You might also like
- Home Lab For VMware VSphere 6.0Document47 pagesHome Lab For VMware VSphere 6.0amlesh80100% (4)
- STRUDS V12 TUTORIAL GUIDEDocument78 pagesSTRUDS V12 TUTORIAL GUIDEakvabby0% (2)
- Easy 2 BootDocument13 pagesEasy 2 BootKishore KumarNo ratings yet
- Buyer Keywords Guide PDFDocument15 pagesBuyer Keywords Guide PDFTauseef AhmadNo ratings yet
- Project Final Report TemplateDocument14 pagesProject Final Report Templatemonparaashvin0% (1)
- Schrock Infographic Rubric PDFDocument2 pagesSchrock Infographic Rubric PDFCha Gao-ay100% (1)
- 5G Transport Slice Control in End-To-End 5G NetworksDocument19 pages5G Transport Slice Control in End-To-End 5G NetworksmorganNo ratings yet
- Progress Test 4 Units 10 12 Ingls de La Escuela 2011 Pearson Longman EltDocument11 pagesProgress Test 4 Units 10 12 Ingls de La Escuela 2011 Pearson Longman EltNines TicóNo ratings yet
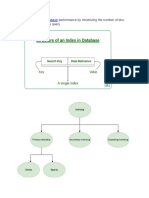
- Unit Iv Indexing and Hashing: Basic ConceptsDocument35 pagesUnit Iv Indexing and Hashing: Basic ConceptsBOMMA SRI MUKHINo ratings yet
- DBMS Indexing MethodsDocument33 pagesDBMS Indexing Methodsalviamin160No ratings yet
- Advanced Database Indexing TechniquesDocument50 pagesAdvanced Database Indexing TechniquesOriani SihalohoNo ratings yet
- CSE 301 Lecture-8-Indexing WTDocument31 pagesCSE 301 Lecture-8-Indexing WTrafi siddiqueNo ratings yet
- Index and HashingDocument82 pagesIndex and Hashingaparna_savalam485No ratings yet
- CO3 Notes IndexingDocument11 pagesCO3 Notes IndexingNani YagneshwarNo ratings yet
- UNIT-5: Indexing and HashingDocument78 pagesUNIT-5: Indexing and HashingcnpnrajaNo ratings yet
- Index Architecture: Febriliyan SamopaDocument110 pagesIndex Architecture: Febriliyan SamopaPramuditha Muhammad IkhwanNo ratings yet
- MySQL IndexDocument79 pagesMySQL IndexfqchinaNo ratings yet
- Chapter 11: Indexing and Hashing: Database System Concepts, 6 EdDocument45 pagesChapter 11: Indexing and Hashing: Database System Concepts, 6 EdRenny MayarNo ratings yet
- Chapter 12: Indexing and HashingDocument71 pagesChapter 12: Indexing and HashingEkta YadavNo ratings yet
- Chapter 4 IndexingDocument37 pagesChapter 4 IndexingPiyumi SandarekaNo ratings yet
- Static Hashing in DBMSDocument75 pagesStatic Hashing in DBMSvandana_kordeNo ratings yet
- Chapter 11: Indexing and HashingDocument90 pagesChapter 11: Indexing and HashingRomel1407No ratings yet
- Chapter 11: Indexing and Hashing: Database System Concepts, 6 EdDocument90 pagesChapter 11: Indexing and Hashing: Database System Concepts, 6 EdHafeeza Kuljar FathimaNo ratings yet
- Single Level IndexingDocument9 pagesSingle Level IndexingNerin ErinNo ratings yet
- DBMS Indexing B - Tree To B Tree (197222, 197125, 197155)Document41 pagesDBMS Indexing B - Tree To B Tree (197222, 197125, 197155)VamsiNo ratings yet
- Chapter 12: Indexing and HashingDocument31 pagesChapter 12: Indexing and HashingRajvinder SinghNo ratings yet
- Indexing and HashingDocument84 pagesIndexing and HashingMahi SahanaNo ratings yet
- Indexing in DatabaseDocument33 pagesIndexing in DatabaseRavi PrakashNo ratings yet
- MODULE-5 DBMS CS208 NOTES - Ktuassist - inDocument11 pagesMODULE-5 DBMS CS208 NOTES - Ktuassist - inVaisakh GopinathNo ratings yet
- Unit 4 Index Structures For Files: StructureDocument16 pagesUnit 4 Index Structures For Files: StructuregaardiNo ratings yet
- Dbms IndexingDocument3 pagesDbms IndexingKhairul Hossain SaikatNo ratings yet
- ECS-165A WQ’11 7. IndexesDocument13 pagesECS-165A WQ’11 7. IndexesMinhaz Kamal 2No ratings yet
- What is Indexing in DatabasesDocument7 pagesWhat is Indexing in DatabasesafzhussainNo ratings yet
- Unit08 DBMSDocument45 pagesUnit08 DBMSRamlal Chavan100% (1)
- Database Indexing Types and StructuresDocument8 pagesDatabase Indexing Types and StructuresVijay KumarNo ratings yet
- IndexingDocument10 pagesIndexingprasadNo ratings yet
- CIS552 Indexing and Hashing 1Document56 pagesCIS552 Indexing and Hashing 1Vinay VarmaNo ratings yet
- Dbms PPT For Chapter 7Document45 pagesDbms PPT For Chapter 7Sreekavya AchantiNo ratings yet
- 05 IndexesDocument28 pages05 IndexesJoao CarvalhoNo ratings yet
- CH 12Document84 pagesCH 12Satyam SinghNo ratings yet
- CMP 312Document2 pagesCMP 312vyktoriaNo ratings yet
- CIS552 Indexing and Hashing 1Document56 pagesCIS552 Indexing and Hashing 1Kannan RockNo ratings yet
- Module 4 IndexingDocument20 pagesModule 4 Indexinghatic33126No ratings yet
- Indexing Lecture Nov 2023 SummaryDocument41 pagesIndexing Lecture Nov 2023 Summarymccreary.michael95No ratings yet
- UNITDocument58 pagesUNITK RANJITH REDDYNo ratings yet
- Indexing Structures For Files: Database Design Database DesignDocument9 pagesIndexing Structures For Files: Database Design Database Designsanjay.careear3267No ratings yet
- NetworksDocument3 pagesNetworksChrispine OtienoNo ratings yet
- B+ Tree IndexingDocument22 pagesB+ Tree Indexingimtiazahmedfahim87No ratings yet
- 03 Indexing-NDNDocument25 pages03 Indexing-NDNFarish Lupa Pass WordNo ratings yet
- Database Indexing and Hashing TechniquesDocument70 pagesDatabase Indexing and Hashing TechniquesMargita Kon-PopovskaNo ratings yet
- Single-Level Ordered IndexesDocument12 pagesSingle-Level Ordered IndexesKanwar VishawjeetNo ratings yet
- CIT 401 Lecture NoteDocument46 pagesCIT 401 Lecture NoteDaniel IzevbuwaNo ratings yet
- IndeDocument10 pagesIndeRajNo ratings yet
- 8 UnitDocument25 pages8 UnitRohit kumarNo ratings yet
- CS2606: Data Structures and Object-Oriented Development Chapter 10: IndexingDocument25 pagesCS2606: Data Structures and Object-Oriented Development Chapter 10: Indexinganon_484100541No ratings yet
- Chapter 12: Indexing and HashingDocument75 pagesChapter 12: Indexing and Hashingkarumuri mehernadhNo ratings yet
- Unit-6 Storage StrategiesDocument43 pagesUnit-6 Storage StrategiesShiv PatelNo ratings yet
- 11.1 Basic Concepts: EveryDocument16 pages11.1 Basic Concepts: Everynagarajuvcc123No ratings yet
- DBMS - Indexing: Dense IndexDocument5 pagesDBMS - Indexing: Dense IndexELIENo ratings yet
- Chapter 5Document41 pagesChapter 5Yared AregaNo ratings yet
- Indexing in DBMSDocument12 pagesIndexing in DBMSSravanti BagchiNo ratings yet
- Assignment #1: AnswerDocument3 pagesAssignment #1: AnswerOsamah 119No ratings yet
- Database Management Systems November 6, 2008: Dynamic Indexes: Sections 14.3Document38 pagesDatabase Management Systems November 6, 2008: Dynamic Indexes: Sections 14.3Senthil RNo ratings yet
- Indexing ImprovesDocument5 pagesIndexing ImprovesAyesha Latif LatifNo ratings yet
- Indexing Structures for Physical Database DesignDocument39 pagesIndexing Structures for Physical Database DesignLeónidas VillalbaNo ratings yet
- Unit-3 Part 2 Indexing and HashingDocument36 pagesUnit-3 Part 2 Indexing and Hashing219X1A3359 SINGASANI JAYA PRATHAP REDDYNo ratings yet
- ADVANCED DATA STRUCTURES FOR ALGORITHMS: Mastering Complex Data Structures for Algorithmic Problem-Solving (2024)From EverandADVANCED DATA STRUCTURES FOR ALGORITHMS: Mastering Complex Data Structures for Algorithmic Problem-Solving (2024)No ratings yet
- Euclidean AlgorithmDocument20 pagesEuclidean AlgorithmShivansh SaxenaNo ratings yet
- CH 02Document61 pagesCH 02Hassan MughalNo ratings yet
- Manav Rachna International Institute of Research and Studies (Deemed To Be University) Faculty of Engineering and Technology Department of Computer Science and EngineeringDocument1 pageManav Rachna International Institute of Research and Studies (Deemed To Be University) Faculty of Engineering and Technology Department of Computer Science and EngineeringShivansh SaxenaNo ratings yet
- Differences of The Database Approach and File Processing SystemDocument3 pagesDifferences of The Database Approach and File Processing SystemShivansh SaxenaNo ratings yet
- CourseDocument1 pageCourseShivansh SaxenaNo ratings yet
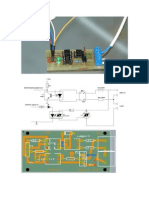
- Dimming AC lamps with Arduino using TRIAC phase angle controlDocument21 pagesDimming AC lamps with Arduino using TRIAC phase angle controlrodolfos_8No ratings yet
- Cross-Compiling Arm NN For The Raspberry Pi and TensorFlowDocument16 pagesCross-Compiling Arm NN For The Raspberry Pi and TensorFlowSair Puello RuizNo ratings yet
- Conducting A Nonlinear Fit Analysis in MATLAB: Using The FunctionDocument2 pagesConducting A Nonlinear Fit Analysis in MATLAB: Using The Functionfranzds_0041231No ratings yet
- Library Management System in DjangoDocument17 pagesLibrary Management System in DjangoujjwalNo ratings yet
- E-BUSINESS: AN INTRODUCTION TO E-COMMERCE AND ITS BENEFITSDocument25 pagesE-BUSINESS: AN INTRODUCTION TO E-COMMERCE AND ITS BENEFITSNikshithaNo ratings yet
- Numerical Integration ProjectDocument9 pagesNumerical Integration ProjectASGHaKCerNo ratings yet
- Controls Shimadzu Lc10 20systemsDocument78 pagesControls Shimadzu Lc10 20systemsMiroslava González MontielNo ratings yet
- Tax AssessmentsDocument4 pagesTax Assessmentsbhanotbhanot4No ratings yet
- BTBDocument126 pagesBTBBruno MartinsNo ratings yet
- Azure Virtual Machines and Windows Virtual DesktopDocument3 pagesAzure Virtual Machines and Windows Virtual DesktopMohamed IbrahimNo ratings yet
- Archive and extract home directory using tar and gzipDocument3 pagesArchive and extract home directory using tar and gzipKapasi TejasNo ratings yet
- Enterprise Resource Planning (ERP) Systems Integrate Internal and ExternalDocument14 pagesEnterprise Resource Planning (ERP) Systems Integrate Internal and ExternalYl WongNo ratings yet
- UNMS Introduction and General InformationDocument15 pagesUNMS Introduction and General InformationChief Engineer PRTINo ratings yet
- ITE1007 LTP J C 3 0 0 4 4 Pre-Requisite CSE1002 Syllabus VersionDocument2 pagesITE1007 LTP J C 3 0 0 4 4 Pre-Requisite CSE1002 Syllabus VersionAkshat GuptaNo ratings yet
- PT Activity 8.6.1: CCNA Skills Integration Challenge: Topology DiagramDocument7 pagesPT Activity 8.6.1: CCNA Skills Integration Challenge: Topology DiagramKok KosmaraNo ratings yet
- OHAUS Explorer Service ManualDocument114 pagesOHAUS Explorer Service ManualsambadeeNo ratings yet
- Quectel SC20&SC66&SC600x Series Screen Orientation and DPI Setting Guide V1.2Document28 pagesQuectel SC20&SC66&SC600x Series Screen Orientation and DPI Setting Guide V1.2Дмитрий СтудинскийNo ratings yet
- The Full SixesDocument7 pagesThe Full SixesKurt HennigNo ratings yet
- Communicating Internationally With Textplus+: Table of ContentsDocument9 pagesCommunicating Internationally With Textplus+: Table of ContentsM_HoyeNo ratings yet
- 8.2.5.4 Lab - Identifying IPv6 AddressesDocument10 pages8.2.5.4 Lab - Identifying IPv6 AddressesPriscila Maldonado100% (1)
- The 2005 Beginner's Guide To Getting Warez On IRCDocument30 pagesThe 2005 Beginner's Guide To Getting Warez On IRCDIzzIE100% (4)
- Agricultural and Forest Entomology - Author GuidelinesDocument4 pagesAgricultural and Forest Entomology - Author Guidelinesmib_579No ratings yet