You might also like
- Introduction To Computing and Problem Solving With Python.Document11 pagesIntroduction To Computing and Problem Solving With Python.Anonymous csXH4d3X50% (4)
- Tutorial 2 - Systems (Exercises)Document3 pagesTutorial 2 - Systems (Exercises)LEIDYDANNYTSNo ratings yet
- Amazon SDE Interview PrepDocument4 pagesAmazon SDE Interview Prepkarunakarms8076100% (1)
- Checking Makes Recursion More Useful.: Advantages of LispDocument4 pagesChecking Makes Recursion More Useful.: Advantages of LisplalithaNo ratings yet
- Daa AssignmentDocument11 pagesDaa AssignmentDhruv SahgalNo ratings yet
- Question BankDocument10 pagesQuestion BankJeeva JeeNo ratings yet
- Ix B (1+log P, Log Log Q Log (1 + Ix), Log Log N q+1) P N p+1) Q Theta) Exp (P QDocument14 pagesIx B (1+log P, Log Log Q Log (1 + Ix), Log Log N q+1) P N p+1) Q Theta) Exp (P QssfofoNo ratings yet
- EEE243/ECE243 Signals and Systems - Assignment : Please Show All The Integrations. Do Not Use Any CalculatorsDocument5 pagesEEE243/ECE243 Signals and Systems - Assignment : Please Show All The Integrations. Do Not Use Any CalculatorsRedwan AhmedNo ratings yet
- SS Unit 1 QBDocument4 pagesSS Unit 1 QBesesesNo ratings yet
- Data Structures and AlgorithmsDocument32 pagesData Structures and AlgorithmsespyterNo ratings yet
- 2019.02.04 L06 S&S Systems PropertiesDocument24 pages2019.02.04 L06 S&S Systems PropertiesbilalNo ratings yet
- Minor 1 Solution PDFDocument6 pagesMinor 1 Solution PDFgNo ratings yet
- Ecb 204Document2 pagesEcb 204Vivek SharmaNo ratings yet
- C# Programming Reference SheetDocument1 pageC# Programming Reference SheetLNo ratings yet
- Recursive TypesDocument23 pagesRecursive TypesYuyun JoeNo ratings yet
- Python Loops and IterationsDocument37 pagesPython Loops and IterationsPkumar ChoureNo ratings yet
- Quick SorthvjnvDocument62 pagesQuick SorthvjnvdsrNo ratings yet
- Recurrent BPTT Aug Dec 2020Document66 pagesRecurrent BPTT Aug Dec 2020acer asusNo ratings yet
- CBSE Class 12 Informatics Practices Commonly Used Libraries PDFDocument2 pagesCBSE Class 12 Informatics Practices Commonly Used Libraries PDFKhushboo DabalaNo ratings yet
- 2-D Plots: Style Option') Where X Values and y Values Are Vectors of The Same Length ContainingDocument7 pages2-D Plots: Style Option') Where X Values and y Values Are Vectors of The Same Length ContainingIRSHAD M KNo ratings yet
- PythonDocument372 pagesPythonMaTi UR ReHmanNo ratings yet
- Quick Introduction To Hypermath: D:/Hw110 - 64/Help/Hmath/Hmath - HTM)Document4 pagesQuick Introduction To Hypermath: D:/Hw110 - 64/Help/Hmath/Hmath - HTM)Abhishek AroraNo ratings yet
- GPU Programming Lecture 8 FFTDocument40 pagesGPU Programming Lecture 8 FFTRajulNo ratings yet
- Verify Faraday's Law of Induction with Arduino DUEDocument29 pagesVerify Faraday's Law of Induction with Arduino DUEpepgoteNo ratings yet
- BITS Pilani Comprehensive Exam Questions on Programming LanguagesDocument3 pagesBITS Pilani Comprehensive Exam Questions on Programming LanguagesRishab JainNo ratings yet
- Communicati N Systems: Prof. Wonjae ShinDocument33 pagesCommunicati N Systems: Prof. Wonjae Shin이동준No ratings yet
- LAB SESSSION 01 (AutoRecovered)Document12 pagesLAB SESSSION 01 (AutoRecovered)Bhavana100% (2)
- Lecture 1Document47 pagesLecture 1oswardNo ratings yet
- Quick Sort and Merge Sort Algorithms ExplainedDocument90 pagesQuick Sort and Merge Sort Algorithms ExplainedGayatri JethaniNo ratings yet
- 2014 p01 q02 SolutionsDocument2 pages2014 p01 q02 SolutionsodarefisherNo ratings yet
- CSC 453 Intermediate Code Generation: Saumya DebrayDocument42 pagesCSC 453 Intermediate Code Generation: Saumya DebrayJitendra PatelNo ratings yet
- CS 12 MS Set-HDocument13 pagesCS 12 MS Set-Hvikas_2No ratings yet
- PART-A (2 Marks) : Unit IDocument4 pagesPART-A (2 Marks) : Unit IToonNo ratings yet
- DSP Question Bank for Digital Signal ProcessingDocument12 pagesDSP Question Bank for Digital Signal ProcessingBizura SarumaNo ratings yet
- Ds&algoritms MCQDocument14 pagesDs&algoritms MCQWOLVERINEffNo ratings yet
- Department of Electronics & Communication Engineering: Amrapali Institute OF Technology and SciencesDocument42 pagesDepartment of Electronics & Communication Engineering: Amrapali Institute OF Technology and SciencesEr Gaurav PandeyNo ratings yet
- MERGE SORT AND QUICK SORT 16122021 120657pm 07112022 094016amDocument30 pagesMERGE SORT AND QUICK SORT 16122021 120657pm 07112022 094016amZeeshan ibrarNo ratings yet
- Java Frequency Distribution Program Calculates Class IntervalsDocument2 pagesJava Frequency Distribution Program Calculates Class Intervals30. Oktavianus Kia LibuNo ratings yet
- UnfoldingDocument11 pagesUnfoldinghshheNo ratings yet
- HW2 solutionDocument7 pagesHW2 solutionsrathi1220No ratings yet
- Random ProcessDocument30 pagesRandom Process20-051 Vigneshwar PNo ratings yet
- Fundamental of Computer Science Practical FileDocument63 pagesFundamental of Computer Science Practical FileGaurav ThakurNo ratings yet
- BIRLA INSTITUTE OF TECHNOLOGY & SCIENCE, PILANI TEST I (REGULARDocument2 pagesBIRLA INSTITUTE OF TECHNOLOGY & SCIENCE, PILANI TEST I (REGULARVishal MittalNo ratings yet
- Comp 03Document10 pagesComp 03alaospdjaoeosNo ratings yet
- Solving Dsa Interview QuestionsDocument32 pagesSolving Dsa Interview QuestionsVritika Naik100% (1)
- Chapter9 NokeyDocument14 pagesChapter9 NokeyTran Quang Khoa (K18 HCM)No ratings yet
- BluSTL Controller Synthesis From Signal Temporal Logic SpecificationsDocument9 pagesBluSTL Controller Synthesis From Signal Temporal Logic SpecificationsRaghavendra M BhatNo ratings yet
- Ada Lab NewDocument37 pagesAda Lab Newhenee patelNo ratings yet
- Introduction To Computer Science I Harvard CollegeDocument28 pagesIntroduction To Computer Science I Harvard CollegeparaagpandeyNo ratings yet
- Maximum and Minimum Using Divide and Conquer in CDocument13 pagesMaximum and Minimum Using Divide and Conquer in CragunathNo ratings yet
- DAA Module 2 Power Point-S.MercyDocument48 pagesDAA Module 2 Power Point-S.MercyIshita SinghalNo ratings yet
- SAMPLE PAPER-I Class XII (Computer Science) HALF YEARLYDocument8 pagesSAMPLE PAPER-I Class XII (Computer Science) HALF YEARLYDeepika AggarwalNo ratings yet
- Chapter 3Document17 pagesChapter 3sateesh reddyNo ratings yet
- Discrete Time Control Systems Unit 5Document23 pagesDiscrete Time Control Systems Unit 5kishan guptaNo ratings yet
- Digital Signal Processing PDFDocument158 pagesDigital Signal Processing PDFVenkatesan SwamyNo ratings yet
- Lecture 2: Data StructuresDocument5 pagesLecture 2: Data StructuresVan Vy HongNo ratings yet
- Lecture 5: Linear Sorting: ReviewDocument5 pagesLecture 5: Linear Sorting: ReviewVan Vy HongNo ratings yet
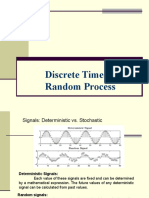
- Discrete Time Random ProcessDocument35 pagesDiscrete Time Random ProcessSundarRajanNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- Tables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesFrom EverandTables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesNo ratings yet
- How To Excel During An Amazon Intervie1Document3 pagesHow To Excel During An Amazon Intervie1ShivamNo ratings yet
- 5 - Programming of MicroprocessorDocument64 pages5 - Programming of MicroprocessorShivamNo ratings yet
- Prog MicroprocessorDocument9 pagesProg Microprocessorbabji049No ratings yet
- ch5 SynchronizationDocument61 pagesch5 SynchronizationShivamNo ratings yet
- Data ReqDocument1 pageData ReqShivamNo ratings yet
- PHYSICSDocument6 pagesPHYSICSShivamNo ratings yet
- Maths Chapter 2Document18 pagesMaths Chapter 2ShivamNo ratings yet
- As 22 Korkos AMSI and BypassDocument53 pagesAs 22 Korkos AMSI and BypassZdhsiaodujasNo ratings yet
- Agile in ERP ProjectsDocument18 pagesAgile in ERP ProjectsThiago Augusto100% (1)
- CIS 111 Exam 1 (50 Points) Fall 2020Document5 pagesCIS 111 Exam 1 (50 Points) Fall 2020GeorgeNo ratings yet
- OOP Java Inheritance ExamplesDocument10 pagesOOP Java Inheritance ExamplesMuhammad Talha AtharNo ratings yet
- Assesment Answer KeyDocument11 pagesAssesment Answer KeyVenu GopalNo ratings yet
- OpenCV With MingW & Code-BlockDocument11 pagesOpenCV With MingW & Code-BlockSanjeev ShekharNo ratings yet
- ACT API Reference GuideDocument4,956 pagesACT API Reference GuidesssNo ratings yet
- How To Create An Awesome Github Profile READMEDocument14 pagesHow To Create An Awesome Github Profile READMEphaedonvNo ratings yet
- Lecture 1 (Part I) : Lecturers: Darwin Vargas - Darwin - Vargas@tup - Edu.phDocument12 pagesLecture 1 (Part I) : Lecturers: Darwin Vargas - Darwin - Vargas@tup - Edu.phdarwinvargas2011No ratings yet
- DevOps 101 Ebook Single Page PDFDocument39 pagesDevOps 101 Ebook Single Page PDFkingprimexNo ratings yet
- CrudoDocument16 pagesCrudodavisxzNo ratings yet
- 1020notes PDFDocument428 pages1020notes PDFAndreaNo ratings yet
- S01 - Getting Started: Welcome To Bw4Hana TrainingDocument31 pagesS01 - Getting Started: Welcome To Bw4Hana TrainingVenkateswarlu PurushothamNo ratings yet
- Power Platform Licensing Guide - November 2021 - FINAL PUB v2Document32 pagesPower Platform Licensing Guide - November 2021 - FINAL PUB v2Antonio CaminoNo ratings yet
- Empowerment Technologies Activity #2Document4 pagesEmpowerment Technologies Activity #2JADDINOPOLNo ratings yet
- Programming Methodologies Quick GuideDocument26 pagesProgramming Methodologies Quick GuideRedan PabloNo ratings yet
- MCQs On 2ndDocument24 pagesMCQs On 2ndmy pcNo ratings yet
- Compiler Design Lab ManualDocument19 pagesCompiler Design Lab ManualOlga RajeeNo ratings yet
- Application Architecture - Grab Fried Onion Rings and Throw Spear Into Onion Architecture and Domain Driven Design - CodeProjectDocument17 pagesApplication Architecture - Grab Fried Onion Rings and Throw Spear Into Onion Architecture and Domain Driven Design - CodeProjectVuongX.TrinhNo ratings yet
- Python Optimization Modeling Objects (Pyomo)Document17 pagesPython Optimization Modeling Objects (Pyomo)arteepu4No ratings yet
- Hostel Management SystemDocument202 pagesHostel Management SystemSudhir KumarNo ratings yet
- Introduction To REF CURSORDocument10 pagesIntroduction To REF CURSORftazyeenNo ratings yet
- E-Street Project Report 05 - 157Document100 pagesE-Street Project Report 05 - 157Vaibhav GangwarNo ratings yet
- Word Processing ApplicationDocument44 pagesWord Processing ApplicationRobert Jake CotonNo ratings yet
- Ananta Bhowmick: Co-Founder & Designer. Xenorm OfficialDocument1 pageAnanta Bhowmick: Co-Founder & Designer. Xenorm OfficialShafin CTSNo ratings yet
- Norelhoda's Resume-14Document1 pageNorelhoda's Resume-14Noor KhaledNo ratings yet
- Programming Concepts in C++ Marking SchemeDocument3 pagesProgramming Concepts in C++ Marking SchemepinghooNo ratings yet
- List of Word Processors: 1 Free and Open-Source SoftwareDocument4 pagesList of Word Processors: 1 Free and Open-Source SoftwareArun Malaikandan SubramanianNo ratings yet
- Worksheet-3 3Document12 pagesWorksheet-3 3sonu sauravNo ratings yet