You might also like
- Real-Time 3-D Human Body Tracking Using Variable Length Markov ModelsDocument10 pagesReal-Time 3-D Human Body Tracking Using Variable Length Markov ModelsCyrille LamasséNo ratings yet
- Recognizing Actions from Multiple Cameras Using a New Pose-Based RepresentationDocument12 pagesRecognizing Actions from Multiple Cameras Using a New Pose-Based RepresentationhjaraujoNo ratings yet
- 3D Pose Based Feedback For Physical ExercisesDocument17 pages3D Pose Based Feedback For Physical ExercisesChandan KumarNo ratings yet
- Articulated NRSFM With Bone Length ConstraintsDocument11 pagesArticulated NRSFM With Bone Length ConstraintsAhmed ElhayekNo ratings yet
- Journaluploads 498can Skeletal Joint Positional Ordering Influence Action Recognition On Spectrally Graded CNNs A Perspective On Achieving Joint Order Independent LearningDocument16 pagesJournaluploads 498can Skeletal Joint Positional Ordering Influence Action Recognition On Spectrally Graded CNNs A Perspective On Achieving Joint Order Independent Learningsiri.pogulaNo ratings yet
- Tracking Direction of Human Movement - An Efficient Implementation Using SkeletonDocument7 pagesTracking Direction of Human Movement - An Efficient Implementation Using SkeletonAna-Maria ȘtefanNo ratings yet
- Natural Animation of Digitized Models from Motion CaptureDocument8 pagesNatural Animation of Digitized Models from Motion CaptureTeófilo Andrade FarfánNo ratings yet
- Real-Time Human Motion Tracking Using Multiple Depth CamerasDocument7 pagesReal-Time Human Motion Tracking Using Multiple Depth CamerasRishabhRoyNo ratings yet
- Ijct V3i2p5Document9 pagesIjct V3i2p5IjctJournalsNo ratings yet
- Monocular Human Motion Tracking by Using DE-MC Particle FilterDocument14 pagesMonocular Human Motion Tracking by Using DE-MC Particle FilterDavid Augusto RibeiroNo ratings yet
- A method for posture prediction of the upperDocument11 pagesA method for posture prediction of the upperiulia.gherghescuNo ratings yet
- Computer_Vision1Document7 pagesComputer_Vision1MoriwamNo ratings yet
- 3dflex: Determining Structure and Motion of Flexible Proteins From Cryo-EmDocument18 pages3dflex: Determining Structure and Motion of Flexible Proteins From Cryo-Emnoconac494No ratings yet
- 3D Tracking For Gait Characterization and RecognitionDocument6 pages3D Tracking For Gait Characterization and RecognitionschumangelNo ratings yet
- 12328-Article Text-15856-1-2-20201228Document9 pages12328-Article Text-15856-1-2-20201228Hailin SunNo ratings yet
- A Variational Method For The Recovery of Dense 3D Structure From MotionDocument11 pagesA Variational Method For The Recovery of Dense 3D Structure From Motionwalter huNo ratings yet
- Historia Dle MovimientoDocument11 pagesHistoria Dle MovimientoBryan GarciaNo ratings yet
- Recovering Articulated Object Models From 3D Range DataDocument9 pagesRecovering Articulated Object Models From 3D Range DatasigmateNo ratings yet
- File 1667643029 110340 2001-MarkerlessMotionCaptureofComplexFull-BodyMovementforCharacterAnimationDocument12 pagesFile 1667643029 110340 2001-MarkerlessMotionCaptureofComplexFull-BodyMovementforCharacterAnimationdevansh gargNo ratings yet
- Marker-free motion capture from 3D voxel dataDocument10 pagesMarker-free motion capture from 3D voxel dataCyrille LamasséNo ratings yet
- Computer Vision and Image UnderstandingDocument14 pagesComputer Vision and Image UnderstandingFabiola Villalobos-castaldiNo ratings yet
- Tracking Human Motion Using SkelDocument5 pagesTracking Human Motion Using SkelnavyataNo ratings yet
- 3D Skeleton-Based Body Pose RecoveryDocument8 pages3D Skeleton-Based Body Pose RecoveryalioshaNo ratings yet
- Markerless motion captureDocument8 pagesMarkerless motion captureCyrille LamasséNo ratings yet
- Human Activity Recognition: B.Tech Project ReportDocument11 pagesHuman Activity Recognition: B.Tech Project ReportHunter IxNo ratings yet
- Control of Leg Movements Driven by Electrically Stimulated MusclesDocument7 pagesControl of Leg Movements Driven by Electrically Stimulated MusclesBounty JhaNo ratings yet
- MODIFIED Synopsis of The Proposed ResearchDocument23 pagesMODIFIED Synopsis of The Proposed ResearchAshokupadhye1955No ratings yet
- Signal Processing Methods in Human Motion Path Analysis: A Use Case For Karate KataDocument6 pagesSignal Processing Methods in Human Motion Path Analysis: A Use Case For Karate KataTaregh KaramiNo ratings yet
- Algorithms 13 00319Document17 pagesAlgorithms 13 00319Med AmallahNo ratings yet
- Markerless Motion Capture Using Image Features and Physical ConstraintsDocument8 pagesMarkerless Motion Capture Using Image Features and Physical ConstraintsHany ElGezawyNo ratings yet
- Model-Based Human Posture Estimation For Gesture Analysis in An Opportunistic Fusion Smart Camera NetworkDocument6 pagesModel-Based Human Posture Estimation For Gesture Analysis in An Opportunistic Fusion Smart Camera NetworkFaiz HadiNo ratings yet
- Bayesian Estimation of 3-d Human Motion From An Image SequenceDocument19 pagesBayesian Estimation of 3-d Human Motion From An Image SequenceElizar AlmencionNo ratings yet
- Features 2d TrajectoryDocument14 pagesFeatures 2d TrajectorySara RijoNo ratings yet
- Biometrics in image processing to enhance sports performanceDocument8 pagesBiometrics in image processing to enhance sports performanceJaspreet KaurNo ratings yet
- Recovering 3D Human Pose From Monocular Images: Ankur Agarwal and Bill TriggsDocument15 pagesRecovering 3D Human Pose From Monocular Images: Ankur Agarwal and Bill TriggsSriram ElangoNo ratings yet
- Bayesian Stochastic Mesh Optimisation For 3D Reconstruction: George Vogiatzis Philip Torr Roberto CipollaDocument12 pagesBayesian Stochastic Mesh Optimisation For 3D Reconstruction: George Vogiatzis Philip Torr Roberto CipollaneilwuNo ratings yet
- Real-Time People Tracking in A Camera Network: Wasit Limprasert, Andrew Wallace, and Greg MichaelsonDocument9 pagesReal-Time People Tracking in A Camera Network: Wasit Limprasert, Andrew Wallace, and Greg MichaelsonmeetbalakumarNo ratings yet
- Embedded Features For 1D CNN-based Action Recognition On Depth MapsDocument13 pagesEmbedded Features For 1D CNN-based Action Recognition On Depth Mapsjacekt89No ratings yet
- Deep Progressive Reinforcement Learning for Skeleton-Based Action RecognitionDocument10 pagesDeep Progressive Reinforcement Learning for Skeleton-Based Action RecognitionTruong GiangNo ratings yet
- 3D Skeleton-Based Human Action Classification: A SurveyDocument18 pages3D Skeleton-Based Human Action Classification: A Surveyhvnth_88No ratings yet
- Start and End Point Detection of Weightlifting Motion Using CHLAC and MRADocument7 pagesStart and End Point Detection of Weightlifting Motion Using CHLAC and MRArasyoung5302No ratings yet
- Edge Detection and Classification in X-Ray Images. Application To Interventional 3D Vertebra Shape ReconstructionDocument8 pagesEdge Detection and Classification in X-Ray Images. Application To Interventional 3D Vertebra Shape ReconstructionfarancakNo ratings yet
- Common Lines PublishedDocument30 pagesCommon Lines PublishedsonphmNo ratings yet
- A Visualization Framework For The Analysis of Neuromuscular SimulationsDocument11 pagesA Visualization Framework For The Analysis of Neuromuscular Simulationsyacipo evyushNo ratings yet
- Time Invariant Gesture Recognition by Modelling Body Posture SpaceDocument10 pagesTime Invariant Gesture Recognition by Modelling Body Posture Spacebinuq8usaNo ratings yet
- A Method To Analyze Dynamics Properties of Transfemoral ProsthesisDocument5 pagesA Method To Analyze Dynamics Properties of Transfemoral ProsthesisNada GhammemNo ratings yet
- Handbook of Face Recognition: Stan Z. Li Anil K. Jain (Eds.)Document29 pagesHandbook of Face Recognition: Stan Z. Li Anil K. Jain (Eds.)Mahmood AbidNo ratings yet
- International Journals Call For Paper HTTP://WWW - Iiste.org/journalsDocument14 pagesInternational Journals Call For Paper HTTP://WWW - Iiste.org/journalsAlexander DeckerNo ratings yet
- A Review On Design and Implementation of Compensated Frame Prediction & ReconstructionDocument4 pagesA Review On Design and Implementation of Compensated Frame Prediction & ReconstructionerpublicationNo ratings yet
- Silhouette Lookup For Monocular 3D Pose Tracking: Nicholas R. HoweDocument23 pagesSilhouette Lookup For Monocular 3D Pose Tracking: Nicholas R. HoweSudipta GhoshNo ratings yet
- Model-Based 3D Tracking of An Articulated HandDocument6 pagesModel-Based 3D Tracking of An Articulated HandIghor VGNo ratings yet
- View-based Tracking of Body Parts for Visual InteractionDocument10 pagesView-based Tracking of Body Parts for Visual InteractionCyrille LamasséNo ratings yet
- Automatic Tracking Measurement System On Human Lumbar Vertebral MotionDocument4 pagesAutomatic Tracking Measurement System On Human Lumbar Vertebral MotionebrahimpanNo ratings yet
- Signal Processing: D.-N. Truong Cong, L. Khoudour, C. Achard, C. Meurie, O. LezorayDocument13 pagesSignal Processing: D.-N. Truong Cong, L. Khoudour, C. Achard, C. Meurie, O. Lezoraydiavoletta89No ratings yet
- Fingerprint Matching Using Ridges: Jianjiang Feng, Zhengyu Ouyang, Anni CaiDocument10 pagesFingerprint Matching Using Ridges: Jianjiang Feng, Zhengyu Ouyang, Anni Caimanish mathuriaNo ratings yet
- Visualizing Deep Network Training Trajectorieswith PCADocument5 pagesVisualizing Deep Network Training Trajectorieswith PCAIan FooNo ratings yet
- A 2019 Guide To Human Pose Estimation With Deep LearningDocument16 pagesA 2019 Guide To Human Pose Estimation With Deep Learningkmlee9052No ratings yet
- Spatio-Temporal Shape From Silhouette Using Four-Dimensional Delaunay MeshingDocument8 pagesSpatio-Temporal Shape From Silhouette Using Four-Dimensional Delaunay MeshingSo OdetteNo ratings yet
- A New Approach For Gender Classification Based On Gait AnalysisDocument6 pagesA New Approach For Gender Classification Based On Gait AnalysisZahid QaisarNo ratings yet
- 2jawabone AmazonDocument2 pages2jawabone AmazonoriogonNo ratings yet
- 09 Cornea Si Todor But 2 2019Document6 pages09 Cornea Si Todor But 2 2019oriogonNo ratings yet
- ANYCUBIC Mega Manual V2.3 EnglishDocument39 pagesANYCUBIC Mega Manual V2.3 EnglishMarshallNo ratings yet
- ERC Work Programme 2018Document62 pagesERC Work Programme 2018pascal carla lehette corsinoNo ratings yet
- Kindle Paperwhite Users GuideDocument30 pagesKindle Paperwhite Users Guidetomislav8756No ratings yet
- ERC Work Programme 2018Document62 pagesERC Work Programme 2018pascal carla lehette corsinoNo ratings yet
- B.1 Description of The Joint Research Training ProjectDocument3 pagesB.1 Description of The Joint Research Training ProjectoriogonNo ratings yet
- Enterprise Next For Bluetooth TechnologyDocument24 pagesEnterprise Next For Bluetooth TechnologyoriogonNo ratings yet
- Wharton Marketing PrimerDocument19 pagesWharton Marketing PrimeroriogonNo ratings yet
- h2020 Call Fiche17 12 Imi2 Ju enDocument87 pagesh2020 Call Fiche17 12 Imi2 Ju enoriogonNo ratings yet
- ERC Work Programme 2018Document62 pagesERC Work Programme 2018pascal carla lehette corsinoNo ratings yet
- Comparison of Head-Up Display (HUD) vs. Head-Down Display (HDD) Driving PerformanceDocument19 pagesComparison of Head-Up Display (HUD) vs. Head-Down Display (HDD) Driving PerformanceoriogonNo ratings yet
- Suh UserBurdenScale CHI2016Document12 pagesSuh UserBurdenScale CHI2016oriogonNo ratings yet
- h2020 Call Fiche17 12 Imi2 Ju enDocument87 pagesh2020 Call Fiche17 12 Imi2 Ju enoriogonNo ratings yet
- 1989 Modified Barthel IndexDocument7 pages1989 Modified Barthel IndexoriogonNo ratings yet
- 2016 Evaluation of Games in Games and Physical Activity Course CurriculumDocument9 pages2016 Evaluation of Games in Games and Physical Activity Course CurriculumoriogonNo ratings yet
- 10 1 1 142 211Document10 pages10 1 1 142 211hellrayzNo ratings yet
- Kinect FusionDocument10 pagesKinect FusionoriogonNo ratings yet
- TLXScale MultiLocationDocument5 pagesTLXScale MultiLocationoriogonNo ratings yet
- Tao Te ChingDocument29 pagesTao Te ChingNevizzNo ratings yet
- Knee ScopeDocument3 pagesKnee ScopeSherri Shulamit TerebishNo ratings yet
- 2014 Summer Model Answer PaperDocument20 pages2014 Summer Model Answer Papercivil gpkpNo ratings yet
- 3512 Throttle Position Error 91-8Document13 pages3512 Throttle Position Error 91-8harikrishnanpd3327100% (3)
- Chapter No. 01 and 02 Introduction To Hydrology. PrecipitationDocument96 pagesChapter No. 01 and 02 Introduction To Hydrology. PrecipitationRahat ullah0% (1)
- Map 3 D 2015 InstallDocument15 pagesMap 3 D 2015 InstallHarrison HayesNo ratings yet
- Regular Languages and Finite Automata: Lecture Notes OnDocument56 pagesRegular Languages and Finite Automata: Lecture Notes Onchandu903No ratings yet
- Checklist BizTalk Application MigrationDocument11 pagesChecklist BizTalk Application MigrationMadhusudhan AkulaNo ratings yet
- Apr 88372Document2 pagesApr 88372N1234mNo ratings yet
- Type Curves ExplainedDocument59 pagesType Curves Explainedakshay shekhawatNo ratings yet
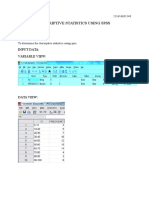
- Descriptive Statistics Using SPSS: Ex No: DateDocument5 pagesDescriptive Statistics Using SPSS: Ex No: Datepecmba11No ratings yet
- Clarke Engine Outline DimDocument9 pagesClarke Engine Outline DimJuli B.No ratings yet
- SAUDI ARAMCO VESSEL CLOSURE CERTIFICATEDocument1 pageSAUDI ARAMCO VESSEL CLOSURE CERTIFICATEAnonymous S9qBDVkyNo ratings yet
- Solar Electricity Handbook 2017 EditionDocument212 pagesSolar Electricity Handbook 2017 Editionandreipopa8467% (6)
- Test-4 SomDocument42 pagesTest-4 SomVivekMishraNo ratings yet
- Parametric Study For Assessing The Effects of Coarseness Factor and Workability Factor On Concrete Compressive StrengthDocument9 pagesParametric Study For Assessing The Effects of Coarseness Factor and Workability Factor On Concrete Compressive StrengthJaga JayNo ratings yet
- Galvanized and Black Malleable Iron Pipe Fittings SpecificationsDocument24 pagesGalvanized and Black Malleable Iron Pipe Fittings Specificationshse vje100% (1)
- Introduction To The Project and Overview of Power System SecurityDocument9 pagesIntroduction To The Project and Overview of Power System Securitysalagasim100% (1)
- Trial Kedah 2014 SPM Kimia K1 K2 K3 Dan Skema (SCAN)Document78 pagesTrial Kedah 2014 SPM Kimia K1 K2 K3 Dan Skema (SCAN)Cikgu Faizal67% (3)
- Entropy Problems AnswersDocument6 pagesEntropy Problems AnswersTots HolaresNo ratings yet
- Portal KombatDocument13 pagesPortal KombatspereiracunhaNo ratings yet
- Joining Text Tables To Replace Technical Names With Descriptions in The HANA View For Drilldown Search PDFDocument10 pagesJoining Text Tables To Replace Technical Names With Descriptions in The HANA View For Drilldown Search PDFRajaNo ratings yet
- HTML Facebook CokDocument3 pagesHTML Facebook CokAldi SoNNo ratings yet
- Concept of Operations DRAFT v1Document84 pagesConcept of Operations DRAFT v1Ramesh dodamaniNo ratings yet
- Adding New Fields To Condition Field CatalogDocument11 pagesAdding New Fields To Condition Field CatalogAnupa Wijesinghe86% (7)
- Park To Playa Trail Feasibility Study and Wayfinding PlanDocument153 pagesPark To Playa Trail Feasibility Study and Wayfinding PlanEmpowerment Congress West Area Neighborhood Development CouncilNo ratings yet
- 1 PDFDocument64 pages1 PDFYogesh KumarNo ratings yet
- Aswan High Dam CompletedDocument29 pagesAswan High Dam CompletedAdib HilmanNo ratings yet
- Onkyo TX SR705Document116 pagesOnkyo TX SR705klynch71100% (3)
- Manual Moto Rev 125Document33 pagesManual Moto Rev 125Mario Recio LoríaNo ratings yet
- 7 Spouses Pereña Vs Spouses ZarateDocument1 page7 Spouses Pereña Vs Spouses ZarateValentine MoralesNo ratings yet