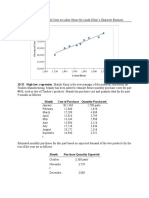
You might also like
- Navidi ch5Document54 pagesNavidi ch5sanaa.aitNo ratings yet
- 7.confidence IntervalsDocument13 pages7.confidence Intervalschikutyerejoice1623No ratings yet
- Bus 173 - 1Document28 pagesBus 173 - 1Mirza Asir IntesarNo ratings yet
- Navidi ch5Document34 pagesNavidi ch5binoNo ratings yet
- EstimationDocument44 pagesEstimationMarvin C. NarvaezNo ratings yet
- Chapter 8 Confidence IntervalDocument14 pagesChapter 8 Confidence IntervalFadli Bakhtiar AjiNo ratings yet
- 03 Chapter 3 - Statistical EstimationDocument17 pages03 Chapter 3 - Statistical EstimationYohanna SisayNo ratings yet
- Business Statistics Estimates and Confidence IntervalsDocument63 pagesBusiness Statistics Estimates and Confidence Intervalspkj009No ratings yet
- Confidence IntervalDocument27 pagesConfidence IntervalJay Menon100% (3)
- BSCHAPTER - (Theory of Estimations)Document39 pagesBSCHAPTER - (Theory of Estimations)kunal kabraNo ratings yet
- 4estimation and Hypothesis Testing (DB) (Compatibility Mode)Document170 pages4estimation and Hypothesis Testing (DB) (Compatibility Mode)Mekonnen BatiNo ratings yet
- Interval EstimationDocument30 pagesInterval Estimationsai revanthNo ratings yet
- Chapter 3Document40 pagesChapter 3allahgodallah1992No ratings yet
- Sampling Distributions and Confidence Intervals For ProportionsDocument31 pagesSampling Distributions and Confidence Intervals For ProportionsJosh PotashNo ratings yet
- Estimation of Population Means: Point Estimation and Confidence IntervalDocument26 pagesEstimation of Population Means: Point Estimation and Confidence IntervalBlackstarNo ratings yet
- The Design of Research: Mcgraw-Hill/IrwinDocument33 pagesThe Design of Research: Mcgraw-Hill/IrwinnehaarunagarwalNo ratings yet
- 9 16042019Document45 pages9 16042019محمد خيري بن اسماءيلNo ratings yet
- Materi 4 Estimasi Titik Dan Interval-EditDocument73 pagesMateri 4 Estimasi Titik Dan Interval-EditHendra SamanthaNo ratings yet
- Calculate Confidence Intervals for Population MeansDocument37 pagesCalculate Confidence Intervals for Population MeansJoey ShackelfordNo ratings yet
- The Normal Distribution Estimation CorrelationDocument16 pagesThe Normal Distribution Estimation Correlationjhamlene2528No ratings yet
- Confidence Interval For MeansDocument37 pagesConfidence Interval For Meansjuvy castroNo ratings yet
- BRM - Lesson7 Confidence IntervalDocument17 pagesBRM - Lesson7 Confidence IntervalFengChenNo ratings yet
- Chapter Two Fundamentals of Marketing Estimation and Hypothesis TestingDocument73 pagesChapter Two Fundamentals of Marketing Estimation and Hypothesis Testingshimelis adugnaNo ratings yet
- Estimation 1920Document51 pagesEstimation 1920Marvin C. NarvaezNo ratings yet
- Estimating Sample SizeDocument24 pagesEstimating Sample SizeShaira CaballesNo ratings yet
- Estimation MethodsDocument60 pagesEstimation MethodsBehar AbdurahemanNo ratings yet
- APPLIED ENVIRONMENTAL STATISTICSDocument35 pagesAPPLIED ENVIRONMENTAL STATISTICSMawuliNo ratings yet
- Binomial Distributions For Sample CountsDocument38 pagesBinomial Distributions For Sample CountsVishnu VenugopalNo ratings yet
- Lecture 4 Estimating From A Sample Sample Mean and Confidence Intervals Upload 2Document22 pagesLecture 4 Estimating From A Sample Sample Mean and Confidence Intervals Upload 2mussy001No ratings yet
- Confidence Intervals for the MeanDocument39 pagesConfidence Intervals for the MeanMarco TungNo ratings yet
- Lecture 24 PDFDocument12 pagesLecture 24 PDFAnonymous 7HfJimvNo ratings yet
- Statistical InferenceDocument33 pagesStatistical Inferencedeneke100% (1)
- IntervalsDocument43 pagesIntervalsHarySetiyawanNo ratings yet
- W6 Lecture6Document20 pagesW6 Lecture6Thi Nam PhạmNo ratings yet
- Chapter 8Document15 pagesChapter 8Phước NgọcNo ratings yet
- Ch08 - Large-Sample EstimationDocument28 pagesCh08 - Large-Sample EstimationislamNo ratings yet
- Statistical Inference: EstimationDocument24 pagesStatistical Inference: EstimationAdel KaadanNo ratings yet
- Chap 8 More About MeansDocument50 pagesChap 8 More About MeansMbusoThabetheNo ratings yet
- Confidence IntervalsDocument42 pagesConfidence IntervalsBlendie V. Quiban Jr.100% (1)
- Confidence Interval Estimation for Unknown Population MeanDocument20 pagesConfidence Interval Estimation for Unknown Population MeanSyed M MusslimNo ratings yet
- Week 6.8a With NotesDocument35 pagesWeek 6.8a With NotesL RNo ratings yet
- Chapter 9Document22 pagesChapter 9Yazan Abu khaledNo ratings yet
- Lecture (Chapter 7) : Estimation Procedures: Ernesto F. L. AmaralDocument33 pagesLecture (Chapter 7) : Estimation Procedures: Ernesto F. L. AmaralMarvin Yebes ArceNo ratings yet
- Chapter 1Document24 pagesChapter 1Luqman X AidilNo ratings yet
- Interval Estimation: ASW, Chapter 8Document23 pagesInterval Estimation: ASW, Chapter 8justinepaz1984No ratings yet
- Module 2 - Lesson 4 & 5_with soln (1)Document25 pagesModule 2 - Lesson 4 & 5_with soln (1)ALLEIHSNo ratings yet
- Module 22 Confidence Interval Estimation of The Population MeanDocument5 pagesModule 22 Confidence Interval Estimation of The Population MeanAlayka Mae Bandales LorzanoNo ratings yet
- EstimationDocument106 pagesEstimationasdasdas asdasdasdsadsasddssa0% (1)
- Confidence IntervalDocument13 pagesConfidence IntervalBhaskar Lal DasNo ratings yet
- Estimating Population Values with Confidence IntervalsDocument61 pagesEstimating Population Values with Confidence IntervalsminhchauNo ratings yet
- Estimation 1Document70 pagesEstimation 1Mohammed AbdelaNo ratings yet
- Estimation NewDocument37 pagesEstimation Newmubasher akramNo ratings yet
- BS 6-8Document60 pagesBS 6-8AnshumanNo ratings yet
- Estimation Sample Statistics Are Used To Estimate Population ParametersDocument2 pagesEstimation Sample Statistics Are Used To Estimate Population ParametersAnthea ClarkeNo ratings yet
- Lec - Confidence IntervalDocument39 pagesLec - Confidence IntervalEMIL ADRIANONo ratings yet
- Chapter 7 Confidence Intervals and Sample Size 1211425705575095 9Document31 pagesChapter 7 Confidence Intervals and Sample Size 1211425705575095 9KAMRAN TAIMOORNo ratings yet
- Math11 SP Q3 M8 PDFDocument12 pagesMath11 SP Q3 M8 PDFJessa Banawan EdulanNo ratings yet
- Exercise 6 For StudentsDocument2 pagesExercise 6 For StudentsKhayandra SalsabilaNo ratings yet
- Tuga Kelompok JP MorganDocument2 pagesTuga Kelompok JP MorganKhayandra SalsabilaNo ratings yet
- PR Maksi MR B211 - P2 - P3 - 03 - Erning DittaDocument2 pagesPR Maksi MR B211 - P2 - P3 - 03 - Erning DittaKhayandra SalsabilaNo ratings yet
- Exercise 5 - Hypothesis Testing Problem 1Document1 pageExercise 5 - Hypothesis Testing Problem 1Khayandra SalsabilaNo ratings yet
- Women Empowerment Through EntrepreneurshipDocument39 pagesWomen Empowerment Through EntrepreneurshipClassic PrintersNo ratings yet
- Diego Farren - Thesis ShortDocument85 pagesDiego Farren - Thesis ShortDiego RiedemannNo ratings yet
- PHILSCA-Mactan ThesisDocument96 pagesPHILSCA-Mactan ThesisNahshon YbañezNo ratings yet
- Learning Task 10 - The Central Limit Theorem, Confidence Interval and Sample SizeDocument7 pagesLearning Task 10 - The Central Limit Theorem, Confidence Interval and Sample SizeCharles SilerioNo ratings yet
- Chapter05 VamDocument13 pagesChapter05 VamVamshi KrishnaNo ratings yet
- Project AssignmentDocument8 pagesProject AssignmentFelipe RocheNo ratings yet
- Frequency Distribution TableDocument4 pagesFrequency Distribution Tableembriones11100% (2)
- Summer Project (Final)Document48 pagesSummer Project (Final)Srijana kadelNo ratings yet
- LLM Assignment (1st Semseter)Document54 pagesLLM Assignment (1st Semseter)Ali Ahsan100% (1)
- Excel Kruskal Wallis y FriedmanDocument18 pagesExcel Kruskal Wallis y FriedmanabelrqNo ratings yet
- Analisis DataDocument11 pagesAnalisis DataRizky NovitasariNo ratings yet
- Tutorial Letter 201/1/2013: Distribution Theory IDocument4 pagesTutorial Letter 201/1/2013: Distribution Theory Isal27adamNo ratings yet
- TR Bangkitan Perjalanan - Muhammad Fajar AdibaDocument3 pagesTR Bangkitan Perjalanan - Muhammad Fajar AdibaYoel PaskahitaNo ratings yet
- 8 - Part - 2 - Hypo - Z - Test - Beta - N - and - T - Test.9188.1587301904.1057 2Document36 pages8 - Part - 2 - Hypo - Z - Test - Beta - N - and - T - Test.9188.1587301904.1057 2Pun AditepNo ratings yet
- Super Position TheoremDocument14 pagesSuper Position TheoremEnoch DammuNo ratings yet
- Regression Line of Overhead Costs On LaborDocument3 pagesRegression Line of Overhead Costs On LaborElliot Richard100% (1)
- LECTURE NO. 5 Measures of Central TendencyDocument27 pagesLECTURE NO. 5 Measures of Central TendencyCzarina GuevarraNo ratings yet
- Development of Student's Academic Performance Prediction ModelDocument16 pagesDevelopment of Student's Academic Performance Prediction ModelopepolawalNo ratings yet
- MTH JSS 3 SchemeDocument1 pageMTH JSS 3 SchemePatrick Chukwunonso A.No ratings yet
- Lmodel 2Document6 pagesLmodel 2Amsalu WalelignNo ratings yet
- Quantitative ResearchDocument23 pagesQuantitative ResearchMitzie MaliniasNo ratings yet
- REVIEW OF CLRMsDocument53 pagesREVIEW OF CLRMswebeshet bekeleNo ratings yet
- Module 3: Principles of Psychological Testing: Central Luzon State UniversityDocument14 pagesModule 3: Principles of Psychological Testing: Central Luzon State UniversityPATRICIA GOLTIAONo ratings yet
- Statistics For Business and Economics: Describing Data: NumericalDocument40 pagesStatistics For Business and Economics: Describing Data: NumericalIbrahim RashidNo ratings yet
- Stat 3rd Week 2Document11 pagesStat 3rd Week 2Reyboy TagsipNo ratings yet
- Data Can Be Classified As Qualitative or Quantitative.: Recall From YesterdayDocument5 pagesData Can Be Classified As Qualitative or Quantitative.: Recall From YesterdayaftabNo ratings yet
- Types of Hypotheses ExplainedDocument3 pagesTypes of Hypotheses ExplainedChirag RathodNo ratings yet
- Third Culture KidsDocument26 pagesThird Culture KidsJoar BonifacioNo ratings yet
- Expected Value Piecewise PDFDocument2 pagesExpected Value Piecewise PDFCarrieNo ratings yet