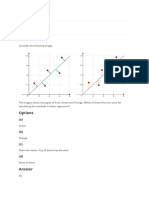
You might also like
- 2019 - Introduction To Data Analytics Using RDocument5 pages2019 - Introduction To Data Analytics Using RYeickson Mendoza MartinezNo ratings yet
- Machine Learning Multiple Choice QuestionsDocument20 pagesMachine Learning Multiple Choice QuestionsSatyanarayan Gupta100% (1)
- Statistics and Probability Problems With SolutionsDocument10 pagesStatistics and Probability Problems With SolutionsJustine Marowe AustriaNo ratings yet
- HUAWEI Final Written Exam 3333Document13 pagesHUAWEI Final Written Exam 3333Jonafe PiamonteNo ratings yet
- Using Econometrics A Practical Guide 6th Edition Studenmund Solutions ManualDocument11 pagesUsing Econometrics A Practical Guide 6th Edition Studenmund Solutions ManualDebraChambersrimbo100% (21)
- Huawei Final Written Exam 2.2 AttemptsDocument19 pagesHuawei Final Written Exam 2.2 AttemptsJonafe PiamonteNo ratings yet
- Fundamental Statistical Inference: A Computational ApproachFrom EverandFundamental Statistical Inference: A Computational ApproachNo ratings yet
- Huawei Final Written ExamDocument18 pagesHuawei Final Written ExamJonafe Piamonte50% (2)
- Final Exam Update HuaweiDocument13 pagesFinal Exam Update HuaweiJonafe PiamonteNo ratings yet
- Ell409 AqDocument8 pagesEll409 Aqlovlesh royNo ratings yet
- ML MCQ 1Document5 pagesML MCQ 1Mks KhanNo ratings yet
- Ell784 17 AqDocument8 pagesEll784 17 Aqlovlesh royNo ratings yet
- DIT865 2018 Mar SolutionDocument9 pagesDIT865 2018 Mar SolutionEducation VietCoNo ratings yet
- Final Written Exam Edit 3.3Document13 pagesFinal Written Exam Edit 3.3Jonafe PiamonteNo ratings yet
- Data Mining Sample Midterm Questions (Last Modified 2/17/19)Document4 pagesData Mining Sample Midterm Questions (Last Modified 2/17/19)rekhaNo ratings yet
- End-Semseter Test 2017Document11 pagesEnd-Semseter Test 2017alia patilNo ratings yet
- BES - R LabDocument5 pagesBES - R LabViem AnhNo ratings yet
- Practice Final CS61cDocument19 pagesPractice Final CS61cEdward Yixin GuoNo ratings yet
- MDS 503 2nd Exam - R - Stat - OBDocument3 pagesMDS 503 2nd Exam - R - Stat - OBTesta MestaNo ratings yet
- 1 Econreview-QuestionsDocument26 pages1 Econreview-QuestionsgleniaNo ratings yet
- 1 Econreview-QuestionsDocument26 pages1 Econreview-QuestionsgleniaNo ratings yet
- 1 Econreview-QuestionsDocument26 pages1 Econreview-QuestionsgleniaNo ratings yet
- 18CSO106T Data Analysis Using Open Source Tool: Question BankDocument26 pages18CSO106T Data Analysis Using Open Source Tool: Question BankShivaditya singhNo ratings yet
- Introduction To Econometrics, TutorialDocument22 pagesIntroduction To Econometrics, Tutorialagonza70No ratings yet
- Confidence Intervals For The Kappa Statistic: 1 DescriptionDocument8 pagesConfidence Intervals For The Kappa Statistic: 1 DescriptionChristopher PáduaNo ratings yet
- Classification of Ford Motor Data: Joerg D. WichardDocument4 pagesClassification of Ford Motor Data: Joerg D. WichardThái SơnNo ratings yet
- HW1 (Practice Problem Set) - 1Document6 pagesHW1 (Practice Problem Set) - 1Beta WaysNo ratings yet
- SAS Project 2 (31.3 Pts. + 4.2 Bonus) Due Dec. 8: 1. Confidence Intervals/Hypothesis TestsDocument21 pagesSAS Project 2 (31.3 Pts. + 4.2 Bonus) Due Dec. 8: 1. Confidence Intervals/Hypothesis TestsAshwani PasrichaNo ratings yet
- UntitledDocument5 pagesUntitled21P410 - VARUN MNo ratings yet
- CSC 5825 Intro. To Machine Learning and Applications Midterm ExamDocument13 pagesCSC 5825 Intro. To Machine Learning and Applications Midterm ExamranaNo ratings yet
- 30 Questions To Test Your Understanding of Logistic RegressionDocument13 pages30 Questions To Test Your Understanding of Logistic RegressionShishir ZamanNo ratings yet
- Quiz 9Document3 pagesQuiz 9Avicii23 AviciiNo ratings yet
- COMP1942 Question PaperDocument5 pagesCOMP1942 Question PaperpakaMuzikiNo ratings yet
- Assignment 6 (Sol.) : Reinforcement LearningDocument4 pagesAssignment 6 (Sol.) : Reinforcement Learningsachin bhadangNo ratings yet
- Braun Bootstrap2012 PDFDocument63 pagesBraun Bootstrap2012 PDFJoe OgleNo ratings yet
- AI 3000 / CS5500: Reinforcement Learning Exam 1: InstructionsDocument4 pagesAI 3000 / CS5500: Reinforcement Learning Exam 1: InstructionsAbdul TaufeeqNo ratings yet
- Assignment 4Document3 pagesAssignment 4Uday GulghaneNo ratings yet
- Problem 1: Markov Reward ProcessDocument3 pagesProblem 1: Markov Reward ProcessAbdul TaufeeqNo ratings yet
- Fa11 FinalDocument21 pagesFa11 FinalSri PatNo ratings yet
- Week 6Document11 pagesWeek 6sachinNo ratings yet
- Tut1 Parta STAT340Document1 pageTut1 Parta STAT340Sungsoo KimNo ratings yet
- Assignment 2: Introduction To Machine Learning Prof. B. RavindranDocument3 pagesAssignment 2: Introduction To Machine Learning Prof. B. RavindranVijayramasamyNo ratings yet
- EC221 답 지운 것Document99 pagesEC221 답 지운 것이찬호No ratings yet
- Hatdog 1.2Document18 pagesHatdog 1.2Jonafe PiamonteNo ratings yet
- Mids 20 ADocument8 pagesMids 20 AEman AsemNo ratings yet
- Bootstrap UpDocument5 pagesBootstrap UpVijay BokadeNo ratings yet
- DS 432 Assignment I 2020Document7 pagesDS 432 Assignment I 2020sristi agrawalNo ratings yet
- CSL332 MajorDocument4 pagesCSL332 MajorAmandeep SinghNo ratings yet
- 1 Analytical Part (3 Percent Grade) : + + + 1 N I: y +1 I 1 N I: y 1 IDocument5 pages1 Analytical Part (3 Percent Grade) : + + + 1 N I: y +1 I 1 N I: y 1 IMuhammad Hur RizviNo ratings yet
- CS373 Homework 1: 1 Part I: Basic Probability and StatisticsDocument5 pagesCS373 Homework 1: 1 Part I: Basic Probability and StatisticssanjayNo ratings yet
- Assignment 3 (Sol.) : Introduction To Machine Learning Prof. B. RavindranDocument8 pagesAssignment 3 (Sol.) : Introduction To Machine Learning Prof. B. RavindranThrilling MeherabNo ratings yet
- Assignment 4 (Sol.) : Introduction To Machine Learning Prof. B. RavindranDocument4 pagesAssignment 4 (Sol.) : Introduction To Machine Learning Prof. B. RavindranByron Xavier Lima CedilloNo ratings yet
- Activity 7Document5 pagesActivity 7Sam Sat PatNo ratings yet
- Gujarat Technological UniversityDocument2 pagesGujarat Technological UniversityShiv PatelNo ratings yet
- A Short Introduction To BoostingDocument14 pagesA Short Introduction To BoostingSeven NguyenNo ratings yet
- A Practical Guide To Support Vector Classi Cation - Chih-Wei Hsu, Chih-Chung Chang and Chih-Jen LinDocument12 pagesA Practical Guide To Support Vector Classi Cation - Chih-Wei Hsu, Chih-Chung Chang and Chih-Jen LinVítor MangaraviteNo ratings yet
- Assignment 3: 1. Consider A Binary Classification Problem With The Following Set of Attributes andDocument2 pagesAssignment 3: 1. Consider A Binary Classification Problem With The Following Set of Attributes andSaptarick MishraNo ratings yet
- F2019a ExamDocument9 pagesF2019a ExamInfected MonkeyNo ratings yet
- Experimental Design - Within-Subjects DesignDocument27 pagesExperimental Design - Within-Subjects Designfauzan.abdullahNo ratings yet
- CASE - Gulf Real Estate Properties: Subject: Quantitative Method - IDocument12 pagesCASE - Gulf Real Estate Properties: Subject: Quantitative Method - IIsha KhakharNo ratings yet
- Uncertainty in KBSDocument5 pagesUncertainty in KBSSuada Bőw WéěžýNo ratings yet
- Mock Paper 2 StatisticsDocument5 pagesMock Paper 2 StatisticsAHMED AlpNo ratings yet
- Lecture 10Document14 pagesLecture 10Rasim Ozan SomaliNo ratings yet
- Statistic Practice QuestionDocument28 pagesStatistic Practice QuestionSaqib AliNo ratings yet
- Hydrology PaperDocument26 pagesHydrology Papersaiba0% (1)
- The Logic of ANOVADocument4 pagesThe Logic of ANOVAAlp Eren AKYUZNo ratings yet
- Lilliefors Van Soest's Test of NormalityDocument10 pagesLilliefors Van Soest's Test of Normalitydimitri_deliyianniNo ratings yet
- Miller Toy Company Manufactures A Plastic Swimming PoolDocument10 pagesMiller Toy Company Manufactures A Plastic Swimming Poollaale dijaanNo ratings yet
- Descriptive and Inferential StatisticalDocument4 pagesDescriptive and Inferential StatisticalMujianiNo ratings yet
- Chapter 8 NotesDocument6 pagesChapter 8 NotesMary Zurlo Blancha100% (1)
- Expectations - NotesDocument3 pagesExpectations - NotesPranav SuryaNo ratings yet
- 11852-23500-1-Sm - Regresi Logistik Biner & c.45 (Adk), KlasifikasiDocument11 pages11852-23500-1-Sm - Regresi Logistik Biner & c.45 (Adk), KlasifikasivitaNo ratings yet
- MTH 161: Introduction To Statistics: Dr. Mumtaz AhmedDocument24 pagesMTH 161: Introduction To Statistics: Dr. Mumtaz AhmedKulafu AqNo ratings yet
- Assignment On Chapter-10 (Maths Solved) Business Statistics Course Code - ALD 2104Document32 pagesAssignment On Chapter-10 (Maths Solved) Business Statistics Course Code - ALD 2104Sakib Ul-abrarNo ratings yet
- The Normal Binomial and Poisson DistributionsDocument25 pagesThe Normal Binomial and Poisson DistributionsDeepak RanaNo ratings yet
- NPCR and UACI Randomness Tests For Image EncryptionDocument8 pagesNPCR and UACI Randomness Tests For Image EncryptionCyberJournals MultidisciplinaryNo ratings yet
- Multivariate and Multilevel Data Analysis Using SPSS, Amos, Smartpls and MplusDocument8 pagesMultivariate and Multilevel Data Analysis Using SPSS, Amos, Smartpls and MplusMuhammad Asad AliNo ratings yet
- Biostatistics: Eskindir Loha, PHD School of Public and Environmental Health Hawassa UniversityDocument18 pagesBiostatistics: Eskindir Loha, PHD School of Public and Environmental Health Hawassa Universityeshet chafNo ratings yet
- The Hopfield Model - Emin Orhan - 2014 PDFDocument11 pagesThe Hopfield Model - Emin Orhan - 2014 PDFJon Arnold GreyNo ratings yet
- UNIT2 Probabilty QuestionsDocument4 pagesUNIT2 Probabilty QuestionsDisha GoelNo ratings yet
- Ejercicios PinskyDocument66 pagesEjercicios PinskyA KarenMartz HerdezNo ratings yet
- Bnad 277 Lab 7 WebDocument3 pagesBnad 277 Lab 7 Webapi-530715476No ratings yet
- Analyses For Multi-Site Experiments Using Augmented Designs: Hij HijDocument2 pagesAnalyses For Multi-Site Experiments Using Augmented Designs: Hij HijMustakiMipa RegresiNo ratings yet
- Final Review Worksheet-STAT 362-Final ReviewDocument24 pagesFinal Review Worksheet-STAT 362-Final ReviewKasa BekeleNo ratings yet
- Learn Machine Learning: ReferenceDocument9 pagesLearn Machine Learning: ReferenceUzùmákî Nägäto TenshøûNo ratings yet
- Module 5 Kendall's TauDocument10 pagesModule 5 Kendall's TauAce ClarkNo ratings yet
- 1-Chemical Analysis - Quantitation - SDocument39 pages1-Chemical Analysis - Quantitation - SnofacejackNo ratings yet