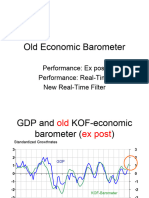
You might also like
- MEM05010C Apply Fabrication, Forming and Shaping Techniques - Learner GuideDocument22 pagesMEM05010C Apply Fabrication, Forming and Shaping Techniques - Learner Guidequestionbank.com.au100% (1)
- APO DP ForecastingDocument64 pagesAPO DP ForecastingKumar Rao100% (1)
- HW 04 AnsDocument12 pagesHW 04 AnsDelphineChenNo ratings yet
- DepreciationDocument35 pagesDepreciationAlexie Gonzales60% (5)
- Biomedical Applications of Time Series AnalysisDocument2 pagesBiomedical Applications of Time Series AnalysisWalter Perez MoronNo ratings yet
- Introduction To Econometrics - Stock & Watson - CH 13 SlidesDocument38 pagesIntroduction To Econometrics - Stock & Watson - CH 13 SlidesAntonio AlvinoNo ratings yet
- R For Programmers PDFDocument370 pagesR For Programmers PDFfaibistesNo ratings yet
- MGS3100 Chapter 13 Forecasting: Slides 13b: Time-Series Models Measuring Forecast ErrorDocument36 pagesMGS3100 Chapter 13 Forecasting: Slides 13b: Time-Series Models Measuring Forecast ErrorSMBEAUTYNo ratings yet
- Analysis of Time SeriesDocument32 pagesAnalysis of Time SeriesAnika KumarNo ratings yet
- Forecasting Ed2Document25 pagesForecasting Ed2Likith RNo ratings yet
- L2432 LCDDocument55 pagesL2432 LCDflyfisherman365No ratings yet
- Complete Business Statistics: Time Series, Forecasting, and Index NumbersDocument37 pagesComplete Business Statistics: Time Series, Forecasting, and Index Numbersmallick5051rajatNo ratings yet
- Time SeriesDocument6 pagesTime SeriescmukherjeeNo ratings yet
- Time Series AnalysisDocument173 pagesTime Series AnalysisMiningBooksNo ratings yet
- Chapter 4 Project Preparation and Analysis - 2Document54 pagesChapter 4 Project Preparation and Analysis - 2Aida Mohammed100% (1)
- Demand Forecasting in A Supply Chain: Chopra and Meindl, Chapter 4Document43 pagesDemand Forecasting in A Supply Chain: Chopra and Meindl, Chapter 4Girish Dey0% (1)
- Chapter 12Document60 pagesChapter 12رضا قاجهNo ratings yet
- Analysis of Time SeriesDocument15 pagesAnalysis of Time Serieshemanthshk1No ratings yet
- Application of Quantitative Methods in Managerial - Data Processing - Classification - SummarizationDocument22 pagesApplication of Quantitative Methods in Managerial - Data Processing - Classification - SummarizationRajat KukretiNo ratings yet
- Time Series AnalysisDocument22 pagesTime Series AnalysisadeelahmadaNo ratings yet
- Forecasting-Seasonal ModelsDocument34 pagesForecasting-Seasonal Modelssuriani hamsahNo ratings yet
- Time SeriesDocument61 pagesTime Serieskomal kashyapNo ratings yet
- Introduction - Reasons - Forecasting MethodsDocument30 pagesIntroduction - Reasons - Forecasting MethodspatsjitNo ratings yet
- ARIJIT MONDAL (Final Assignment)Document14 pagesARIJIT MONDAL (Final Assignment)arijitmondal87No ratings yet
- Time Series Analysis: Prof GRC NairDocument22 pagesTime Series Analysis: Prof GRC Nairanindya_kunduNo ratings yet
- Demand Forecasting KarthiDocument62 pagesDemand Forecasting KarthiSiddharth Narayanan ChidambareswaranNo ratings yet
- Time Series AnalysisDocument17 pagesTime Series AnalysisLok JoshiNo ratings yet
- Model For Analysis and Simulations: A Small Open Economy DSGE For ChileDocument27 pagesModel For Analysis and Simulations: A Small Open Economy DSGE For ChileHero GspriloNo ratings yet
- Estp Introduction To Seasonal Adjustment and JdemetraDocument77 pagesEstp Introduction To Seasonal Adjustment and JdemetraChristian Alfred VillenaNo ratings yet
- Demand ForecastingDocument34 pagesDemand ForecastingKaustubh ChaudharyNo ratings yet
- Chap15 - Time Series Forecasting & Index NumberDocument60 pagesChap15 - Time Series Forecasting & Index NumberLando DamanikNo ratings yet
- ForecastingDocument70 pagesForecastingKent Ryan Gallano Maglasang100% (1)
- Forecasting-Seasonal ModelsDocument35 pagesForecasting-Seasonal ModelsanubhavNo ratings yet
- Demand Forecasting 3&4Document44 pagesDemand Forecasting 3&4niruthirNo ratings yet
- Analyzing and Forecasting Time Series DataDocument41 pagesAnalyzing and Forecasting Time Series DataKanta GangulyNo ratings yet
- Instrumentation DAMT 117Document209 pagesInstrumentation DAMT 117Nurul HisyamNo ratings yet
- Timeseries PPT 1ODocument64 pagesTimeseries PPT 1OVIVEK SHARMANo ratings yet
- Timeseries PPT 1ODocument64 pagesTimeseries PPT 1OVIVEK SHARMANo ratings yet
- QM 7 Panel Regression Fixed EffectsDocument36 pagesQM 7 Panel Regression Fixed EffectsDarkasy EditsNo ratings yet
- Timeseries Analysis and MeasurementDocument44 pagesTimeseries Analysis and MeasurementAdil Bin KhalidNo ratings yet
- Methods of Forecasting in A Manufacturing CompanyDocument31 pagesMethods of Forecasting in A Manufacturing Companyeuge_prime2001No ratings yet
- Presented By:-: Sutripti DattaDocument44 pagesPresented By:-: Sutripti DattaSutripti BardhanNo ratings yet
- Time Series Data: y + X + - . .+ X + UDocument81 pagesTime Series Data: y + X + - . .+ X + Uraja ahmedNo ratings yet
- Business StatisticsDocument26 pagesBusiness Statisticsrain1892002No ratings yet
- Chapter 7 (Forecasting)Document37 pagesChapter 7 (Forecasting)IndiraNo ratings yet
- BNM854 Measures of LocationDocument11 pagesBNM854 Measures of LocationAkshaykumar WaddarkallNo ratings yet
- Econometric Analysis: DR Alka Chadha IIM TrichyDocument29 pagesEconometric Analysis: DR Alka Chadha IIM TrichyChintu KumarNo ratings yet
- Forecast Proposal For Intek Tapes: Project Work Submitted To: University at Buffalo, The State University at New YorkDocument23 pagesForecast Proposal For Intek Tapes: Project Work Submitted To: University at Buffalo, The State University at New Yorktipo_de_incognitoNo ratings yet
- Introduction To Seasonal AdjustmentDocument73 pagesIntroduction To Seasonal AdjustmentAdil Bin KhalidNo ratings yet
- The 7 Basic Quality Tools: Michele CanoDocument60 pagesThe 7 Basic Quality Tools: Michele Canoeko4fxNo ratings yet
- Time SeriesDocument51 pagesTime SeriesSailesh AkkarajuNo ratings yet
- Carrying Cost: Inventory CostsDocument31 pagesCarrying Cost: Inventory CostsVivek Kumar GuptaNo ratings yet
- Business Forecasting & Time Series AnalysisDocument28 pagesBusiness Forecasting & Time Series AnalysisSauriya SinhaNo ratings yet
- Financial RatiosDocument78 pagesFinancial Ratiospun33tNo ratings yet
- NoboyamaDocument76 pagesNoboyamasamadozoure120No ratings yet
- Preferred NumbersDocument8 pagesPreferred NumbersElaine Morato100% (1)
- Notes On ForecastingDocument12 pagesNotes On ForecastingJulienne Aristoza100% (1)
- Switchboard Instruments Data Sheet 4921210012 UKDocument8 pagesSwitchboard Instruments Data Sheet 4921210012 UKEdi LeeNo ratings yet
- S6 - Time - Series Analysis - 1Document21 pagesS6 - Time - Series Analysis - 1Thiên CầmNo ratings yet
- Spring & Wire Products World Summary: Market Values & Financials by CountryFrom EverandSpring & Wire Products World Summary: Market Values & Financials by CountryNo ratings yet
- Fabricated Steel Plate Work World Summary: Market Values & Financials by CountryFrom EverandFabricated Steel Plate Work World Summary: Market Values & Financials by CountryNo ratings yet
- Curriculum of Ms in Avionics EngineeringDocument34 pagesCurriculum of Ms in Avionics EngineeringUfi70No ratings yet
- III Sem. BA Economics - Core Course - Quantitative Methods For Economic Analysis - 1Document29 pagesIII Sem. BA Economics - Core Course - Quantitative Methods For Economic Analysis - 1Agam Reddy M50% (2)
- Market ForecastDocument23 pagesMarket ForecastGowthaman RajNo ratings yet
- Chapter - 8.pdf Filename UTF-8''Chapter 8Document36 pagesChapter - 8.pdf Filename UTF-8''Chapter 8Jinky P. RefurzadoNo ratings yet
- Scatter Diagrams and Time SeriesDocument11 pagesScatter Diagrams and Time SeriesElla LawanNo ratings yet
- StatisticsDocument35 pagesStatisticsSophiya PrabinNo ratings yet
- Forecasting Non-Stationary Time Series by Wavelet Process Modelling (Lsero)Document32 pagesForecasting Non-Stationary Time Series by Wavelet Process Modelling (Lsero)Ana ScaletNo ratings yet
- Forecasting Open-High-Low-Close Data Contained inDocument37 pagesForecasting Open-High-Low-Close Data Contained inmmm_gggNo ratings yet
- Apiyeva Phd.Document265 pagesApiyeva Phd.mjamil08086No ratings yet
- QA QC ProceduresDocument16 pagesQA QC ProceduresAlbert Lucky100% (1)
- Forecasting MethodsDocument38 pagesForecasting MethodsabrilNo ratings yet
- DF-GLS vs. Augmented Dickey-Fuller: Elliott, Rothenberg, and Stock 1996Document3 pagesDF-GLS vs. Augmented Dickey-Fuller: Elliott, Rothenberg, and Stock 1996Shahabuddin ProdhanNo ratings yet
- AHGW Tool Wells and Time SeriesDocument26 pagesAHGW Tool Wells and Time SerieshereticbongNo ratings yet
- Neha-10 Assignment-IIDocument7 pagesNeha-10 Assignment-IINeha SinghNo ratings yet
- Dumitrescu & Birsan (2015) ROCADA Gridded Daily Climatic Dataset, Nat Hazards (Online)Document19 pagesDumitrescu & Birsan (2015) ROCADA Gridded Daily Climatic Dataset, Nat Hazards (Online)Corduneanu FlavianaNo ratings yet
- Time Series Analysis I: Discussion Questions - These Will Be Covered in The Quick QuizDocument7 pagesTime Series Analysis I: Discussion Questions - These Will Be Covered in The Quick QuizPraful N KNo ratings yet
- Bhutto ReformsDocument19 pagesBhutto ReformsFaiqa Mir100% (1)
- Budget and Budgeting Control in A Business Organization: Sanjith CDocument32 pagesBudget and Budgeting Control in A Business Organization: Sanjith CSanjith CNo ratings yet
- Synchro Software User Guide: 2.2 Release Date: 2012-09-08Document52 pagesSynchro Software User Guide: 2.2 Release Date: 2012-09-08Kirchooff kNo ratings yet
- Capital Market QuizDocument1 pageCapital Market QuizBunnyNo ratings yet
- Frequency Analysis ExamplesDocument13 pagesFrequency Analysis ExamplessherryshahNo ratings yet
- QuantiDocument72 pagesQuantilouvelleNo ratings yet
- (Q) What Does It Mean When Adf and Kpss Shows Contradictory Results?: StatisticsDocument1 page(Q) What Does It Mean When Adf and Kpss Shows Contradictory Results?: StatisticsvaskoreNo ratings yet
- Environmental ForecastingDocument26 pagesEnvironmental ForecastingSindhu Manja67% (3)
- RNN LSTM Example Implementations With Keras TensorFlowDocument20 pagesRNN LSTM Example Implementations With Keras TensorFlowRichard SmithNo ratings yet
- Chapter 2 ForecastingDocument42 pagesChapter 2 Forecastingworkumogess3100% (1)
- HP Calculators: HP 39gs Aplets and E-LessonsDocument5 pagesHP Calculators: HP 39gs Aplets and E-LessonsLeonardo NascimentoNo ratings yet