You might also like
- Data Structures and Algorithms in Swift: Implement Stacks, Queues, Dictionaries, and Lists in Your AppsFrom EverandData Structures and Algorithms in Swift: Implement Stacks, Queues, Dictionaries, and Lists in Your AppsNo ratings yet
- Counting The Costs Martin Widlake's Yet Another Oracle BlogDocument7 pagesCounting The Costs Martin Widlake's Yet Another Oracle BlogquanticdreamNo ratings yet
- Obtaining and Interpreting Execution Plans Using Dbms - Xplan: David KurtzDocument68 pagesObtaining and Interpreting Execution Plans Using Dbms - Xplan: David KurtzkruemeL1969No ratings yet
- Advance JavaDocument9 pagesAdvance JavasaiNo ratings yet
- What Is Sql ?: Fundamentals of Sql,T-Sql,Pl/Sql and Datawarehousing.From EverandWhat Is Sql ?: Fundamentals of Sql,T-Sql,Pl/Sql and Datawarehousing.No ratings yet
- Data Warehouse: Bilal HussainDocument20 pagesData Warehouse: Bilal HussainDaneil RadcliffeNo ratings yet
- Mca II Dbms LabmannualDocument29 pagesMca II Dbms LabmannualGhanshyam KumarNo ratings yet
- DB2 9 for z/OS Database Administration: Certification Study GuideFrom EverandDB2 9 for z/OS Database Administration: Certification Study GuideNo ratings yet
- DPA Lecture 4Document66 pagesDPA Lecture 4shbjalamNo ratings yet
- Oracle 12c Ch4Document44 pagesOracle 12c Ch4MsShanyloveNo ratings yet
- Intro To TSQLDocument476 pagesIntro To TSQLsudheer_edupugantiNo ratings yet
- Performance Scenario Sudden Slowdown On RacDocument45 pagesPerformance Scenario Sudden Slowdown On RacbehanchodNo ratings yet
- Oracle Database Worst PracticesDocument55 pagesOracle Database Worst Practicesimsaar100% (17)
- SSIS Best PracticesDocument47 pagesSSIS Best Practicesvivarius100% (2)
- Oracle/SQL TutorialDocument52 pagesOracle/SQL Tutorialsarfraj_2No ratings yet
- Ten Outrageous Performance TipsDocument161 pagesTen Outrageous Performance TipsAbdul JabbarNo ratings yet
- Session 13Document26 pagesSession 13admiralninjaNo ratings yet
- Week6 - PostgreSQL CH 6-10Document36 pagesWeek6 - PostgreSQL CH 6-10MedAyhem KhNo ratings yet
- SQL Basics For RPG DevelopersDocument76 pagesSQL Basics For RPG DevelopersRamana VaralaNo ratings yet
- What Is Mutating Trigger?: Test Empno Test 1001Document24 pagesWhat Is Mutating Trigger?: Test Empno Test 1001shNo ratings yet
- Session 13Document26 pagesSession 13Eric LiNo ratings yet
- Oracle Interview Questions and Answers: SQLDocument28 pagesOracle Interview Questions and Answers: SQLThirupathi Reddy LingalaNo ratings yet
- 从 Oracle 合并到 MySQL - NPR 实例分析Document24 pages从 Oracle 合并到 MySQL - NPR 实例分析HoneyMooseNo ratings yet
- Buy Quest Products Buy Guy'S Book Buy Quest Products: Top Tips For Oracle SQL TuningDocument41 pagesBuy Quest Products Buy Guy'S Book Buy Quest Products: Top Tips For Oracle SQL TuningJasu MakNo ratings yet
- Research Methods: Wiji ArulampalamDocument45 pagesResearch Methods: Wiji ArulampalamHector GarciaNo ratings yet
- OracleSQLTuning 1Document41 pagesOracleSQLTuning 1maity.20053667No ratings yet
- ColumnStore Index - How - It - Work - SQLSaturdayDocument26 pagesColumnStore Index - How - It - Work - SQLSaturdayDaniel PalaciosNo ratings yet
- DbmslabmanualDocument81 pagesDbmslabmanualCharitha IddumNo ratings yet
- Boost Performance With Mysql 5.1 Partitions: Giuseppe Maxia Mysql Community Team Lead Sun MicrosystemsDocument106 pagesBoost Performance With Mysql 5.1 Partitions: Giuseppe Maxia Mysql Community Team Lead Sun Microsystemsganesh_vennu1967No ratings yet
- Tuning SQL Statements AgainDocument9 pagesTuning SQL Statements Againamol100% (6)
- Ukoug2012 DudeDocument37 pagesUkoug2012 Dudejlc1967No ratings yet
- Oracle SQL FAQ: TopicsDocument10 pagesOracle SQL FAQ: Topicskc.shanmugavel1202No ratings yet
- Introduction To T-SQL QueryingDocument28 pagesIntroduction To T-SQL Queryingحسن مجدىNo ratings yet
- Enkitec RealWorldExadataDocument38 pagesEnkitec RealWorldExadatatssr2001No ratings yet
- Adapters DB 307 ExpertPollingDocument8 pagesAdapters DB 307 ExpertPollingRKNo ratings yet
- Chapter - 1 - Query OptimizationDocument38 pagesChapter - 1 - Query Optimizationmaki ababiNo ratings yet
- Oracle SQL Tuning PDFDocument70 pagesOracle SQL Tuning PDFSunitha90% (1)
- Interpreting Explain Plan Output: John MullinsDocument28 pagesInterpreting Explain Plan Output: John MullinsMohammad Mizanur RahmanNo ratings yet
- Database Cheat SheetDocument4 pagesDatabase Cheat SheetJoseph CraigNo ratings yet
- Data Structures T1 QueuesDocument32 pagesData Structures T1 QueuesdsfjhvbNo ratings yet
- Oracle Database: Presented by Rajesh PolasuDocument166 pagesOracle Database: Presented by Rajesh PolasuSaroj PatnaikNo ratings yet
- Oracle SQL FAQ: What Is SQL and Where Does It Come From?Document8 pagesOracle SQL FAQ: What Is SQL and Where Does It Come From?jyotipc_mcaNo ratings yet
- Best Practices Implementing FinalDocument40 pagesBest Practices Implementing FinalWilson VerardiNo ratings yet
- Unit-2 Feature SelectionDocument92 pagesUnit-2 Feature SelectionRahul VashisthaNo ratings yet
- Bca Chapter 10 - Ado - Net With DatabaseDocument21 pagesBca Chapter 10 - Ado - Net With DatabaseSelvarani ResearchNo ratings yet
- R Programming SlidesDocument73 pagesR Programming SlidesYan Jun HoNo ratings yet
- Joe Sack Performance Troubleshooting With Wait StatsDocument56 pagesJoe Sack Performance Troubleshooting With Wait StatsAamöd ThakürNo ratings yet
- ABAP On HANA Interview QuestionsDocument26 pagesABAP On HANA Interview QuestionsNagesh reddyNo ratings yet
- Interview QuestionsDocument17 pagesInterview QuestionskarunasreemNo ratings yet
- 20761a 02Document28 pages20761a 02Guadalupe SantiagoNo ratings yet
- 7 Oracle SQL Tuning Tactics You Can Start Implementing ImmediatelyDocument10 pages7 Oracle SQL Tuning Tactics You Can Start Implementing ImmediatelynagarjunapurumNo ratings yet
- Advanced Oracle SQL TuningDocument5 pagesAdvanced Oracle SQL TuningJAvier BordonadaNo ratings yet
- Dsa Basic Data StructureDocument72 pagesDsa Basic Data StructureVamsi PradeepNo ratings yet
- DBA Genesis - Oracle DBA ScriptsDocument35 pagesDBA Genesis - Oracle DBA ScriptsKamaldeep Nainwal60% (5)
- Wrong ResultsDocument18 pagesWrong ResultsConstantin CaiaNo ratings yet
- Working With Master Pages Themes & Skins Collections & Lists Data Binding Working With XMLDocument30 pagesWorking With Master Pages Themes & Skins Collections & Lists Data Binding Working With XMLonline_narendraNo ratings yet
- Active Record Presentation Feb 12Document26 pagesActive Record Presentation Feb 12Alex KojinNo ratings yet
- The Big M Method: Group BDocument7 pagesThe Big M Method: Group BWoo Jin YoungNo ratings yet
- NEW Sample ISAT Questions RevisedDocument14 pagesNEW Sample ISAT Questions RevisedHa HoangNo ratings yet
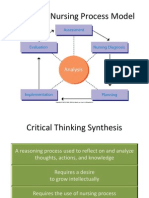
- NUR 104 Nursing Process MY NOTESDocument77 pagesNUR 104 Nursing Process MY NOTESmeanne073100% (1)
- Application of SPACE MatrixDocument11 pagesApplication of SPACE Matrixdecker444975% (4)
- Coastal Blue Carbon - Methods For Assessing Carbon Stocks and Emissions Factors in Mangroves Tidal Salt Marshes and Seagrass MeadowsDocument182 pagesCoastal Blue Carbon - Methods For Assessing Carbon Stocks and Emissions Factors in Mangroves Tidal Salt Marshes and Seagrass Meadowsapi-245803001No ratings yet
- Datasheet TBJ SBW13009-KDocument5 pagesDatasheet TBJ SBW13009-KMarquinhosCostaNo ratings yet
- Alfa Laval Aalborg Os Tci Marine BoilerDocument2 pagesAlfa Laval Aalborg Os Tci Marine Boilera.lobanov2020No ratings yet
- Refrigerant Unit Lab ReportDocument19 pagesRefrigerant Unit Lab Reportakmal100% (2)
- Unit 12 BriefDocument7 pagesUnit 12 Briefapi-477397447No ratings yet
- 8 TH Linear Equations DBDocument1 page8 TH Linear Equations DBParth GoyalNo ratings yet
- FORM Module IpsDocument10 pagesFORM Module IpsRizalNo ratings yet
- Automatic Tools For High Availability in Postgresql: Camilo Andrés EcheverriDocument9 pagesAutomatic Tools For High Availability in Postgresql: Camilo Andrés EcheverriRegistro PersonalNo ratings yet
- Smart English 2 PDFDocument44 pagesSmart English 2 PDFmishhuana90% (21)
- CIT 811 TMA 4 Quiz QuestionDocument3 pagesCIT 811 TMA 4 Quiz QuestionjohnNo ratings yet
- RTRT User GuideDocument324 pagesRTRT User GuideAlae Khaoua100% (3)
- Contemplation (Murāqaba) and Spiritual Focus/attention (Tawajjuh) in The Pre-Mujaddidi Naqshibandi OrderDocument5 pagesContemplation (Murāqaba) and Spiritual Focus/attention (Tawajjuh) in The Pre-Mujaddidi Naqshibandi OrderShahmir ShahidNo ratings yet
- Cpa f1.1 - Business Mathematics & Quantitative Methods - Study ManualDocument573 pagesCpa f1.1 - Business Mathematics & Quantitative Methods - Study ManualMarcellin MarcaNo ratings yet
- Being Agile. Staying Resilient.: ANNUAL REPORT 2021-22Document296 pagesBeing Agile. Staying Resilient.: ANNUAL REPORT 2021-22PrabhatNo ratings yet
- Bagi CHAPT 7 TUGAS INGGRIS W - YAHIEN PUTRIDocument4 pagesBagi CHAPT 7 TUGAS INGGRIS W - YAHIEN PUTRIYahien PutriNo ratings yet
- Self-Actualization in Robert Luketic'S: Legally Blonde: A HumanisticDocument10 pagesSelf-Actualization in Robert Luketic'S: Legally Blonde: A HumanisticAyeshia FréyNo ratings yet
- A B&C - List of Residents - VKRWA 12Document10 pagesA B&C - List of Residents - VKRWA 12blr.visheshNo ratings yet
- Math Cad 15Document3 pagesMath Cad 15Kim ChanthanNo ratings yet
- Module 2 - Part III - UpdatedDocument38 pagesModule 2 - Part III - UpdatedDhriti NayyarNo ratings yet
- Mother Tongue Based Instruction in The Newly Implemented K To 12 Curriculum of The PhilippinesDocument16 pagesMother Tongue Based Instruction in The Newly Implemented K To 12 Curriculum of The PhilippinesEi JayNo ratings yet
- Faculty of AyurvedaDocument9 pagesFaculty of AyurvedaKirankumar MutnaliNo ratings yet
- House Staff OrderDocument2 pagesHouse Staff OrderTarikNo ratings yet
- Case Study 1 HRM in PandemicDocument2 pagesCase Study 1 HRM in PandemicKristine Dana LabaguisNo ratings yet
- Charging Station For E-Vehicle Using Solar With IOTDocument6 pagesCharging Station For E-Vehicle Using Solar With IOTjakeNo ratings yet
- Malnutrition Case StudyDocument3 pagesMalnutrition Case Studyapi-622273373No ratings yet
- Ielts Reading Actual Tests With Suggested Answers Oct 2021 JDocument508 pagesIelts Reading Actual Tests With Suggested Answers Oct 2021 JHarpreet Singh JohalNo ratings yet