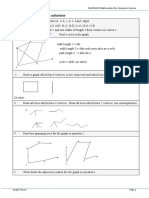
You might also like
- Bms College of Engineering, Bangalore-19 Department of MathematicsDocument13 pagesBms College of Engineering, Bangalore-19 Department of MathematicsDarshan .BNo ratings yet
- How Do We Resolve Such Issue?Document28 pagesHow Do We Resolve Such Issue?Gi ChoiNo ratings yet
- Graph AlgorithmsDocument82 pagesGraph AlgorithmsDharmendra KumarNo ratings yet
- DS Unit 5 GraphsDocument24 pagesDS Unit 5 GraphsParameswara RaoNo ratings yet
- Graph TheoryDocument81 pagesGraph TheoryKavita Rahane100% (1)
- GraphsDocument12 pagesGraphsMesNo ratings yet
- Unit-4 Graph Theory (Euler, Hamiltonian, Dual, Chromatic Number, Polynomial, Matrices)Document52 pagesUnit-4 Graph Theory (Euler, Hamiltonian, Dual, Chromatic Number, Polynomial, Matrices)Tejas HNo ratings yet
- Graphs: Nitin UpadhyayDocument29 pagesGraphs: Nitin UpadhyaypurijatinNo ratings yet
- DSLec 13Document28 pagesDSLec 13Hamayon WazirNo ratings yet
- 6.1. Introduction To GraphsDocument28 pages6.1. Introduction To GraphsKiran KumarNo ratings yet
- Introduction To Graph Theory: Handbook of Graph Theory F OR Fresher' SDocument35 pagesIntroduction To Graph Theory: Handbook of Graph Theory F OR Fresher' SHarsha Vardhan GorantlaNo ratings yet
- Lecture - 04 - Minimum Spanning Tree (Prim and Krushkal) 2Document154 pagesLecture - 04 - Minimum Spanning Tree (Prim and Krushkal) 2GOLDEN BIRDNo ratings yet
- V, V, ) Called Vertices: Points or Nodes) and Other Set E (EDocument15 pagesV, V, ) Called Vertices: Points or Nodes) and Other Set E (EErArpitaGuptaNo ratings yet
- Lecture 10 CSC 221 Graphs 28122022 013443pm 15122023 110227amDocument29 pagesLecture 10 CSC 221 Graphs 28122022 013443pm 15122023 110227amhammadalamgir778No ratings yet
- Graph TheoryDocument42 pagesGraph Theorykanchisudhanwa7No ratings yet
- 06 GraphsDocument260 pages06 GraphssohaibchNo ratings yet
- Cha5 Graph TheoryDocument10 pagesCha5 Graph Theoryham.karimNo ratings yet
- Discrete Maths 191 219Document29 pagesDiscrete Maths 191 219Bamdeb DeyNo ratings yet
- Priya ProjectDocument42 pagesPriya Projectaravind kumarNo ratings yet
- 10 GraphsDocument69 pages10 Graphssanskar khandelwalNo ratings yet
- Specialist12 2ed Ch12Document47 pagesSpecialist12 2ed Ch12ZeinabNo ratings yet
- Lecture 5: Basics of Graph Theory: 1 DefinitionsDocument11 pagesLecture 5: Basics of Graph Theory: 1 DefinitionsAakankshaChhaviNo ratings yet
- DM GraphsDocument6 pagesDM Graphsanon-552375No ratings yet
- CSCE 3110 Data Structures & Algorithm Analysis: Rada Mihalcea Graphs (I) Reading: Chap.9, WeissDocument34 pagesCSCE 3110 Data Structures & Algorithm Analysis: Rada Mihalcea Graphs (I) Reading: Chap.9, WeissArnold AravindNo ratings yet
- 13 GraphsDocument89 pages13 GraphsAliza SaherNo ratings yet
- Topic 5 - Graph and Trees TheoryDocument92 pagesTopic 5 - Graph and Trees TheoryhawarieslabNo ratings yet
- Lect 8Document7 pagesLect 8api-3705606No ratings yet
- Graph Theory: Ayele BDocument67 pagesGraph Theory: Ayele BAbiyot NeguNo ratings yet
- (Graph Theory) : Discrete Structure Tribhuvan University Kathmandu, NepalDocument44 pages(Graph Theory) : Discrete Structure Tribhuvan University Kathmandu, NepalSuman Thapa MagarNo ratings yet
- 22 - Elementary Graph AlgorithmsDocument55 pages22 - Elementary Graph Algorithmstwzfpdwg6kNo ratings yet
- Basic Graph Terminologies: May 30, 2014 21:27 WSPC/Book Trim Size For 9in X 6in BgtbookDocument24 pagesBasic Graph Terminologies: May 30, 2014 21:27 WSPC/Book Trim Size For 9in X 6in BgtbookAshfaqul Islam TonmoyNo ratings yet
- GraphsDocument156 pagesGraphsVishal GaurNo ratings yet
- A434234317 16857 30 2018 GraphsDocument51 pagesA434234317 16857 30 2018 GraphsSai TejaNo ratings yet
- Graph: Dr. Inayat-ur-Rehman COMSATS Institute of Information Technology, IslamabadDocument39 pagesGraph: Dr. Inayat-ur-Rehman COMSATS Institute of Information Technology, Islamabadmalik husnainNo ratings yet
- GraphsDocument19 pagesGraphsVashuNo ratings yet
- Graph TheoryDocument41 pagesGraph TheoryIMDAD HUSSAIN MAMUDNo ratings yet
- Graph TheoryDocument32 pagesGraph TheoryRvprasadNo ratings yet
- On The Net Distance Matrix of A Signed Block Graph: Research ArticleDocument15 pagesOn The Net Distance Matrix of A Signed Block Graph: Research ArticlevigneshNo ratings yet
- Math 1 Module 11Document10 pagesMath 1 Module 11Ara MaeNo ratings yet
- 11 - GraphDocument81 pages11 - GraphHard FuckerNo ratings yet
- Networks: DefinitionsDocument131 pagesNetworks: DefinitionsJosé Manuel Slater CarrascoNo ratings yet
- DS Module-5 NotesDocument30 pagesDS Module-5 Notesanikaitsarkar.20ecNo ratings yet
- MATH1179 Graph Theory Book SolutionDocument4 pagesMATH1179 Graph Theory Book SolutionOviyanNo ratings yet
- Hypergraphs: First PropertiesDocument21 pagesHypergraphs: First PropertiesAlamelu LakshmananNo ratings yet
- Data Structures: R. K. GhoshDocument138 pagesData Structures: R. K. GhoshRatan K GhoshNo ratings yet
- Unit: III: Graph TheoryDocument29 pagesUnit: III: Graph TheoryUnknow UserNo ratings yet
- Graph Theory PRDocument26 pagesGraph Theory PRkaranNo ratings yet
- Lecture 1Document50 pagesLecture 1Kashif KashifNo ratings yet
- Chapter6 GraphsDocument174 pagesChapter6 GraphsIting HsiehNo ratings yet
- Graph Bfs 1Document37 pagesGraph Bfs 1api-3825915No ratings yet
- 6.1. Intro. To GraphsDocument31 pages6.1. Intro. To GraphsggttffNo ratings yet
- UNIT 3 GRAPHS Class NotesDocument24 pagesUNIT 3 GRAPHS Class NotesSUDHA SNo ratings yet
- Struktur Data: Graph: Program Studi S-1 Informatika, FMIPA UnsyiahDocument26 pagesStruktur Data: Graph: Program Studi S-1 Informatika, FMIPA UnsyiahkudbalapNo ratings yet
- Week 11 - GraphsDocument11 pagesWeek 11 - GraphsEmmanuel GuillermoNo ratings yet
- Unit 5Document73 pagesUnit 5UbedSayyedNo ratings yet
- Graph PDFDocument22 pagesGraph PDFarcheNo ratings yet
- Lec 3Document10 pagesLec 3xigon53558No ratings yet
- ComputationalMathematics - Chapter 3Document19 pagesComputationalMathematics - Chapter 3Megha SharmaNo ratings yet
- Tables of the Function w (z)- e-z2 ? ex2 dx: Mathematical Tables Series, Vol. 27From EverandTables of the Function w (z)- e-z2 ? ex2 dx: Mathematical Tables Series, Vol. 27No ratings yet
- Graphs4 QADocument6 pagesGraphs4 QAAbdulnafiu AhmadNo ratings yet
- 3 5 3 C Q 4 F 3 4 2 L 1 10Document3 pages3 5 3 C Q 4 F 3 4 2 L 1 10Koustubh GuptaNo ratings yet
- Cayley TreeDocument10 pagesCayley TreeDya YadiailaikaNo ratings yet
- SpanTreeDocument32 pagesSpanTreeTsega TeklewoldNo ratings yet
- SECTION 10.8 Graph Coloring: Abc, C EDocument3 pagesSECTION 10.8 Graph Coloring: Abc, C EMuhammad ZainNo ratings yet
- Discrete Math Graphs and Tree PDFDocument61 pagesDiscrete Math Graphs and Tree PDFjungjeyoo300No ratings yet
- Comparing Prim's With Kruskal's AlgoDocument12 pagesComparing Prim's With Kruskal's Algojenny luterioNo ratings yet
- Graph ProblemsDocument17 pagesGraph Problemsmininis01No ratings yet
- Kruskal's AlgorithmDocument4 pagesKruskal's Algorithmadi2343shNo ratings yet
- 19BCS2626 Crab GraphDocument3 pages19BCS2626 Crab GraphWhite WolfNo ratings yet
- Chapter 11 Practice TestDocument8 pagesChapter 11 Practice TestDoctor ViddaNo ratings yet
- Lecture Notes MTH401 Graphs (Part-1)Document35 pagesLecture Notes MTH401 Graphs (Part-1)premranjanv784No ratings yet
- 08 Networks + Short Route + Spanning (20211203)Document29 pages08 Networks + Short Route + Spanning (20211203)Lakshmi Harshitha mNo ratings yet
- Worksheet On Eulers GraphDocument2 pagesWorksheet On Eulers GraphMarlon RendonNo ratings yet
- Kosaraju Algorithm For Strongly Connected ComponentsDocument12 pagesKosaraju Algorithm For Strongly Connected Componentsగోకుల్ వంశీ శ్రీనివాస్No ratings yet
- Minimum Cost Spanning Tree Unit-3Document20 pagesMinimum Cost Spanning Tree Unit-3Phani KumarNo ratings yet
- Shamaas Munir Assignment No 1 MTH 620Document8 pagesShamaas Munir Assignment No 1 MTH 620mc200200839No ratings yet
- Solution: Permeability Vs % ThicknessDocument2 pagesSolution: Permeability Vs % ThicknessahmedNo ratings yet
- 11-Hamiltonian Using BACKTRACKINGDocument5 pages11-Hamiltonian Using BACKTRACKINGNandeesh PuriNo ratings yet
- CHAINAGE:0.00KMP-13.00KMP Construction of Saiha-Lungbun-Tluangram-Haka Road (Lungbun To R.Kolodyne: Mizoram Area, Length 13.00Kms) Annexure-IiDocument2 pagesCHAINAGE:0.00KMP-13.00KMP Construction of Saiha-Lungbun-Tluangram-Haka Road (Lungbun To R.Kolodyne: Mizoram Area, Length 13.00Kms) Annexure-IiMuani HmarNo ratings yet
- DM PresentationDocument9 pagesDM PresentationameyaNo ratings yet
- Beautiful Conjectures in Graph TheoryDocument20 pagesBeautiful Conjectures in Graph TheoryKepler Kebler KlebisonNo ratings yet
- (CRM Series 16) Roman Glebov, Daniel Král’, Jan Volec (Auth.), Jaroslav Nešetřil, Marco Pellegrini (Eds.) - The Seventh European Conference on Combinatorics, Graph Theory and Applications_ EuroComb 20Document612 pages(CRM Series 16) Roman Glebov, Daniel Král’, Jan Volec (Auth.), Jaroslav Nešetřil, Marco Pellegrini (Eds.) - The Seventh European Conference on Combinatorics, Graph Theory and Applications_ EuroComb 20CésarAugustoNo ratings yet
- University of Twente: Faculty of Mathematical SciencesDocument26 pagesUniversity of Twente: Faculty of Mathematical SciencesMarcel ManriqueNo ratings yet
- Data Structures: Unit III - Part 4 Bca, NGMCDocument10 pagesData Structures: Unit III - Part 4 Bca, NGMCSanthosh kumar KNo ratings yet
- QuestionsDocument1 pageQuestionsANNo ratings yet
- BFS and DFSDocument9 pagesBFS and DFSLeela PallavaNo ratings yet
- Discrete Mathematics: Alexander Bukharovich New York UniversityDocument18 pagesDiscrete Mathematics: Alexander Bukharovich New York UniversityPrathamesh JagtapNo ratings yet
- HVAC Zoning and Pressurization DiagramsDocument1 pageHVAC Zoning and Pressurization DiagramsWilliam GrecoNo ratings yet
- Advance Graph TheoryDocument21 pagesAdvance Graph TheoryTanmoy DattaNo ratings yet