You might also like
- ECN 813 Dummy VariableDocument21 pagesECN 813 Dummy VariableYusuf ShotundeNo ratings yet
- Logistic Regression: Prof. Andy FieldDocument34 pagesLogistic Regression: Prof. Andy FieldSyedNo ratings yet
- GLMDocument26 pagesGLMNirmal RoyNo ratings yet
- Psy 512 Logistic RegressionDocument12 pagesPsy 512 Logistic RegressionAbhinav NigamNo ratings yet
- Logistic RegressionDocument37 pagesLogistic RegressionDhruv BansalNo ratings yet
- 7,8-Simple Regression PDFDocument47 pages7,8-Simple Regression PDFKevin HyunNo ratings yet
- Business Econometrics Using SAS Tools (BEST) : Class XI and XII - OLS BLUE and Assumption ErrorsDocument15 pagesBusiness Econometrics Using SAS Tools (BEST) : Class XI and XII - OLS BLUE and Assumption ErrorsPulkit AroraNo ratings yet
- GLMDocument12 pagesGLMformak_tejNo ratings yet
- RegressionDocument24 pagesRegressionVaruni GuptaNo ratings yet
- Logistic RegressionDocument24 pagesLogistic RegressionVeerpal KhairaNo ratings yet
- Lecture2 Math ML ReviewDocument87 pagesLecture2 Math ML ReviewLishanZhuNo ratings yet
- Classical Linear Regression Model (CLRM)Document68 pagesClassical Linear Regression Model (CLRM)Nigussie BerhanuNo ratings yet
- Dsur I Chapter 08 Logistic RegressionDocument41 pagesDsur I Chapter 08 Logistic RegressionDannyNo ratings yet
- Eco 3Document68 pagesEco 3Nebiyu WoldesenbetNo ratings yet
- Chap10 Logistic RegressionDocument36 pagesChap10 Logistic RegressionJakhongirNo ratings yet
- Regression Analysis Estimation and Interpretation of Regression Equation Dummy Independent VariableDocument39 pagesRegression Analysis Estimation and Interpretation of Regression Equation Dummy Independent VariableTaimoor WaraichNo ratings yet
- Logit and Probit: Models With Discrete Dependent VariablesDocument30 pagesLogit and Probit: Models With Discrete Dependent VariablesVida Suelo QuitoNo ratings yet
- Binary Logistic Regression Lecture 9Document33 pagesBinary Logistic Regression Lecture 9Trongtin LeeNo ratings yet
- Ordinary Least SquaresDocument21 pagesOrdinary Least SquaresRahulsinghooooNo ratings yet
- Linear RegressionDocument11 pagesLinear Regressiondishu.diwanshiNo ratings yet
- Multiple RegressionDocument16 pagesMultiple RegressionPrashant GuptaNo ratings yet
- Quantile RegressionDocument43 pagesQuantile RegressionSavita KayNo ratings yet
- Session 2.1 Logistic RegressionDocument15 pagesSession 2.1 Logistic Regressionspringfield12No ratings yet
- Chapter 3Document80 pagesChapter 3getaw bayuNo ratings yet
- Week9 LPMDocument16 pagesWeek9 LPMalisyahrahmiNo ratings yet
- Logistic Regression (Autosaved)Document21 pagesLogistic Regression (Autosaved)Siddharth DoshiNo ratings yet
- CUHK STAT5102 Ch7Document33 pagesCUHK STAT5102 Ch7Tsoi Yun PuiNo ratings yet
- Logistic ClassificationDocument44 pagesLogistic ClassificationN Samhing100% (1)
- Introduction To Logistic RegressionDocument20 pagesIntroduction To Logistic Regressionjaishree jainNo ratings yet
- Briefly Discuss The Concept of LR AnalysisDocument9 pagesBriefly Discuss The Concept of LR AnalysisRozen Tareque HasanNo ratings yet
- Advanced Regression With JMP PRO HandoutDocument46 pagesAdvanced Regression With JMP PRO HandoutGabriel GomezNo ratings yet
- 3-Linear Regreesion-AssumptionsDocument28 pages3-Linear Regreesion-AssumptionsMonis KhanNo ratings yet
- Logistic RegressionDocument25 pagesLogistic RegressiontsandrasanalNo ratings yet
- Linear Regression - Stats 2 (Translated)Document63 pagesLinear Regression - Stats 2 (Translated)Alysha SyalaNo ratings yet
- Logistic RegressionDocument27 pagesLogistic RegressionChenelly AlcasidNo ratings yet
- Machine Learning and Linear RegressionDocument55 pagesMachine Learning and Linear RegressionKapil Chandel100% (1)
- CH 5. Discrete Choice ModelDocument38 pagesCH 5. Discrete Choice Modeltemesgen yohannesNo ratings yet
- Multicollinearity and Endogeneity PDFDocument37 pagesMulticollinearity and Endogeneity PDFvivavivu123No ratings yet
- Lecture15 Binary Dependent VariablesDocument38 pagesLecture15 Binary Dependent Variablesscribdreader12No ratings yet
- Chap3 - Multiple RegressionDocument56 pagesChap3 - Multiple RegressionNguyễn Lê Minh AnhNo ratings yet
- Lecture7 Logistic RegressionDocument25 pagesLecture7 Logistic Regression翁江靖No ratings yet
- Quantitative Analysis III Slides (Printer-Friendly) - 2023.03.15Document52 pagesQuantitative Analysis III Slides (Printer-Friendly) - 2023.03.15LilliaNo ratings yet
- Mathematics in Machine LearningDocument83 pagesMathematics in Machine LearningSubha OPNo ratings yet
- Correlation and Regression: Associate Professor Georgi Iskrov, PHD Department of Social Medicine and Public HealthDocument28 pagesCorrelation and Regression: Associate Professor Georgi Iskrov, PHD Department of Social Medicine and Public HealthKARTHIK SREEKUMARNo ratings yet
- Lecture+8+ +Linear+RegressionDocument45 pagesLecture+8+ +Linear+RegressionSupaapt SrionNo ratings yet
- Simple Linear Regression Analysis - FinalDocument46 pagesSimple Linear Regression Analysis - FinalPrarthanaNo ratings yet
- Logistic RegressionDocument54 pagesLogistic RegressionFerran RodríguezNo ratings yet
- Lecture 6 LPMDocument14 pagesLecture 6 LPMRicha JhaNo ratings yet
- Chapter 3Document36 pagesChapter 3feyisaabera19No ratings yet
- QRM - Week 3 Lecture - CanvasDocument25 pagesQRM - Week 3 Lecture - Canvasrxh6kp5pp9No ratings yet
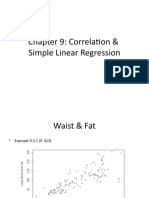
- Chapter 9: Correlation & Simple Linear RegressionDocument17 pagesChapter 9: Correlation & Simple Linear RegressionKadir OzcanNo ratings yet
- Sonek Linear Regression NotesDocument11 pagesSonek Linear Regression NotesAlfredNo ratings yet
- BivariateDocument28 pagesBivariateVikas SainiNo ratings yet
- Slides - Simple Linear RegressionDocument35 pagesSlides - Simple Linear RegressionJarir AhmedNo ratings yet
- 02 LogisticRegressionDocument29 pages02 LogisticRegressionMauJuarezSanNo ratings yet
- Stats101A - Chapter 1Document25 pagesStats101A - Chapter 1Zhen WangNo ratings yet
- Unit VDocument27 pagesUnit V05Bala SaatvikNo ratings yet
- Ch01 02 03 Final BDocument63 pagesCh01 02 03 Final BMaria Cristina RossiNo ratings yet