You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5795)
- Introduction To Data ScienceDocument22 pagesIntroduction To Data ScienceKhuram ToorNo ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Mining Data Streams: The Stream Model Sliding Windows Counting 1'sDocument27 pagesMining Data Streams: The Stream Model Sliding Windows Counting 1'sKhuram ToorNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
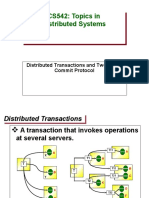
- Lecture 13: Distributed Transactions: Notes Adapted From Tanenbaum's "Distributed Systems Principles and Paradigms"Document24 pagesLecture 13: Distributed Transactions: Notes Adapted From Tanenbaum's "Distributed Systems Principles and Paradigms"Khuram ToorNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- CS542: Topics in Distributed SystemsDocument11 pagesCS542: Topics in Distributed SystemsKhuram ToorNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Openstack and Eucalyptus On Futuregrid: Presenters: Javier Diaz Gregor Von LaszewskiDocument27 pagesOpenstack and Eucalyptus On Futuregrid: Presenters: Javier Diaz Gregor Von LaszewskiKhuram ToorNo ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- COMP 122 - Design and Analysis of Algorithms: MW 11:00-12:15, SN 014Document22 pagesCOMP 122 - Design and Analysis of Algorithms: MW 11:00-12:15, SN 014Khuram ToorNo ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Practical NoandDocument60 pagesPractical NoandAtharv Potdar100% (1)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Crash Course in C: "A Little Learning Is A Dangerous Thing." (Alexander Pope)Document20 pagesCrash Course in C: "A Little Learning Is A Dangerous Thing." (Alexander Pope)Tanaka GumberoNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Pamantasan NG Lungsod NG Muntinlupa: Pinoy Legend: An Android-Based Adventure Game With Selected Unsung Filipino HeroesDocument52 pagesPamantasan NG Lungsod NG Muntinlupa: Pinoy Legend: An Android-Based Adventure Game With Selected Unsung Filipino HeroesLuis Laluna AbawagNo ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Cse325 Os Laboratory Manual PDFDocument37 pagesCse325 Os Laboratory Manual PDFShoaib AkhterNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- 360 Scripting Guide2017Document290 pages360 Scripting Guide2017Vivek ChaurasiyaNo ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- 15ec62 Paper2Document2 pages15ec62 Paper2Nikhil KulkarniNo ratings yet
- Event Handlers D365foDocument3 pagesEvent Handlers D365foSaibabu AkkalaNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- A Flower Recognition System Based On Image Processing and Neural Network2Document11 pagesA Flower Recognition System Based On Image Processing and Neural Network2Aravindh ArunNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- An Easy Way To Cast Video From Linux To Chromecast GnomecastDocument2 pagesAn Easy Way To Cast Video From Linux To Chromecast GnomecastConstantinos AlvanosNo ratings yet
- Linux Operatig SystemDocument21 pagesLinux Operatig SystemMuhammad Yusif AbdulrahmanNo ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Operate Database Application - AssignmentDocument4 pagesOperate Database Application - AssignmentSamson Girma0% (1)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1091)
- 5G Campus Networks A First Measurement StudyDocument21 pages5G Campus Networks A First Measurement StudyGANGLIAN DRAMANo ratings yet
- Integration Guide by OTPlessDocument8 pagesIntegration Guide by OTPlessBhavik KoladiyaNo ratings yet
- Assembly Language: Addressing ModesDocument24 pagesAssembly Language: Addressing ModesANANYA TRIPATHINo ratings yet
- Chapter 7 Application LayerDocument36 pagesChapter 7 Application LayerT20UBCA027 - Mithuna ShanmugamNo ratings yet
- BCSE I A2 Group CPNM Assignment 3: (Optional)Document2 pagesBCSE I A2 Group CPNM Assignment 3: (Optional)Anurag BandyopadhyayNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- CCC 1Document23 pagesCCC 1Akbar KhanNo ratings yet
- Developing Enterprise Web Services An Architects Guide 0131401602 9780131401600Document606 pagesDeveloping Enterprise Web Services An Architects Guide 0131401602 9780131401600Venkatesan RNo ratings yet
- Smart Plant Monitoring System Using IOTDocument8 pagesSmart Plant Monitoring System Using IOTKshitij BandarNo ratings yet
- AP08-AA9-EV06 Inglés - Presentación Oral - Mi Idea de ProyectoDocument6 pagesAP08-AA9-EV06 Inglés - Presentación Oral - Mi Idea de ProyectoOMORDONo ratings yet
- IASME Governance Question Set (Including Cyber Essentials) - v11c October 2020Document98 pagesIASME Governance Question Set (Including Cyber Essentials) - v11c October 2020Mbang Abdoul KaderNo ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- CD Lab FileDocument28 pagesCD Lab FileAyush MishraNo ratings yet
- MySQL Performance TuningDocument11 pagesMySQL Performance TuningArunmoy BoseNo ratings yet
- DJANGODocument40 pagesDJANGOMohith NakkaNo ratings yet
- How To Install Windows 95 On VMwareDocument72 pagesHow To Install Windows 95 On VMwarepatrserNo ratings yet
- Introducing The PIC32MZ v4.6 (ENG)Document158 pagesIntroducing The PIC32MZ v4.6 (ENG)Andres Bruno SaraviaNo ratings yet
- Electronic Voting System Software Requirements SpecificationDocument14 pagesElectronic Voting System Software Requirements Specificationuser manikandanNo ratings yet
- 11S20017 Satria Armando Pakpahan - Transkip Nilai AkhirDocument1 page11S20017 Satria Armando Pakpahan - Transkip Nilai Akhirputri ayu ManurungNo ratings yet
- Section 1 QuizDocument15 pagesSection 1 QuizDebaszer SonyNo ratings yet
- Introduction To The Iec 61850 Protocol - 2019Document7 pagesIntroduction To The Iec 61850 Protocol - 2019Bradley Da SilvaNo ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)