0% found this document useful (0 votes)
2K views25 pagesChapter 3 Regular Expression
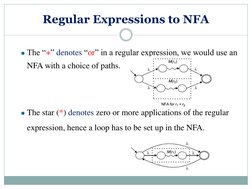
Regular expressions were designed to represent regular languages using primitives like symbols, parentheses, and operators. A regular expression combines strings from an alphabet using operations like union, concatenation, and Kleene star. Regular expressions can be used to define regular languages and can be represented by nondeterministic finite automata through operations on the regular expressions. The pumping lemma can be used to prove that a language is not regular by finding a contradiction for any string of length greater than the pumping length c.
Uploaded by
mimisbhatuCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PPTX, PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
2K views25 pagesChapter 3 Regular Expression
Regular expressions were designed to represent regular languages using primitives like symbols, parentheses, and operators. A regular expression combines strings from an alphabet using operations like union, concatenation, and Kleene star. Regular expressions can be used to define regular languages and can be represented by nondeterministic finite automata through operations on the regular expressions. The pumping lemma can be used to prove that a language is not regular by finding a contradiction for any string of length greater than the pumping length c.
Uploaded by
mimisbhatuCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PPTX, PDF, TXT or read online on Scribd
- Regular Expressions: Introduces and explains regular expressions, their construction, and usage with examples and mathematical underpinnings.
- Finite Automata with Output: Covers finite automata including Mealy and Moore machines, their structures, and outputs based on states and inputs.
- Regular Languages: Explores the concept of regular languages, their recognition via DFAs, and inclusion within regular language classes.
- DFA Complements: Explains complement operations on DFAs and their applications to regular languages.