You might also like
- Machine Learning AdvancedDocument12 pagesMachine Learning Advanceddhruvit100% (2)
- Neural Networks for Beginners: Introduction to Machine Learning and Deep LearningFrom EverandNeural Networks for Beginners: Introduction to Machine Learning and Deep LearningNo ratings yet
- Deep FakeDocument36 pagesDeep FakeSafa DemirhanNo ratings yet
- Big Data MCQDocument4 pagesBig Data MCQs100% (1)
- Generating and Analyzing Chatbot Responses Using Natural Language ProcessingInternational Journal of Advanced Computer Science and ApplicationsDocument9 pagesGenerating and Analyzing Chatbot Responses Using Natural Language ProcessingInternational Journal of Advanced Computer Science and ApplicationsFrank AyalaNo ratings yet
- Detection of Parkinson's Disease Using Machine LearningDocument91 pagesDetection of Parkinson's Disease Using Machine LearningSyed Ameen75% (4)
- Paper 1-Bidirectional LSTM With Attention Mechanism and Convolutional LayerDocument51 pagesPaper 1-Bidirectional LSTM With Attention Mechanism and Convolutional LayerPradeep PatwaNo ratings yet
- Speech RecogDocument5 pagesSpeech RecogzxvcbvbNo ratings yet
- Electronics 11 01409Document9 pagesElectronics 11 01409l AlOtaibiNo ratings yet
- Speech Communication: Qirong Mao, Guopeng Xu, Wentao Xue, Jianping Gou, Yongzhao ZhanDocument10 pagesSpeech Communication: Qirong Mao, Guopeng Xu, Wentao Xue, Jianping Gou, Yongzhao ZhanAbdallah GrimaNo ratings yet
- Mustaqeem 2020Document15 pagesMustaqeem 2020l AlOtaibiNo ratings yet
- Irjet V7i6804Document7 pagesIrjet V7i6804Trung Tín NguyễnNo ratings yet
- Reading Scene Text in Deep Convolutional Sequences: Pan He, Weilin Huang, Yu Qiao, Chen Change Loy, and Xiaoou TangDocument8 pagesReading Scene Text in Deep Convolutional Sequences: Pan He, Weilin Huang, Yu Qiao, Chen Change Loy, and Xiaoou Tangconst_No ratings yet
- 10 1109@access 2019 2936124Document19 pages10 1109@access 2019 2936124gtaekbmkimaeonrgybNo ratings yet
- Bangla Speech Emotion Recognition and Cross-Lingual Study Using Deep CNN and BLSTM NetworksDocument15 pagesBangla Speech Emotion Recognition and Cross-Lingual Study Using Deep CNN and BLSTM NetworksJose AngelNo ratings yet
- Robust Representation and Recognition of Facial-IEEE-2015Document13 pagesRobust Representation and Recognition of Facial-IEEE-2015Ravi Shankar SharmaNo ratings yet
- Deep Neural Networks For Emotion Recognition Combining Audio and TranscriptsDocument5 pagesDeep Neural Networks For Emotion Recognition Combining Audio and TranscriptsJose AngelNo ratings yet
- Knowledge As A Teacher: Knowledge-Guided Structural Attention NetworksDocument11 pagesKnowledge As A Teacher: Knowledge-Guided Structural Attention Networksgassun2999No ratings yet
- Review of Deep Learning Algorithms and ArchitecturDocument29 pagesReview of Deep Learning Algorithms and ArchitecturShuvo H AhmedNo ratings yet
- Human Emotion Detection With Speech Recognition Using Mel-Frequency Cepstral Coefficient and CNN - NewDocument2 pagesHuman Emotion Detection With Speech Recognition Using Mel-Frequency Cepstral Coefficient and CNN - NewakshatNo ratings yet
- Recognition of Formatted Text Using Machine Learning TechniqueDocument4 pagesRecognition of Formatted Text Using Machine Learning TechniqueYungNamNo ratings yet
- Deep Learning in Natural Language Processing A State-of-the-Art SurveyDocument6 pagesDeep Learning in Natural Language Processing A State-of-the-Art SurveySmriti Medhi MoralNo ratings yet
- Recognition and Detection of Language On Inscriptions: Dr. C Parthasarathy, R.Sarvanan, M Sathish, U.Sai Sri TejaDocument3 pagesRecognition and Detection of Language On Inscriptions: Dr. C Parthasarathy, R.Sarvanan, M Sathish, U.Sai Sri TejaerpublicationNo ratings yet
- Research PaperDocument5 pagesResearch PaperakshatNo ratings yet
- Unsupervised Personalization of An Emotion Recognition System The Unique Properties of The Externalization of Valence in SpeechDocument14 pagesUnsupervised Personalization of An Emotion Recognition System The Unique Properties of The Externalization of Valence in SpeechMylavarapu SriprithamNo ratings yet
- Speech Emotion Recognition Using Deep Convolutional Neural Network and Discriminant Temporal Pyramid MatchingDocument15 pagesSpeech Emotion Recognition Using Deep Convolutional Neural Network and Discriminant Temporal Pyramid MatchingGalaa GantumurNo ratings yet
- 10 - Recurrent Neural Network Based Speech EmotionDocument13 pages10 - Recurrent Neural Network Based Speech EmotionAlex HAlesNo ratings yet
- ETHARIUmDocument10 pagesETHARIUmTneerajNo ratings yet
- Speech Emotion RecoginitionDocument5 pagesSpeech Emotion RecoginitionPratham MURKUTENo ratings yet
- A Survey On Deep Learning-Based Fine-Grained Object Classification and Semantic SegmentationDocument17 pagesA Survey On Deep Learning-Based Fine-Grained Object Classification and Semantic SegmentationAnonymous kIAESXSkNo ratings yet
- Multi-Task Convolutional Neural Network For Pose-Invariant Face RecognitionDocument12 pagesMulti-Task Convolutional Neural Network For Pose-Invariant Face RecognitionBOUMARAF IbtissamNo ratings yet
- Shirani MehrH PDFDocument8 pagesShirani MehrH PDFchirag801No ratings yet
- Pattern Recognition Letters: Neha Jain, Shishir Kumar, Amit Kumar, Pourya Shamsolmoali, Masoumeh ZareapoorDocument6 pagesPattern Recognition Letters: Neha Jain, Shishir Kumar, Amit Kumar, Pourya Shamsolmoali, Masoumeh ZareapoorJOTHIMANI SNo ratings yet
- AC LSTMNeuralNetworkforTextClassificationDocument10 pagesAC LSTMNeuralNetworkforTextClassificationThiago Souza SantosNo ratings yet
- Speech Emotion Recognition Using Capsule Networks: Conference PaperDocument6 pagesSpeech Emotion Recognition Using Capsule Networks: Conference PaperShah JamalNo ratings yet
- Speech Emotion Recognition: Methods and Cases Study: January 2018Document9 pagesSpeech Emotion Recognition: Methods and Cases Study: January 2018nehaNo ratings yet
- Speech Emotion Recognition Using Machine Learning - A Systematic ReviewDocument25 pagesSpeech Emotion Recognition Using Machine Learning - A Systematic ReviewSustainable SushiNo ratings yet
- Corresponding AuthorDocument6 pagesCorresponding AuthorArs Arifur RahmanNo ratings yet
- SpeechDocument12 pagesSpeechPratham MURKUTENo ratings yet
- Winter Semester 2021-22 CSE4020-Machine Learning Digital Assignment-1Document20 pagesWinter Semester 2021-22 CSE4020-Machine Learning Digital Assignment-1STYXNo ratings yet
- 10 1016@j Specom 2019 10 004 PDFDocument14 pages10 1016@j Specom 2019 10 004 PDFbrezzy miraNo ratings yet
- A Comprehensive Review of Speech Emotion Recognition SystemsDocument20 pagesA Comprehensive Review of Speech Emotion Recognition SystemsR B SHARANNo ratings yet
- Comparative Analysis of Neural Networks For Speech Emotion RecognitionDocument5 pagesComparative Analysis of Neural Networks For Speech Emotion RecognitionhemantaNo ratings yet
- Multi ModalDocument7 pagesMulti ModalRaja KumarNo ratings yet
- 1505 06427 PDFDocument5 pages1505 06427 PDFMuhammet Ali KökerNo ratings yet
- Deep Learning-Based Parkinson's Disease Classification Using Vocal Feature SetsDocument12 pagesDeep Learning-Based Parkinson's Disease Classification Using Vocal Feature SetsVallabh JNo ratings yet
- Neural Architectures For Named Entity RecognitionDocument11 pagesNeural Architectures For Named Entity RecognitionAmrit AcharyaNo ratings yet
- Abbas I 2011Document16 pagesAbbas I 2011Ess Kay EssNo ratings yet
- Speech Emotion Recognition Using Deep Learning Techniques: A ReviewDocument19 pagesSpeech Emotion Recognition Using Deep Learning Techniques: A ReviewAkhila RNo ratings yet
- CH 5Document16 pagesCH 521dce106No ratings yet
- Comparison Between SVM Other Classifiers For Ser IJERTV2IS1457Document6 pagesComparison Between SVM Other Classifiers For Ser IJERTV2IS1457Onur OzdemirNo ratings yet
- Haramaya University Computer Science StudentDocument15 pagesHaramaya University Computer Science StudentEYUEL TADESSENo ratings yet
- 8 - 1 - NICS 2018 - Vietnamese Keyword Extraction Using Hybrid Deep Learning Methods - Bui Thanh HungDocument6 pages8 - 1 - NICS 2018 - Vietnamese Keyword Extraction Using Hybrid Deep Learning Methods - Bui Thanh Hungdaf darfNo ratings yet
- مهم في مقارنة النتائجDocument4 pagesمهم في مقارنة النتائجماهر الملاليNo ratings yet
- 1 PBDocument12 pages1 PBAbdallah GrimaNo ratings yet
- Speech Emotion Recognition Using Neural NetworksDocument6 pagesSpeech Emotion Recognition Using Neural NetworksEditor IJTSRDNo ratings yet
- NER Unbalanced 2003.10296Document7 pagesNER Unbalanced 2003.10296bithi jainNo ratings yet
- Emotion Recognition On Speech Signals Using Machine LearningDocument6 pagesEmotion Recognition On Speech Signals Using Machine LearningSoum SarkarNo ratings yet
- Recognition of Persisting Emotional Valence From EEG Using Convolutional Neural Networks PDFDocument6 pagesRecognition of Persisting Emotional Valence From EEG Using Convolutional Neural Networks PDFMitchell Angel Gomez OrtegaNo ratings yet
- Deep Learning Based Emotion Recognition System Using Speech Features and TranscriptionsDocument12 pagesDeep Learning Based Emotion Recognition System Using Speech Features and TranscriptionskunchalakalyanimscNo ratings yet
- Speech Emotion Analysis Using Convolutional Neural Network (CNN) and Gamma Classifier Based Error Correcting Output Codes (ECOC)Document18 pagesSpeech Emotion Analysis Using Convolutional Neural Network (CNN) and Gamma Classifier Based Error Correcting Output Codes (ECOC)Trung Tín NguyễnNo ratings yet
- Multimodal Emotion Recognition With High-Level Speech and Text Features Mariana Rodrigues Makiuchi, Kuniaki Uto, Koichi Shinoda Tokyo Institute of TechnologyDocument9 pagesMultimodal Emotion Recognition With High-Level Speech and Text Features Mariana Rodrigues Makiuchi, Kuniaki Uto, Koichi Shinoda Tokyo Institute of TechnologyAkhila RNo ratings yet
- 2016-ACL-Combining Discrete and Neural Features For Sequence LabelingDocument15 pages2016-ACL-Combining Discrete and Neural Features For Sequence LabelingYeqing ChangNo ratings yet
- Sentiment Analysis Using Convolutional Neural NetworkDocument6 pagesSentiment Analysis Using Convolutional Neural NetworkOffice WorkNo ratings yet
- (IJCST-V5I2P25) :S. Gopi, A. Berno Raj, M. Abinav, P.Gokul Sarathy, D.P. BharathDocument4 pages(IJCST-V5I2P25) :S. Gopi, A. Berno Raj, M. Abinav, P.Gokul Sarathy, D.P. BharathEighthSenseGroupNo ratings yet
- ASR System: Rashmi KethireddyDocument28 pagesASR System: Rashmi KethireddyRakesh PatelNo ratings yet
- An Introduction To Deep Clustering: Gopi Chand Nutakki, Behnoush Abdollahi, Wenlong Sun, and Olfa NasraouiDocument17 pagesAn Introduction To Deep Clustering: Gopi Chand Nutakki, Behnoush Abdollahi, Wenlong Sun, and Olfa NasraouiAmel KsibiNo ratings yet
- Tan 2021 J. Phys. Conf. Ser. 1994 012016Document6 pagesTan 2021 J. Phys. Conf. Ser. 1994 012016nopal mahingNo ratings yet
- Automatic Detection of Knee Joints and Quantification of Knee Osteoarthritis Severity Using Modified Fully Connected Convolutional Neural NetworksDocument9 pagesAutomatic Detection of Knee Joints and Quantification of Knee Osteoarthritis Severity Using Modified Fully Connected Convolutional Neural NetworksInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- CS 391L Machine Learning Course SyllabusDocument2 pagesCS 391L Machine Learning Course SyllabusOm SinghNo ratings yet
- Email Classification: Roll No-41463 (LP-3)Document5 pagesEmail Classification: Roll No-41463 (LP-3)fgfsgsgNo ratings yet
- Real Time Crowd Monitoring SystemDocument11 pagesReal Time Crowd Monitoring SystemRushiNo ratings yet
- Conference Template A114Document6 pagesConference Template A114akhilsmurf1No ratings yet
- Electronics 11 02306 v2 PDFDocument15 pagesElectronics 11 02306 v2 PDFNaveenKumarNo ratings yet
- PolycopiéDocument3 pagesPolycopiékhaoula BelghitiNo ratings yet
- ML TennisDocument6 pagesML TennisSangeetha KaligitiNo ratings yet
- An Introduction To Artificial Neural NetworkDocument5 pagesAn Introduction To Artificial Neural NetworkMajin BuuNo ratings yet
- Perceptron PDFDocument8 pagesPerceptron PDFVel Ayutham0% (1)
- Applications of Deep Learning For Phishing Detection A Systematic Literature ReviewDocument44 pagesApplications of Deep Learning For Phishing Detection A Systematic Literature ReviewBernardNo ratings yet
- Artificial Neural NetworksDocument13 pagesArtificial Neural NetworksMudit MisraNo ratings yet
- (IJCST-V10I3P24) :kalyani Bang, Rutika Kamble, Shraddha Pandey, Vijayraj Mukwane, A.W.BhadeDocument3 pages(IJCST-V10I3P24) :kalyani Bang, Rutika Kamble, Shraddha Pandey, Vijayraj Mukwane, A.W.BhadeEighthSenseGroupNo ratings yet
- Division of Electrical, Electronics, and Computer Sciences (EECS) Indian Institute of Science, BangaloreDocument2 pagesDivision of Electrical, Electronics, and Computer Sciences (EECS) Indian Institute of Science, BangaloreBatair BerkNo ratings yet
- Personalized Customer Churn Analysis With LSTMDocument5 pagesPersonalized Customer Churn Analysis With LSTMUmitNo ratings yet
- Unit I: Chapter 3:functional Units For Anns For Pattern Recognition TaskDocument24 pagesUnit I: Chapter 3:functional Units For Anns For Pattern Recognition Taskindira100% (1)
- Artificial IntelligenceDocument17 pagesArtificial IntelligenceAppleNo ratings yet
- Handwritten Nepali Character Recognition and Narration System Using Deep CNNDocument61 pagesHandwritten Nepali Character Recognition and Narration System Using Deep CNNPradeepNo ratings yet
- Artificial Intelligence: Long Short Term Memory NetworksDocument14 pagesArtificial Intelligence: Long Short Term Memory NetworksThành Cao ĐứcNo ratings yet
- A2 Poster TemplateDocument1 pageA2 Poster TemplateFaizAhamed ShaikNo ratings yet
- Real-Time American Sign Language Recognition With Convolutional Neural NetworksDocument8 pagesReal-Time American Sign Language Recognition With Convolutional Neural NetworksAditi JaiswalNo ratings yet
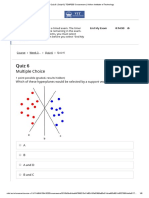
- Quiz 6: Multiple ChoiceDocument6 pagesQuiz 6: Multiple ChoiceAnupamNo ratings yet