tendency - QuestionsMohd HannanNo ratings yet
- CH 14 Notes & Ex 14.1 SolutionDocument8 pagesCH 14 Notes & Ex 14.1 SolutionkokilaNo ratings yet
- Varma GarchDocument55 pagesVarma GarchJosue KouakouNo ratings yet
- Measures of Central Tendency of GROUPED DataDocument7 pagesMeasures of Central Tendency of GROUPED DataLea Marie PatindolNo ratings yet