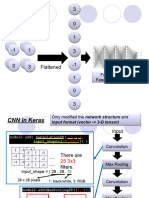
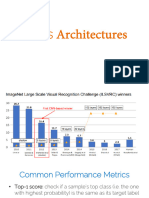
You might also like
- Graphics Gems III (IBM Version): Ibm VersionFrom EverandGraphics Gems III (IBM Version): Ibm VersionRating: 3.5 out of 5 stars3.5/5 (3)
- MCQs (Machine Learning)Document7 pagesMCQs (Machine Learning)Zeeshan Ali Khan50% (22)
- Convolutional Neural NetworksDocument31 pagesConvolutional Neural NetworksAamir ayub100% (1)
- CS60010: Deep Learning CNN - Part 3: Sudeshna SarkarDocument167 pagesCS60010: Deep Learning CNN - Part 3: Sudeshna SarkarDEEP ROYNo ratings yet
- Lecture06 VDLDocument79 pagesLecture06 VDLnikhit5No ratings yet
- GoogleNET and ResNet v4 With Nin and BiasDocument82 pagesGoogleNET and ResNet v4 With Nin and Bias5049 Harishchandra KumarNo ratings yet
- CNN Variants V1Document109 pagesCNN Variants V1Eman zakriaNo ratings yet
- IC - Lez4-5-6 - Convolutional NetsDocument85 pagesIC - Lez4-5-6 - Convolutional NetsJorge Iván Sepúlveda HNo ratings yet
- a-GIST CNNs Quicksummary HyungukDocument25 pagesa-GIST CNNs Quicksummary Hyunguk최희욱No ratings yet
- "Hello World" of Deep LearningDocument26 pages"Hello World" of Deep LearningMohan ScNo ratings yet
- Asset-V1 MITx+6.86x+3T2020+typeasset+blockslides Lecture12 Compressed PDFDocument13 pagesAsset-V1 MITx+6.86x+3T2020+typeasset+blockslides Lecture12 Compressed PDFRahul VasanthNo ratings yet
- Video Coding (VC-1)Document35 pagesVideo Coding (VC-1)Kholidiyah Masykuroh YusufNo ratings yet
- Lecture26 Autoencoders Part BDocument23 pagesLecture26 Autoencoders Part BinnovativewebhubNo ratings yet
- CNN Architectures-Stanford-Small SizeDocument95 pagesCNN Architectures-Stanford-Small SizeZee IngameNo ratings yet
- Imp.-Image Category Classification Using Deep Learning-MATLABDocument9 pagesImp.-Image Category Classification Using Deep Learning-MATLABMirceaNo ratings yet
- 5b DanaDocument67 pages5b Dana22 / Gyanaranjan NayakNo ratings yet
- 2017 - Lecture 5 - Smaller Network - CNN - 3 (Ming Li) (8 Slides)Document8 pages2017 - Lecture 5 - Smaller Network - CNN - 3 (Ming Li) (8 Slides)rvasiliouNo ratings yet
- SSD: Single Shot Multibox Detector: (Wliu, Cyfu, Aberg) @cs - Unc.EduDocument17 pagesSSD: Single Shot Multibox Detector: (Wliu, Cyfu, Aberg) @cs - Unc.EduRevanth VennuNo ratings yet
- Alex NetDocument11 pagesAlex NetMackrish MalikNo ratings yet
- L10 - Intro - To - Deep - LearningDocument75 pagesL10 - Intro - To - Deep - LearningNALE SVPMEnggNo ratings yet
- "Hello World" of Deep Learning: Disclaimer: This PPT Is Modified Based On Dr. Hung-Yi LeeDocument19 pages"Hello World" of Deep Learning: Disclaimer: This PPT Is Modified Based On Dr. Hung-Yi LeeMehtab MehdiNo ratings yet
- DSE 3151 25 Sep 2023Document9 pagesDSE 3151 25 Sep 2023KaiNo ratings yet
- Recurrent Neural Networks - cs231n - 2018 - Lecture10Document107 pagesRecurrent Neural Networks - cs231n - 2018 - Lecture10Annuar BernalNo ratings yet
- Q1. (2 Marks) Compute The Output Volume and Total Parameters For The Given CNN Which Is A Slightly Modified Version of Lenet-5Document3 pagesQ1. (2 Marks) Compute The Output Volume and Total Parameters For The Given CNN Which Is A Slightly Modified Version of Lenet-5wellhellothere123No ratings yet
- Problem Set 11Document3 pagesProblem Set 11Tushar GargNo ratings yet
- Detecting Small Signs From Large ImagesDocument9 pagesDetecting Small Signs From Large ImagesafzaalkhanNo ratings yet
- Redes Móveis e Sem Fios: 1º Teste - 1 ParteDocument3 pagesRedes Móveis e Sem Fios: 1º Teste - 1 ParteAntónio GriloNo ratings yet
- 1 SMDocument6 pages1 SMSamaroha NandiNo ratings yet
- Advanced Computational Methods & ModellingDocument49 pagesAdvanced Computational Methods & ModellingKazim RazaNo ratings yet
- Lec9 CNN 25jan18Document111 pagesLec9 CNN 25jan18Trần Văn DuyNo ratings yet
- Solution To Practice Problem Set 4Document6 pagesSolution To Practice Problem Set 4agentrangomanNo ratings yet
- Image Recognition Using Neural NetworksDocument18 pagesImage Recognition Using Neural NetworksAkásh SrívástávNo ratings yet
- Caches: Shmuel WimerDocument69 pagesCaches: Shmuel WimerJitendra PatelNo ratings yet
- Dense NetDocument28 pagesDense NetFahad RazaNo ratings yet
- Lecture11 - CNN ArchitecturesDocument129 pagesLecture11 - CNN ArchitecturesCariza DiasNo ratings yet
- VGG 4Document3 pagesVGG 4nirmala periasamyNo ratings yet
- MS SS 16Document11 pagesMS SS 16f725qcsn74No ratings yet
- Assignment#08 DLDocument2 pagesAssignment#08 DLJahn ZaibNo ratings yet
- Discrete Fourier TransformDocument20 pagesDiscrete Fourier Transformxiso2507No ratings yet
- Day 10Document17 pagesDay 10Sulakx KuruNo ratings yet
- Transfer Learning - Part 1Document16 pagesTransfer Learning - Part 1AditiNo ratings yet
- CS60010: Deep Learning CNN - Part 1: Sudeshna SarkarDocument64 pagesCS60010: Deep Learning CNN - Part 1: Sudeshna SarkarDEEP ROYNo ratings yet
- DSE 5251 Insem1 SchemeDocument8 pagesDSE 5251 Insem1 SchemeBalathrinath ReddyNo ratings yet
- Aidl 2023s DL 08 CNN ArchitecturesDocument51 pagesAidl 2023s DL 08 CNN ArchitecturesOuriNo ratings yet
- Deep Clustering With Convolutional AutoencodersDocument10 pagesDeep Clustering With Convolutional AutoencodersFrancesco BNo ratings yet
- Tutorial QuestionsDocument16 pagesTutorial Questionschandadevils100% (1)
- 6-DeepVisualLearning L6Document82 pages6-DeepVisualLearning L6hisisthesongoficeandfireNo ratings yet
- Chapter 20 Minimal Spanning Tree 3399Document8 pagesChapter 20 Minimal Spanning Tree 3399Raine PiliinNo ratings yet
- Deep Residual Learning For Image Recognition (Summary)Document11 pagesDeep Residual Learning For Image Recognition (Summary)Tomoki TsuchidaNo ratings yet
- Convolutional Neural NetworksDocument102 pagesConvolutional Neural NetworksAbdul hadiNo ratings yet
- Compression: Author: Paul Penfield, Jr. 2004 Massachusetts Institute of Technology Url: Start: Back: NextDocument8 pagesCompression: Author: Paul Penfield, Jr. 2004 Massachusetts Institute of Technology Url: Start: Back: Next沈国威No ratings yet
- Convolution Neural NetworkDocument16 pagesConvolution Neural NetworkArafat HossainNo ratings yet
- Tutorial On DNN 02 Popular DNNs DatasetsDocument60 pagesTutorial On DNN 02 Popular DNNs DatasetsSrikanthNo ratings yet
- Chapter7-1 V - 3 12-08-2004Document54 pagesChapter7-1 V - 3 12-08-2004fvmmvf01No ratings yet
- CNN 22mar2017Document110 pagesCNN 22mar2017Rahul AryanNo ratings yet
- CNN For Computer Vision Problem (Session 1)Document43 pagesCNN For Computer Vision Problem (Session 1)haryantoNo ratings yet
- Lecture 18Document49 pagesLecture 18Mohamed ElsaneeNo ratings yet
- CNN Architectures 01Document66 pagesCNN Architectures 01Abdul hadiNo ratings yet
- Tutorial 8 SolutionDocument4 pagesTutorial 8 Solutionsama abd elgelilNo ratings yet
- The CS Block CipherDocument10 pagesThe CS Block Cipherxativiy256No ratings yet
- Flood Fill: Flood Fill: Exploring Computer Vision's Dynamic TerrainFrom EverandFlood Fill: Flood Fill: Exploring Computer Vision's Dynamic TerrainNo ratings yet
- Hypothesis Testing: One Sample, Two Sample, Chi-SquareDocument19 pagesHypothesis Testing: One Sample, Two Sample, Chi-SquareBaraniNo ratings yet
- Hypothesis and LinearAlgebraDocument20 pagesHypothesis and LinearAlgebraBaraniNo ratings yet
- Advanced Statistics: Analysis of Variance (ANOVA) Dr. P.K.Viswanathan (Professor Analytics)Document19 pagesAdvanced Statistics: Analysis of Variance (ANOVA) Dr. P.K.Viswanathan (Professor Analytics)BaraniNo ratings yet
- Bank Personal Loan ModellingDocument210 pagesBank Personal Loan ModellingBaraniNo ratings yet
- Working With Real World DataDocument32 pagesWorking With Real World DataBaraniNo ratings yet
- Transfer LearningDocument24 pagesTransfer LearningBaraniNo ratings yet
- An Improved Savings Method For Vehicle Routing ProblemDocument6 pagesAn Improved Savings Method For Vehicle Routing ProblemMy NguyễnNo ratings yet
- Chegg UnlockDocument3 pagesChegg UnlockOdedeMapuaNo ratings yet
- Decimal Division Implementation Using VHDLDocument16 pagesDecimal Division Implementation Using VHDLVikas KumarNo ratings yet
- CH 2Document16 pagesCH 2hailegebreselassie24No ratings yet
- Lesson Four PolynomialsDocument3 pagesLesson Four PolynomialsT-girlNo ratings yet
- Gauss QuadratureDocument9 pagesGauss QuadratureAnkur ChauhanNo ratings yet
- 07 Chapter 5 Location Models in Facility PlanningDocument72 pages07 Chapter 5 Location Models in Facility PlanningBirce IrmakNo ratings yet
- Lagrange InterpolationDocument3 pagesLagrange Interpolationanis anisNo ratings yet
- Gradient Descent Algorithms and Variations - PyImageSearchDocument21 pagesGradient Descent Algorithms and Variations - PyImageSearchROHIT ARORANo ratings yet
- C1 W2 Lab05 Sklearn GD SolnDocument3 pagesC1 W2 Lab05 Sklearn GD SolnSrinidhi PNo ratings yet
- The Power Method For Eigenvectors: EigenvalueDocument14 pagesThe Power Method For Eigenvectors: EigenvalueGovind1085No ratings yet
- Perceptron - WikipediaDocument9 pagesPerceptron - WikipediaNoles PandeNo ratings yet
- 1 Gauss-Jordan LapenaDocument4 pages1 Gauss-Jordan LapenaLeandro LapeñaNo ratings yet
- CENGR 3140:: Numerical Solutions To Ce ProblemsDocument21 pagesCENGR 3140:: Numerical Solutions To Ce ProblemsBry RamosNo ratings yet
- Particle Swarm OptimizationDocument13 pagesParticle Swarm OptimizationSaumil ShahNo ratings yet
- A Survey of Convolutional Neural Networks AnalysisDocument22 pagesA Survey of Convolutional Neural Networks AnalysisimrizwanaliNo ratings yet
- Polynomials ProjectDocument21 pagesPolynomials ProjectDhananjay50% (6)
- Methods and Models For Combinatorial OptimizationDocument17 pagesMethods and Models For Combinatorial OptimizationVictor Hugo Males BravoNo ratings yet
- Advanced Enginering Mathematics For Chemical EnginDocument8 pagesAdvanced Enginering Mathematics For Chemical EnginFrendick LegaspiNo ratings yet
- Regular Language PresentationDocument10 pagesRegular Language PresentationJadaNo ratings yet
- Rr410210 Optimization TechniquesDocument8 pagesRr410210 Optimization TechniquesSrinivasa Rao GNo ratings yet
- Quasi Newton MethodsDocument15 pagesQuasi Newton MethodsPoornima NarayananNo ratings yet
- Master's Numerical Test 2 - DEC2020Document2 pagesMaster's Numerical Test 2 - DEC2020Mohamad AfiqNo ratings yet
- Compiler Design: Lexical Analysis Sample Exercises and SolutionsDocument30 pagesCompiler Design: Lexical Analysis Sample Exercises and SolutionsKavin MartinNo ratings yet
- Unit - I Artificial Neural NetworksDocument23 pagesUnit - I Artificial Neural NetworksMary MorseNo ratings yet
- Binder1 71 PDFDocument1 pageBinder1 71 PDFAbdul RahmanNo ratings yet
- Combinatorics 11695Document41 pagesCombinatorics 11695Klaus BudaNo ratings yet
- ZHAO XiaozongDocument9 pagesZHAO Xiaozongssyxz10No ratings yet
- Ma7102 Advanced Numerical Methods L T P CDocument2 pagesMa7102 Advanced Numerical Methods L T P Cramyaranganayaki0% (1)