You might also like
- System Design - Sequencer - Grokking Modern System Design Interview For Engineers & ManagersDocument1 pageSystem Design - Sequencer - Grokking Modern System Design Interview For Engineers & Managerspmprepkp0% (2)
- CMS Documentation FinalDocument66 pagesCMS Documentation FinalBethelhem Yetwale100% (1)
- SAP interface programming with RFC and VBA: Edit SAP data with MS AccessFrom EverandSAP interface programming with RFC and VBA: Edit SAP data with MS AccessNo ratings yet
- Certified Cloud Practitoner CheatSheetDocument16 pagesCertified Cloud Practitoner CheatSheetErick EspinozaNo ratings yet
- Parallel & Distributed ComputingDocument52 pagesParallel & Distributed ComputinglitbumreaderNo ratings yet
- Dokumen - Pub Windows Kernel Programming 9798379069513Document618 pagesDokumen - Pub Windows Kernel Programming 9798379069513dukeNo ratings yet
- OWASP The Application Security Help DeskDocument598 pagesOWASP The Application Security Help Desksomendas100% (1)
- Design of Modern Distributed Systems Based On Microservices ArchitectureDocument8 pagesDesign of Modern Distributed Systems Based On Microservices ArchitectureСветлана ПереяславскаяNo ratings yet
- Parallel Programming, Mapreduce Model: Unit IiDocument47 pagesParallel Programming, Mapreduce Model: Unit IiDarpan PalodaNo ratings yet
- Lecture 10 MapReduce HadoopDocument37 pagesLecture 10 MapReduce HadoopDAVID HUMBERTO GUTIERREZ MARTINEZNo ratings yet
- Paper Summary - MapReduce - Simplified Data Processing On Large Clusters (2004) - MeloSpaceDocument7 pagesPaper Summary - MapReduce - Simplified Data Processing On Large Clusters (2004) - MeloSpaceEdwardNo ratings yet
- Unit-2 bda kalyan_pagenumberDocument15 pagesUnit-2 bda kalyan_pagenumberrohit sai tech viewersNo ratings yet
- Unit 3 - Big Data TechnologiesDocument42 pagesUnit 3 - Big Data Technologiesprakash NNo ratings yet
- Google MapReduce FrameworkDocument27 pagesGoogle MapReduce FrameworkRadhamani VNo ratings yet
- Chapter 3MapReduceDocument30 pagesChapter 3MapReduceKomalNo ratings yet
- Unit 4 DaDocument57 pagesUnit 4 Daaadityapawar210138No ratings yet
- Mapreduce: Simpli - Ed Data Processing On Large ClustersDocument4 pagesMapreduce: Simpli - Ed Data Processing On Large ClustersIbrahim HamzaNo ratings yet
- Hadoop Interview Questions FaqDocument14 pagesHadoop Interview Questions FaqmihirhotaNo ratings yet
- What Is MapReduceDocument6 pagesWhat Is MapReduceSundaram yadavNo ratings yet
- Distributed and Cloud ComputingDocument58 pagesDistributed and Cloud Computing18JE0254 CHIRAG JAINNo ratings yet
- 3.6 Backup Tasks 4.2 Ordering Guarantees: To Appear in OSDI 2004Document1 page3.6 Backup Tasks 4.2 Ordering Guarantees: To Appear in OSDI 2004p001No ratings yet
- Survey Paper On Traditional Hadoop and Pipelined Map Reduce: Dhole Poonam B, Gunjal Baisa LDocument5 pagesSurvey Paper On Traditional Hadoop and Pipelined Map Reduce: Dhole Poonam B, Gunjal Baisa LInternational Journal of computational Engineering research (IJCER)No ratings yet
- What is MapReduceDocument5 pagesWhat is MapReduceAnjali AdwaniNo ratings yet
- Map ReduceDocument25 pagesMap ReduceahmadroheedNo ratings yet
- Dean 08 Map ReduceDocument7 pagesDean 08 Map ReduceLindsey HoffmanNo ratings yet
- Take A Close Look At: Ma EdDocument42 pagesTake A Close Look At: Ma EdAbhishek RanjanNo ratings yet
- MapReduce OnlineDocument15 pagesMapReduce OnlineVyhxNo ratings yet
- Hadoop Interview Questions Author: Pappupass Learning ResourceDocument16 pagesHadoop Interview Questions Author: Pappupass Learning ResourceDheeraj ReddyNo ratings yet
- Module 3 - MapreduceDocument40 pagesModule 3 - MapreduceAditya RajNo ratings yet
- Chapter 05 Google ReDocument69 pagesChapter 05 Google ReWilliamNo ratings yet
- Hadoop (Mapreduce)Document43 pagesHadoop (Mapreduce)Nisrine MofakirNo ratings yet
- How Hadoop Record Readers Convert Data into Key-Value PairsDocument26 pagesHow Hadoop Record Readers Convert Data into Key-Value PairsLakshayjeet swamiNo ratings yet
- How MapReduce in Hadoop Works: A Step-by-Step GuideDocument5 pagesHow MapReduce in Hadoop Works: A Step-by-Step GuideRakesh ShawNo ratings yet
- BDA-MapReduce (1) 5rfgy656yhgvcft6Document60 pagesBDA-MapReduce (1) 5rfgy656yhgvcft6Ayush JhaNo ratings yet
- 201070046_BDA_03Document10 pages201070046_BDA_03HARSH NAGNo ratings yet
- New Microsoft Office Word DocumentDocument10 pagesNew Microsoft Office Word Documentpooja poohNo ratings yet
- Term Paper JavaDocument14 pagesTerm Paper JavaMuskan BhartiNo ratings yet
- BDA Unit 3 NotesDocument11 pagesBDA Unit 3 NotesduraisamyNo ratings yet
- Top Answers To Map Reduce Interview QuestionsDocument6 pagesTop Answers To Map Reduce Interview QuestionsEjaz AlamNo ratings yet
- System Design and Implementation 5.1 System DesignDocument14 pagesSystem Design and Implementation 5.1 System DesignsararajeeNo ratings yet
- Assignment 11 DSBDADocument4 pagesAssignment 11 DSBDADARSHAN JADHAVNo ratings yet
- Parameterized Pipelined Map Reduce Based Approach For Performance Improvement of Parallel Programming ModelDocument5 pagesParameterized Pipelined Map Reduce Based Approach For Performance Improvement of Parallel Programming ModelKavita RahaneNo ratings yet
- MapReduce: Simplified Data Processing On Large ClustersDocument13 pagesMapReduce: Simplified Data Processing On Large Clusterszzztimbo100% (1)
- Unit 3 BbaDocument11 pagesUnit 3 Bbarajendrameena172003No ratings yet
- Data Science PresentationDocument20 pagesData Science Presentationyadvendra dhakadNo ratings yet
- Chapter 4 - Understanding Map Reduce FundamentalsDocument45 pagesChapter 4 - Understanding Map Reduce FundamentalsWEGENE ARGOWNo ratings yet
- 3a - MapReduce Data Flow Scheduling Combiner Partitioner PDFDocument22 pages3a - MapReduce Data Flow Scheduling Combiner Partitioner PDF23522020 Danendra Athallariq Harya PNo ratings yet
- Map ReduceDocument18 pagesMap ReduceSoni NsitNo ratings yet
- 03 Firstmrjob Invertedindexconstruction 141206231216 Conversion Gate01 PDFDocument54 pages03 Firstmrjob Invertedindexconstruction 141206231216 Conversion Gate01 PDFVignesh SrinivasanNo ratings yet
- Resumo MapReduce YARNDocument13 pagesResumo MapReduce YARNThiago SiqueiraNo ratings yet
- Unit 2 - From Hadoop Streaming PDFDocument20 pagesUnit 2 - From Hadoop Streaming PDFGopal AgarwalNo ratings yet
- Mapreduce and Hadoop EcosystemDocument64 pagesMapreduce and Hadoop EcosystemRin Rin NurmalasariNo ratings yet
- What Is MapReduce ProcessDocument3 pagesWhat Is MapReduce ProcessPam G.No ratings yet
- Map-Reduce Is A Programming Model That Is Mainly Divided Into TwoDocument2 pagesMap-Reduce Is A Programming Model That Is Mainly Divided Into TwoFahim MuntasirNo ratings yet
- Hadoop KaruneshDocument14 pagesHadoop KaruneshMukul MishraNo ratings yet
- Map ReduceDocument36 pagesMap ReducePapai RanaNo ratings yet
- Lecture 3 MapReduce SparkDocument62 pagesLecture 3 MapReduce Sparkchenna kesavaNo ratings yet
- 7 Full Hadoop Performance Modeling For Job Estimation and Resource ProvisioningDocument94 pages7 Full Hadoop Performance Modeling For Job Estimation and Resource ProvisioningarunkumarNo ratings yet
- CCD-333 Exam TutorialDocument20 pagesCCD-333 Exam TutorialMohammed Haleem SNo ratings yet
- CS-702 (D) BigDataDocument61 pagesCS-702 (D) BigDatagarima bhNo ratings yet
- Bda - 3 UnitDocument18 pagesBda - 3 UnitASMA UL HUSNANo ratings yet
- Map Reduce ProgrammingDocument21 pagesMap Reduce ProgrammingSachin PukaleNo ratings yet
- Axia Actor Dev GuideDocument54 pagesAxia Actor Dev GuiderhshrivaNo ratings yet
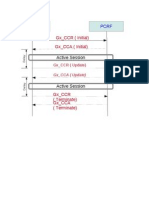
- Call FlowDocument1 pageCall FlowrhshrivaNo ratings yet
- Featherstitch Sosp07Document14 pagesFeatherstitch Sosp07rhshrivaNo ratings yet
- ZCS Appliance Installation GuideDocument6 pagesZCS Appliance Installation GuiderhshrivaNo ratings yet
- Cs 162 All SlidesDocument233 pagesCs 162 All SlidesrhshrivaNo ratings yet
- Database Management SystemDocument46 pagesDatabase Management SystemRohit KumarNo ratings yet
- (NEW) Sap Abap MCQDocument12 pages(NEW) Sap Abap MCQHimanshi SainiNo ratings yet
- Software Testing Assignment 2Document4 pagesSoftware Testing Assignment 22K17CO13 ABHISHEK JAYANTNo ratings yet
- A Interview Questions On SQL TransformationDocument13 pagesA Interview Questions On SQL TransformationseenaranjithNo ratings yet
- Chapter 3 - Describing Syntax and Semantics: CS-4337 Organization of Programming LanguagesDocument58 pagesChapter 3 - Describing Syntax and Semantics: CS-4337 Organization of Programming LanguageslimenihNo ratings yet
- Testing The Software With X-Ray GlassesDocument23 pagesTesting The Software With X-Ray Glassesmuhammad umairNo ratings yet
- Javascript Exercises, Algorithms Practice, and Mock InterviewsDocument2 pagesJavascript Exercises, Algorithms Practice, and Mock InterviewsnfreedNo ratings yet
- Python FunctionsDocument10 pagesPython Functionsimaad8888No ratings yet
- Android Intent & Layout GuideDocument19 pagesAndroid Intent & Layout GuideKiyotaka AyanakoujiNo ratings yet
- 8-Function ALU Design Using Case StatementDocument11 pages8-Function ALU Design Using Case StatementAahnaf Mustafiz 1631698043No ratings yet
- 8086 Game ProjectDocument8 pages8086 Game Projectpatel_savan28No ratings yet
- B.Sc. Final Project Report Format: Chapters 1Document2 pagesB.Sc. Final Project Report Format: Chapters 1J A Y T R O NNo ratings yet
- Creating A Simple Android App With 2 Buttons: Two Button Application Use CaseDocument8 pagesCreating A Simple Android App With 2 Buttons: Two Button Application Use CaseRazzy RazzNo ratings yet
- What Is HTML?: ContentDocument5 pagesWhat Is HTML?: ContentДушко ПоповићNo ratings yet
- Multiple RDP (Remote Desktop) Sessions in Windows 10Document1 pageMultiple RDP (Remote Desktop) Sessions in Windows 10neycrochaNo ratings yet
- DBus Client Log File Tracking Telemetry Plugin UpdateDocument9 pagesDBus Client Log File Tracking Telemetry Plugin UpdateȘtefan și MateiNo ratings yet
- Uplers ORT Remote Teams USDocument39 pagesUplers ORT Remote Teams USVidhyaRIyengarNo ratings yet
- NASA software tool for space mission design and analysisDocument8 pagesNASA software tool for space mission design and analysisFrancisco CarvalhoNo ratings yet
- Apache Tika API Usage ExamplesDocument6 pagesApache Tika API Usage ExamplesneergttocsdivadNo ratings yet
- Software License Agreement AppendixDocument22 pagesSoftware License Agreement AppendixIstván FodorNo ratings yet
- PL/SQL: Stored Procedures, Functions, Cursors, Triggers and MoreDocument142 pagesPL/SQL: Stored Procedures, Functions, Cursors, Triggers and MoreYUVRAJ SHARMANo ratings yet
- 33 Steps To Great PresentationDocument27 pages33 Steps To Great Presentationsanky08No ratings yet
- PI REST Adapter - Connect To ConcurDocument7 pagesPI REST Adapter - Connect To Concurprn1008No ratings yet
- Familiarity With SuricataDocument20 pagesFamiliarity With SuricataPrashanth VermaNo ratings yet