You might also like
- Covariance and Correlation Class 7, 18.05 Jeremy Orloff and Jonathan BloomDocument9 pagesCovariance and Correlation Class 7, 18.05 Jeremy Orloff and Jonathan BloomHofidisNo ratings yet
- Cov(X,Y) can be 0 even if X and Y are dependentDocument2 pagesCov(X,Y) can be 0 even if X and Y are dependentSpin FotonioNo ratings yet
- ExpectationDocument19 pagesExpectationShah FahadNo ratings yet
- Classical Linear Regression and Its AssumptionsDocument63 pagesClassical Linear Regression and Its AssumptionsBangura Abdulai FNo ratings yet
- Statistics Boot Camp: X F X X E DX X XF X E Important Properties of The Expectations OperatorDocument3 pagesStatistics Boot Camp: X F X X E DX X XF X E Important Properties of The Expectations OperatorHerard NapuecasNo ratings yet
- Exam Sample ProblemsDocument2 pagesExam Sample ProblemsJoanna MatysiakNo ratings yet
- Handout5 Extra On CovarianceDocument1 pageHandout5 Extra On Covarianceozo1996No ratings yet
- Covariance & Correlation 1Document2 pagesCovariance & Correlation 1param_emailNo ratings yet
- Introductory Econometrics: Solutions of Selected Exercises From Tutorial 1Document2 pagesIntroductory Econometrics: Solutions of Selected Exercises From Tutorial 1armailgm100% (1)
- Sum of VariancesDocument11 pagesSum of VariancesfembemNo ratings yet
- Final Homework, Due May 3 (Returned May 8) :: F X e XDocument2 pagesFinal Homework, Due May 3 (Returned May 8) :: F X e XYusuf HusseinNo ratings yet
- Chapter 5Document45 pagesChapter 5api-3729261No ratings yet
- ProbstatDocument16 pagesProbstatShreetama BhattacharyaNo ratings yet
- Lecture 2Document15 pagesLecture 2satyabashaNo ratings yet
- HW5 Solutions: X y X, YDocument5 pagesHW5 Solutions: X y X, YAnurag TiwariNo ratings yet
- Joint Probability Distributions GuideDocument47 pagesJoint Probability Distributions GuideKiel JohnNo ratings yet
- Lecture 7Document6 pagesLecture 7Agha Zeeshan Khan SoomroNo ratings yet
- Covariance and Some Conditional Expectation Exercises: Scott She EldDocument17 pagesCovariance and Some Conditional Expectation Exercises: Scott She EldzahiruddinNo ratings yet
- Entropy, Relative Entropy and Mutual InformationDocument4 pagesEntropy, Relative Entropy and Mutual InformationamoswengerNo ratings yet
- Lab 7 BDocument7 pagesLab 7 Bapi-3826899No ratings yet
- Random Variables: - Definition of Random VariableDocument29 pagesRandom Variables: - Definition of Random Variabletomk2220No ratings yet
- Estimators1 PDFDocument2 pagesEstimators1 PDFHiinoNo ratings yet
- STAT 211 Joint Probability Distributions and Random Samples: Handout 5 (Chapter 5)Document6 pagesSTAT 211 Joint Probability Distributions and Random Samples: Handout 5 (Chapter 5)Mazhar AliNo ratings yet
- 11 - Queing Theory Part 1Document31 pages11 - Queing Theory Part 1sairamNo ratings yet
- SSP4SE AppaDocument10 pagesSSP4SE AppaÖzkan KaleNo ratings yet
- 4404 Notes ATVDocument6 pages4404 Notes ATVSudeep RajaNo ratings yet
- Variance, Covariance & CorrelationDocument5 pagesVariance, Covariance & Correlationtb1189No ratings yet
- ISI MStat 06Document5 pagesISI MStat 06api-26401608No ratings yet
- Advanced Econometrics I - OLS EstimationDocument42 pagesAdvanced Econometrics I - OLS EstimationVivi EnneNo ratings yet
- 11 Stat PrelimDocument6 pages11 Stat PrelimLucas PiroulusNo ratings yet
- L-10 Expectation & Variance PDFDocument34 pagesL-10 Expectation & Variance PDFSyed Md. Affanul Karim ShouravNo ratings yet
- Covariance, Correlation, and Regression LectureDocument11 pagesCovariance, Correlation, and Regression LectureEmerson ButynNo ratings yet
- Sample Statistics ExplainedDocument13 pagesSample Statistics Explainedpurbita boseNo ratings yet
- Lecture 21Document30 pagesLecture 21Saumitra PandeyNo ratings yet
- 5 Prob - OverviewDocument10 pages5 Prob - OverviewRinnapat LertsakkongkulNo ratings yet
- STAT2011 2017 Exam Formulae PDFDocument3 pagesSTAT2011 2017 Exam Formulae PDFeccentricftw4No ratings yet
- Random Variable Modified PDFDocument19 pagesRandom Variable Modified PDFIMdad HaqueNo ratings yet
- Content - The Mean and Variance of - ( - Bar (X) - )Document4 pagesContent - The Mean and Variance of - ( - Bar (X) - )ScarfaceXXXNo ratings yet
- Queing Theory 2023-24Document40 pagesQueing Theory 2023-24Sakiya PNo ratings yet
- Ordinal and Nominal ExampplesDocument7 pagesOrdinal and Nominal ExampplesAadilNo ratings yet
- Probability SlidesDocument12 pagesProbability Slidesyooga palanisamyNo ratings yet
- JG NoteDocument8 pagesJG NoteSakshi ChavanNo ratings yet
- Tutsheet 4Document2 pagesTutsheet 4vishnuNo ratings yet
- Engineering Differential Privacy BackgroundDocument4 pagesEngineering Differential Privacy BackgroundXZxzASNo ratings yet
- Covariances: C Ov (X, Y)Document8 pagesCovariances: C Ov (X, Y)davidNo ratings yet
- Expectations: Proposition 12.1Document11 pagesExpectations: Proposition 12.1Sneha nairNo ratings yet
- ENGDAT1 Module4 PDFDocument32 pagesENGDAT1 Module4 PDFLawrence BelloNo ratings yet
- Regression Model AssumptionsDocument50 pagesRegression Model AssumptionsEthiop LyricsNo ratings yet
- Fundamentals of Probability: Solutions To Self-Quizzes and Self-TestsDocument15 pagesFundamentals of Probability: Solutions To Self-Quizzes and Self-TestsRaul Santillana QuispeNo ratings yet
- Sol 12Document4 pagesSol 12entertainment worldNo ratings yet
- Comparing Risk PreferencesDocument24 pagesComparing Risk PreferencesMarwan MonajjedNo ratings yet
- Multivariate Normal DistributionDocument8 pagesMultivariate Normal DistributionBrassica JunceaNo ratings yet
- Parameter EstimationDocument34 pagesParameter EstimationJose Leonardo Simancas GarciaNo ratings yet
- Probability (Merged)Document39 pagesProbability (Merged)Nilanjan KunduNo ratings yet
- HW1 SolutionsDocument9 pagesHW1 SolutionsAntonNo ratings yet
- MStat PSB 2016Document5 pagesMStat PSB 2016SOUMYADEEP GOPENo ratings yet
- Econ2280 Tutorial 1 Review Notes PDFDocument4 pagesEcon2280 Tutorial 1 Review Notes PDFKelvin ChanNo ratings yet
- Covariance and Some Conditional Expectation Exercises: Scott SheffieldDocument69 pagesCovariance and Some Conditional Expectation Exercises: Scott SheffieldEd ZNo ratings yet
- Mathematics 1St First Order Linear Differential Equations 2Nd Second Order Linear Differential Equations Laplace Fourier Bessel MathematicsFrom EverandMathematics 1St First Order Linear Differential Equations 2Nd Second Order Linear Differential Equations Laplace Fourier Bessel MathematicsNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- Machine learning methods identify and classify toxic commentsDocument5 pagesMachine learning methods identify and classify toxic commentsAnh Đinh ViệtNo ratings yet
- Listening Handout 5Document4 pagesListening Handout 5Anh Đinh ViệtNo ratings yet
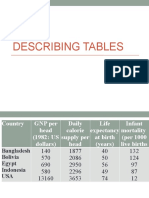
- Tables IeltsDocument6 pagesTables IeltsAnh Đinh ViệtNo ratings yet
- Iso-Based Models To Measure Software Product QualityDocument29 pagesIso-Based Models To Measure Software Product QualityAnh Đinh ViệtNo ratings yet
- Lecture 1: Signal: Signal and System Multiple-Choice Questions and LibraryDocument1 pageLecture 1: Signal: Signal and System Multiple-Choice Questions and LibraryAnh Đinh ViệtNo ratings yet
- GE4 Schedule IELTS PreparationDocument14 pagesGE4 Schedule IELTS PreparationAnh Đinh ViệtNo ratings yet
- HW04Document5 pagesHW04Zunaash Rasheed0% (1)
- RUP Best PracticesDocument21 pagesRUP Best PracticesJohana Cevallos100% (17)
- E-Government in Developing Countries: Experiences From Sub-Saharan AfricaDocument11 pagesE-Government in Developing Countries: Experiences From Sub-Saharan AfricaMashael AzizNo ratings yet
- History of US Medical Device RegulationDocument7 pagesHistory of US Medical Device RegulationHector Tinoco GarciaNo ratings yet
- FDA 510(k) Clearance for Withings Scan Monitor ECG & Pulse OximeterDocument7 pagesFDA 510(k) Clearance for Withings Scan Monitor ECG & Pulse OximeterfofikoNo ratings yet
- Encyclopedia of Big Data PDFDocument338 pagesEncyclopedia of Big Data PDFAmit Singh0% (1)
- Kumba Resources: Case StudiesDocument12 pagesKumba Resources: Case StudiesAdnan PitafiNo ratings yet
- Final Project at NucsoftDocument97 pagesFinal Project at NucsoftmainasshettyNo ratings yet
- Lloyds Register - Future IMO Legislation (August 2013)Document0 pagesLloyds Register - Future IMO Legislation (August 2013)metallourgosNo ratings yet
- Form 16 - IT DEPT Part A - 20202021Document2 pagesForm 16 - IT DEPT Part A - 20202021Kritansh BindalNo ratings yet
- Chapter 1Document18 pagesChapter 1Tabassum AkhtarNo ratings yet
- Lim Tong Lim v. Philippine Fishing Gear Industries IncDocument2 pagesLim Tong Lim v. Philippine Fishing Gear Industries IncIhna Alyssa Marie SantosNo ratings yet
- Chapter02-Processes and ThreadsDocument74 pagesChapter02-Processes and Threads13 - Nguyễn Thành AnNo ratings yet
- United States Bankruptcy Court Eastern District of Michigan Southern DivisionDocument14 pagesUnited States Bankruptcy Court Eastern District of Michigan Southern DivisionChapter 11 DocketsNo ratings yet
- TBDL 4Document3 pagesTBDL 4Dicimulacion, Angelica P.No ratings yet
- Orthopaedic BiomechanicsDocument17 pagesOrthopaedic BiomechanicsIacobescu EmiliaNo ratings yet
- Field Experience B Principal Interview DardenDocument3 pagesField Experience B Principal Interview Dardenapi-515615857No ratings yet
- P55-3 Rvge-17 PDFDocument4 pagesP55-3 Rvge-17 PDFMARCONo ratings yet
- Aging EssayDocument1 pageAging EssayAlexander DavadillaNo ratings yet
- DB858DG90ESYDocument3 pagesDB858DG90ESYОлександр ЧугайNo ratings yet
- MicroPHAZIR User ManualDocument47 pagesMicroPHAZIR User ManualAlejandro RomeroNo ratings yet
- 11 M-Way Search TreesDocument33 pages11 M-Way Search TreesguptharishNo ratings yet
- Production Part Approval Process: Fourth EditionDocument5 pagesProduction Part Approval Process: Fourth Editiontanya67% (3)
- Why Coolant Plays a Critical Role in Engine LongevityDocument57 pagesWhy Coolant Plays a Critical Role in Engine LongevityPETER ADAMNo ratings yet
- My Little Pony: Friendship Is Magic #14 PreviewDocument10 pagesMy Little Pony: Friendship Is Magic #14 PreviewGraphic Policy100% (3)
- Topic 2Document9 pagesTopic 2swathi thotaNo ratings yet
- DocumentDocument11 pagesDocumentKHIEZZIER GHEN LLANTADANo ratings yet
- Joukowski Airfoil in Potential Flow Without Complex Numbers PDFDocument110 pagesJoukowski Airfoil in Potential Flow Without Complex Numbers PDFChacho BacoaNo ratings yet
- Computer MCQ NotesDocument88 pagesComputer MCQ NotesWaqas AliNo ratings yet
- Essay On Causes of Corruption and Its RemediesDocument30 pagesEssay On Causes of Corruption and Its Remediesanoos04100% (2)
- JokeDocument164 pagesJoketarinitwrNo ratings yet
- Improve Your Well-Being With The Wheel Of Life ExerciseDocument2 pagesImprove Your Well-Being With The Wheel Of Life ExerciseLINA PASSIONNo ratings yet