You might also like
- Web Information RetrievalDocument10 pagesWeb Information RetrievalBaniNo ratings yet
- CT075!3!2 DTM Topic 12 Text Data MiningDocument25 pagesCT075!3!2 DTM Topic 12 Text Data Miningkishanselvarajah80No ratings yet
- Chap 6Document70 pagesChap 6KavithaMaheshNo ratings yet
- Natural Language Processing with Java: Concept Extraction and Sentiment AnalysisDocument51 pagesNatural Language Processing with Java: Concept Extraction and Sentiment AnalysisrexilluminatiNo ratings yet
- Retrieval Models: Boolean and Vector SpaceDocument41 pagesRetrieval Models: Boolean and Vector SpaceaniruddhNo ratings yet
- Business Information Systems Text Retrieval TechniquesDocument23 pagesBusiness Information Systems Text Retrieval TechniquespiccolovegitaNo ratings yet
- Query Languages: Chapter SevenDocument36 pagesQuery Languages: Chapter SevenSooraaNo ratings yet
- Ontologies and the Semantic WebDocument48 pagesOntologies and the Semantic WebNaglaa FathyNo ratings yet
- Information Retrieval: Adt-V UnitDocument106 pagesInformation Retrieval: Adt-V UnitMMCAS SWYAMNo ratings yet
- Business Intelligence and Data Mining TechniquesDocument122 pagesBusiness Intelligence and Data Mining TechniquesAwadhesh YadavNo ratings yet
- How To Do A Literature Search: Andrew Booth (University of Woods (University of Leicester)Document75 pagesHow To Do A Literature Search: Andrew Booth (University of Woods (University of Leicester)swjaffryNo ratings yet
- Semantic Networks: - Approaches To Knowledge Representation - Deductive/logical MethodsDocument8 pagesSemantic Networks: - Approaches To Knowledge Representation - Deductive/logical MethodsArpit AgarwalNo ratings yet
- Chapter 4: Query Languages: Baeza-Yates, 1999 Modern Information RetrievalDocument29 pagesChapter 4: Query Languages: Baeza-Yates, 1999 Modern Information RetrievalTamizharasi ANo ratings yet
- Chapter 4: Query Languages: Baeza-Yates, 1999 Modern Information RetrievalDocument29 pagesChapter 4: Query Languages: Baeza-Yates, 1999 Modern Information RetrievalFarid AzhariNo ratings yet
- Completed Unit II 17.7.17Document113 pagesCompleted Unit II 17.7.17Dr.A.R.KavithaNo ratings yet
- Stec FinalexamDocument17 pagesStec Finalexamapi-283705877No ratings yet
- Info RetrievalDocument14 pagesInfo RetrievalSIDDHINo ratings yet
- Semantic Networks: The Meaning of A Concept Is Defined by Its Relationship To Other ConceptsDocument24 pagesSemantic Networks: The Meaning of A Concept Is Defined by Its Relationship To Other Conceptsakhan10200No ratings yet
- INFO 521: Information Behavior IB Chapter Seven: Information Behavior in Different ContextsDocument31 pagesINFO 521: Information Behavior IB Chapter Seven: Information Behavior in Different ContextsAssegid DestaNo ratings yet
- Introduction of IR ModelsDocument67 pagesIntroduction of IR ModelsMagarsa BedasaNo ratings yet
- FALLSEM2020-21 CSE4022 ETH VL2020210104471 Reference Material III 14-Jul-2020 NLP3-APPLICATIONSLecture 5 6Document101 pagesFALLSEM2020-21 CSE4022 ETH VL2020210104471 Reference Material III 14-Jul-2020 NLP3-APPLICATIONSLecture 5 6SushanNo ratings yet
- Chapter TwoDocument31 pagesChapter TwolatigudataNo ratings yet
- Information Retrieval Systems Information Retrieval SystemsDocument7 pagesInformation Retrieval Systems Information Retrieval SystemsVijay KNo ratings yet
- 2 VS ModelDocument46 pages2 VS ModelGsiangNo ratings yet
- Carlo Pescio - A Physics of Software: An Investigation Into the True Nature of SoftwareDocument11 pagesCarlo Pescio - A Physics of Software: An Investigation Into the True Nature of SoftwareCarlo PescioNo ratings yet
- Introduction of IR ModelsDocument62 pagesIntroduction of IR ModelsMagarsa BedasaNo ratings yet
- Chapter Two Text Operations IntroductionDocument58 pagesChapter Two Text Operations IntroductionS JNo ratings yet
- Information Search and Visualization: - Who Earns $50,000 Among The Residents of Eugene, Oregon?Document9 pagesInformation Search and Visualization: - Who Earns $50,000 Among The Residents of Eugene, Oregon?Sharmili Nukapeyi NNo ratings yet
- CMSC 671 Fall 2005Document28 pagesCMSC 671 Fall 2005NaveedNo ratings yet
- One of The Major Distinctions Between Ordinary Software and AI Is The Need To Represent Domain Knowledge (Or Other Forms of Worldly Knowledge)Document17 pagesOne of The Major Distinctions Between Ordinary Software and AI Is The Need To Represent Domain Knowledge (Or Other Forms of Worldly Knowledge)Engr Ayaz KhanNo ratings yet
- UC Berkeley Full Text Search Using SOLRDocument16 pagesUC Berkeley Full Text Search Using SOLRNavneet SinghNo ratings yet
- Text AnalyticsDocument32 pagesText AnalyticsMahesh RamalingamNo ratings yet
- Keyphrase Extraction (3rd Review)Document22 pagesKeyphrase Extraction (3rd Review)gowtham1990No ratings yet
- СL 7Document20 pagesСL 7haliava haliavaNo ratings yet
- Association Rule Mining With RDocument58 pagesAssociation Rule Mining With Rwirapong chansanamNo ratings yet
- Question Answering System ExplainedDocument31 pagesQuestion Answering System ExplainedIntan WinartiNo ratings yet
- Made By:-Bhawana Agarwal Cs IiiyrDocument29 pagesMade By:-Bhawana Agarwal Cs IiiyrBhawana AgarwalNo ratings yet
- Database: - A Database Is A Collection of Related InformationDocument49 pagesDatabase: - A Database Is A Collection of Related Informationبراء الوكيلNo ratings yet
- Research Designs Using Content AnalysisDocument10 pagesResearch Designs Using Content AnalysisTerry College of BusinessNo ratings yet
- Case Report Form: D CostagliolaDocument32 pagesCase Report Form: D CostagliolaReshma rsrNo ratings yet
- Psyc 224 - Lecture 9Document47 pagesPsyc 224 - Lecture 9Nana Kweku Obeng SakyiNo ratings yet
- Descriptive Morphological Analysis in MontageDocument56 pagesDescriptive Morphological Analysis in MontageFeri Dwi HartantoNo ratings yet
- 2 - Text OperationDocument29 pages2 - Text Operationmaki ababiNo ratings yet
- ILT 101: Internet Search StrategiesDocument18 pagesILT 101: Internet Search StrategiesGeorge AsanteNo ratings yet
- DIT Short Course - Week 1 Webinar SlidesDocument67 pagesDIT Short Course - Week 1 Webinar SlidesRas KONo ratings yet
- Text Mining - Hanmei Fan - Fall 2006Document37 pagesText Mining - Hanmei Fan - Fall 2006Dewi MulyaniNo ratings yet
- Topic 2 - WRITING AN ARTICLE - UBDocument38 pagesTopic 2 - WRITING AN ARTICLE - UBDwi Ayu Siti HartinahNo ratings yet
- Chapter-2 - Automatic Text AnlysisDocument67 pagesChapter-2 - Automatic Text Anlysisabraham getuNo ratings yet
- My Inquiry InfrastructureDocument14 pagesMy Inquiry Infrastructurekarenmcinnes4No ratings yet
- Text AnalyticsDocument51 pagesText Analyticskhatri81No ratings yet
- Introduction To Information RetrievalDocument50 pagesIntroduction To Information RetrievalasmaNo ratings yet
- Chapter 1 Introduction To ISRDocument39 pagesChapter 1 Introduction To ISRAaron MelendezNo ratings yet
- 1 IR IntroductionDocument23 pages1 IR IntroductionMulugeta HailuNo ratings yet
- AI Lecture on FOL Knowledge EngineeringDocument32 pagesAI Lecture on FOL Knowledge EngineeringHàssáñ YàsèéñNo ratings yet
- IR UNIT I - NotesDocument23 pagesIR UNIT I - NotesAngelNo ratings yet
- How to effectively search for research materialsDocument9 pagesHow to effectively search for research materialsIrwin HentriansaNo ratings yet
- UNIT 5 - Information ExtractionDocument14 pagesUNIT 5 - Information Extraction20bq1a4213No ratings yet
- 1-Getting Started With ELKDocument44 pages1-Getting Started With ELKMariem El MechryNo ratings yet
- Agenda: - Introduction - Basics - Classification - Clustering - Regression - Use-CasesDocument30 pagesAgenda: - Introduction - Basics - Classification - Clustering - Regression - Use-CasesAmeer MuhammadNo ratings yet
- Selecting and Implementing an Integrated Library System: The Most Important Decision You Will Ever MakeFrom EverandSelecting and Implementing an Integrated Library System: The Most Important Decision You Will Ever MakeNo ratings yet
- System CallDocument24 pagesSystem CallShefali DsouzaNo ratings yet
- Database Mirroring Vs Log - 123456Document2 pagesDatabase Mirroring Vs Log - 123456Praveen Kumar MadupuNo ratings yet
- CS403 Assignment 3 Solution Fall 2022 by VU AnswerDocument7 pagesCS403 Assignment 3 Solution Fall 2022 by VU AnswerZeeNo ratings yet
- QXZF - Ex27373 - Fire Pump Motors - UL Product IQDocument2 pagesQXZF - Ex27373 - Fire Pump Motors - UL Product IQCarlos Andres Neira Agudelo100% (1)
- Examples of Data Flow Diagrams PDFDocument2 pagesExamples of Data Flow Diagrams PDFKaren100% (1)
- Mizanur Islam Project ReportDocument59 pagesMizanur Islam Project ReportMizanur AlrasidNo ratings yet
- Java 6 JDBC and Database Applications PDFDocument185 pagesJava 6 JDBC and Database Applications PDFThe Underrated artistsNo ratings yet
- How To Diagnose E-Business Tax Issues in Procurement - Doc ID 728906.1Document10 pagesHow To Diagnose E-Business Tax Issues in Procurement - Doc ID 728906.1Nauman KhalidNo ratings yet
- One-Copy Serializability With Snapshot Isolation Under The HoodDocument12 pagesOne-Copy Serializability With Snapshot Isolation Under The HoodTewei Robert LuoNo ratings yet
- OBIEE Usage TrackingDocument35 pagesOBIEE Usage TrackingnaveenpavuluriNo ratings yet
- Module 16 - Backup and RecoveryDocument48 pagesModule 16 - Backup and RecoveryAnonymous 8RhRm6Eo7hNo ratings yet
- WCOB Dillard's Data Model and Data Dictionary OverviewDocument5 pagesWCOB Dillard's Data Model and Data Dictionary OverviewYuqing LUNo ratings yet
- Hands On 3.1 ActDocument7 pagesHands On 3.1 Actmarkkyle collantesNo ratings yet
- Questions and Answers in SQLDocument24 pagesQuestions and Answers in SQLابوالحروف العربي ابوالحروفNo ratings yet
- As ISO IEC 11179.3-2005 Information Technology - Metadata Registries (MDR) Registry Metamodel and Basic AttriDocument11 pagesAs ISO IEC 11179.3-2005 Information Technology - Metadata Registries (MDR) Registry Metamodel and Basic AttriSAI Global - APACNo ratings yet
- Cheat Sheet v2Document1 pageCheat Sheet v2Gilco333No ratings yet
- Ict SPM Learning Area 6 NoteDocument14 pagesIct SPM Learning Area 6 NoteAlin AmzanNo ratings yet
- BI Upgrade Series ChangesDocument20 pagesBI Upgrade Series Changesy2kmvrNo ratings yet
- DWM Unit 2. Data Warehousing Modeling & OLAP IDocument16 pagesDWM Unit 2. Data Warehousing Modeling & OLAP Ijemsbonnd100% (1)
- 1Z0 060Document142 pages1Z0 060Srinivas Ellendula50% (2)
- Top 10 Best Practices For SQL Server Maintenance For SAPDocument4 pagesTop 10 Best Practices For SQL Server Maintenance For SAPCiber KataNo ratings yet
- DBMS UNIT 2 NotesDocument7 pagesDBMS UNIT 2 NotesKrishnaNo ratings yet
- Data Science Learning Map: Build ExpertiseDocument1 pageData Science Learning Map: Build Expertisesid202pkNo ratings yet
- The Entity-Relationship ModelDocument15 pagesThe Entity-Relationship ModelCherry PepitoNo ratings yet
- Cycle Sheet 3 Queries Involving Joins, Aggregate, Group By-Having, Any, All, at Least, at Most Exactly, Except, in Not in FunctionsDocument13 pagesCycle Sheet 3 Queries Involving Joins, Aggregate, Group By-Having, Any, All, at Least, at Most Exactly, Except, in Not in Functionssangam raiNo ratings yet
- SQL Injection: Prof. Kirtankumar Rathod Dept. of Computer Science ISHLS, Indus UniversityDocument13 pagesSQL Injection: Prof. Kirtankumar Rathod Dept. of Computer Science ISHLS, Indus Universitykirtan71No ratings yet
- Introduction To SQLDocument34 pagesIntroduction To SQLcleophacerevivalNo ratings yet
- Big Data Review Paper Ijariie13560 PDFDocument7 pagesBig Data Review Paper Ijariie13560 PDFbcadeptNo ratings yet
- D11299GC21 TocDocument14 pagesD11299GC21 TocRapid ChaseNo ratings yet
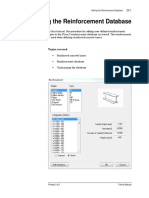
- Tutorial 25 Reinforcement DatabaseDocument9 pagesTutorial 25 Reinforcement DatabaseBilal AlpaydınNo ratings yet