You might also like
- 51 Machine Learning Interview Questions With Answers - SpringboardDocument20 pages51 Machine Learning Interview Questions With Answers - SpringboardShrivathsatv Shri100% (1)
- Data Science With Python Class Room Notes Qulaity ThoughtDocument489 pagesData Science With Python Class Room Notes Qulaity ThoughtDr. Ramu Kuchipudi Associate Professor (Contract)100% (2)
- Understanding of Convolutional Neural Network (CNN) - Deep LearningDocument7 pagesUnderstanding of Convolutional Neural Network (CNN) - Deep LearningKashaf BakaliNo ratings yet
- DCGAN (Deep Convolution Generative Adversarial Networks)Document27 pagesDCGAN (Deep Convolution Generative Adversarial Networks)lakpa tamangNo ratings yet
- An Analysis of Convolutional Neural Network ArchitecturesDocument54 pagesAn Analysis of Convolutional Neural Network ArchitecturesRaahul SinghNo ratings yet
- Understanding of Convolutional Neural Network (CNN) - Deep LearningDocument9 pagesUnderstanding of Convolutional Neural Network (CNN) - Deep LearningMark Alwin CaimbreNo ratings yet
- Convolutional Neural Networks: Fundamentals and Applications for Analyzing Visual ImageryFrom EverandConvolutional Neural Networks: Fundamentals and Applications for Analyzing Visual ImageryNo ratings yet
- IBM Question & AnswersDocument3 pagesIBM Question & AnswersMr SKammerNo ratings yet
- Convolutional Neural Network (CNN)Document38 pagesConvolutional Neural Network (CNN)Mohammad Hashim JaffriNo ratings yet
- Identify Web Cam Images Using Neural NetworksDocument17 pagesIdentify Web Cam Images Using Neural NetworksgauravNo ratings yet
- Selected Algorithm: Mse N y yDocument2 pagesSelected Algorithm: Mse N y yRokn ZamanNo ratings yet
- Classify Webcam Images Using Deep LearningDocument17 pagesClassify Webcam Images Using Deep LearninggauravNo ratings yet
- Machine Learning Unit 3Document40 pagesMachine Learning Unit 3read4freeNo ratings yet
- Unit3 2023 NNDLDocument69 pagesUnit3 2023 NNDLSONY P J 2248440No ratings yet
- Deep Learning: Seungsang OhDocument39 pagesDeep Learning: Seungsang OhKaAI KookminNo ratings yet
- Deep Learning Unit-IIIDocument9 pagesDeep Learning Unit-IIIAnonymous xMYE0TiNBcNo ratings yet
- DL Unit3Document8 pagesDL Unit3Anonymous xMYE0TiNBcNo ratings yet
- CC511 Week 7 - Deep - LearningDocument33 pagesCC511 Week 7 - Deep - Learningmohamed sherifNo ratings yet
- DL Unit 3 2019PATDocument66 pagesDL Unit 3 2019PATNilesh NagraleNo ratings yet
- Convolutional Neural Networks (CNN)Document7 pagesConvolutional Neural Networks (CNN)Towsif SalauddinNo ratings yet
- CNN Course-Notes 365Document29 pagesCNN Course-Notes 365aherfNo ratings yet
- Deep LearningUNIT-IVDocument16 pagesDeep LearningUNIT-IVnikhilsinha0099No ratings yet
- What Is Convolutional Neural NetworkDocument16 pagesWhat Is Convolutional Neural Networkahmedliet143No ratings yet
- Convolutional Neural NetworkDocument3 pagesConvolutional Neural NetworkShankul ShuklaNo ratings yet
- Deep Learning Image ClassificationDocument11 pagesDeep Learning Image ClassificationPRIYANKA TATANo ratings yet
- Module 3 - Convolutional Neural Networks: HistoryDocument3 pagesModule 3 - Convolutional Neural Networks: HistoryCyril Smart AmbedkarNo ratings yet
- 5 Layers of A Convolutional Neural NetworkDocument15 pages5 Layers of A Convolutional Neural Networknawazk8191No ratings yet
- Convolutional Neural NetworkDocument61 pagesConvolutional Neural NetworkAnkit MahapatraNo ratings yet
- Convolutional Neural NetworkDocument78 pagesConvolutional Neural NetworkAaqib InamNo ratings yet
- CS601 - Machine Learning - Unit 3 - Notes - 1672759761Document15 pagesCS601 - Machine Learning - Unit 3 - Notes - 1672759761mohit jaiswalNo ratings yet
- Deep Neural Network DNNDocument5 pagesDeep Neural Network DNNjaffar bikatNo ratings yet
- Convolutional Neural Networks-Part2Document21 pagesConvolutional Neural Networks-Part2polinati.vinesh2023No ratings yet
- Sommaire CNN PresentationDocument10 pagesSommaire CNN Presentationmario DjawouNo ratings yet
- Unit 3 - Machine LearningDocument16 pagesUnit 3 - Machine LearningGauri BansalNo ratings yet
- UNIT 2 Self NotesDocument10 pagesUNIT 2 Self NotesjainayushtechNo ratings yet
- Step by Step Procedure That How I Resolve Given Task PytorhDocument6 pagesStep by Step Procedure That How I Resolve Given Task PytorhAbhay Singh TanwarNo ratings yet
- 20 Questions To Test Your Skills On CNN Convolutional Neural NetworksDocument11 pages20 Questions To Test Your Skills On CNN Convolutional Neural NetworksKumkumo Kussia KossaNo ratings yet
- Unit 3 - Machine Learning - WWW - Rgpvnotes.inDocument29 pagesUnit 3 - Machine Learning - WWW - Rgpvnotes.inASHOKA KUMARNo ratings yet
- Artificial IntelligenceDocument11 pagesArtificial Intelligence2BL20CS022Anjana HiroliNo ratings yet
- Assignment #1: Afzal Ali (11282) Muhammad Hammad (11293) Muhammad Bilal (11291) Mehran Ahmed (11287) Date 20/03/2019Document7 pagesAssignment #1: Afzal Ali (11282) Muhammad Hammad (11293) Muhammad Bilal (11291) Mehran Ahmed (11287) Date 20/03/2019Muhammad BilalNo ratings yet
- Short Qns CNNDocument11 pagesShort Qns CNNSwathi KNo ratings yet
- Image Classification Using Convolutional Neural Networks (CNNS)Document61 pagesImage Classification Using Convolutional Neural Networks (CNNS)Golam Moktader DaiyanNo ratings yet
- Convolutional Neural Networks & ZapierDocument75 pagesConvolutional Neural Networks & ZapierTimer InsightNo ratings yet
- Week8 WEBDocument54 pagesWeek8 WEBAnkit ShawNo ratings yet
- CNN Model Introduction and OverviewDocument2 pagesCNN Model Introduction and OverviewHari hara Sudhan .MNo ratings yet
- CNN Part 1Document38 pagesCNN Part 1pragathisai0912No ratings yet
- CS 601 Machine Learning Unit 3Document37 pagesCS 601 Machine Learning Unit 3Priyanka BhateleNo ratings yet
- UNIT-4 Foundations of Deep LearningDocument43 pagesUNIT-4 Foundations of Deep Learningbhavana100% (1)
- UNIT 3 Self NotesDocument5 pagesUNIT 3 Self NotesjainayushtechNo ratings yet
- Deep Learning Approach For Object Detection Using CNN: AbstractDocument7 pagesDeep Learning Approach For Object Detection Using CNN: AbstractAYUSH MISHRANo ratings yet
- Zamir 2022 Mirnetv2Document15 pagesZamir 2022 Mirnetv2navya.cogni21No ratings yet
- Neural Networks Unit 3Document93 pagesNeural Networks Unit 3svkarthik83No ratings yet
- Convolutional Neural Network: by Gagandeep KaurDocument107 pagesConvolutional Neural Network: by Gagandeep Kaurjamiesonlara100% (1)
- DL Anonymous Question BankDocument22 pagesDL Anonymous Question BankAnuradha PiseNo ratings yet
- Appiled AIDocument9 pagesAppiled AIchude okeruluNo ratings yet
- Topic 3ii - Convolutional Neural NetworkDocument43 pagesTopic 3ii - Convolutional Neural NetworkNurkhairunnisa' AzhanNo ratings yet
- Convolution Neural NetworkDocument74 pagesConvolution Neural Networktoon townNo ratings yet
- Sample Term PaperDocument7 pagesSample Term PaperKabul Ka PathanNo ratings yet
- Unit 2 Convolutional Neural NetworkDocument16 pagesUnit 2 Convolutional Neural NetworkReasonNo ratings yet
- Facial Expression Recognition System Using Convolutional Neural NetworkDocument44 pagesFacial Expression Recognition System Using Convolutional Neural NetworkMugunthan R0% (1)
- An Overview of Popular Deep Learning Methods PDFDocument12 pagesAn Overview of Popular Deep Learning Methods PDFOussama El B'charriNo ratings yet
- Deep Learning Section5 (2023)Document17 pagesDeep Learning Section5 (2023)sama ghorabNo ratings yet
- Weather API ImplementationDocument3 pagesWeather API ImplementationSomnath BiswalNo ratings yet
- My First IdeasDocument2 pagesMy First IdeasSomnath BiswalNo ratings yet
- Experiment 05 (C)Document10 pagesExperiment 05 (C)Somnath BiswalNo ratings yet
- Experiment 05 (A)Document13 pagesExperiment 05 (A)Somnath BiswalNo ratings yet
- PLC Timer's Instruction Is Used To Activate or Deactivate A Device After A Preset Interval of Time. Types of Timers Available AreDocument11 pagesPLC Timer's Instruction Is Used To Activate or Deactivate A Device After A Preset Interval of Time. Types of Timers Available AreSomnath BiswalNo ratings yet
- Experiment 04Document14 pagesExperiment 04Somnath BiswalNo ratings yet
- Experiment 02Document6 pagesExperiment 02Somnath BiswalNo ratings yet
- Experiment 03: Consider The Following Unity Feedback SystemDocument20 pagesExperiment 03: Consider The Following Unity Feedback SystemSomnath BiswalNo ratings yet
- Experiment 02Document6 pagesExperiment 02Somnath BiswalNo ratings yet
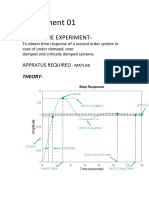
- Experiment 01: Aim of The ExperimentDocument11 pagesExperiment 01: Aim of The ExperimentSomnath BiswalNo ratings yet
- Experiment 01: Aim of The ExperimentDocument11 pagesExperiment 01: Aim of The ExperimentSomnath BiswalNo ratings yet
- Customer Behavior Analysis in E-Commerce Using Decision Tree Machine Learning ApproachDocument9 pagesCustomer Behavior Analysis in E-Commerce Using Decision Tree Machine Learning ApproachBryan PabloNo ratings yet
- Deep-Learning-Based Membranous Nephropathy Classification and Monte-Carlo Dropout Uncertainty EstimationDocument12 pagesDeep-Learning-Based Membranous Nephropathy Classification and Monte-Carlo Dropout Uncertainty EstimationExactus MetrologiaNo ratings yet
- Probability For Machine Learning SampleDocument26 pagesProbability For Machine Learning SampleKhang ĐinhNo ratings yet
- Patient AttendanceNo-Show PredictionDocument10 pagesPatient AttendanceNo-Show PredictionInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- PML Lec1 Slides PDFDocument111 pagesPML Lec1 Slides PDFkishan shuklaNo ratings yet
- Data ScienceDocument85 pagesData SciencesriharinecgNo ratings yet
- Journal Pre-Proofs: Chinese Journal of AeronauticsDocument26 pagesJournal Pre-Proofs: Chinese Journal of AeronauticsS. LAVANYANo ratings yet
- Data Mining in Cloud Computing SurveyDocument8 pagesData Mining in Cloud Computing Surveynathanael-miscNo ratings yet
- Internship Semianar 2k21Document21 pagesInternship Semianar 2k21prajwal c nNo ratings yet
- Groundwater PredictionDocument13 pagesGroundwater PredictionKaran RajNo ratings yet
- (Lawrence Hubert and Phipps Arabie) Comparing Partitions (1985)Document26 pages(Lawrence Hubert and Phipps Arabie) Comparing Partitions (1985)Zhiqiang XuNo ratings yet
- MCA SyllabusDocument76 pagesMCA SyllabusIsha SharmaNo ratings yet
- A Deep Learning Model For Identification of Diabetes Type 2 Based On Nucleotide SignalsDocument13 pagesA Deep Learning Model For Identification of Diabetes Type 2 Based On Nucleotide SignalsNanda Kishore M 23PHD0391No ratings yet
- Cheat Sheet: Building A KNIME Workflow For Beginners: Explore AnalyzeDocument2 pagesCheat Sheet: Building A KNIME Workflow For Beginners: Explore AnalyzeKate Pink100% (1)
- Predictive Analysis of Fluid-Hammer Effect On LNG Regasification System Pipeline NetworkDocument6 pagesPredictive Analysis of Fluid-Hammer Effect On LNG Regasification System Pipeline NetworkclaudyaneNo ratings yet
- Delta RuleDocument3 pagesDelta RulemomavNo ratings yet
- Predicting The Housing Price Direction Using Machine Learning TechniquesDocument3 pagesPredicting The Housing Price Direction Using Machine Learning TechniquesManuel LunaNo ratings yet
- Deep Super Learner: A Deep Ensemble For Classification ProblemsDocument12 pagesDeep Super Learner: A Deep Ensemble For Classification Problemsvishesh goyalNo ratings yet
- ML Manufacturing Auto Industry InfosysDocument28 pagesML Manufacturing Auto Industry InfosysBidyut Bhusan PandaNo ratings yet
- All SyllabusDocument6 pagesAll Syllabusfebin josephNo ratings yet
- Automation of Candidate Hiring System Using Machine LearningDocument6 pagesAutomation of Candidate Hiring System Using Machine LearningInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Dwit College Deerwalk Institute of Technology: Automatic Fruit Classification Using Adaboost AlgorithmDocument50 pagesDwit College Deerwalk Institute of Technology: Automatic Fruit Classification Using Adaboost AlgorithmYousef QuriedNo ratings yet
- Download full chapter Ml Net Revealed Simple Tools For Applying Machine Learning To Your Applications Sudipta Mukherjee pdf docxDocument53 pagesDownload full chapter Ml Net Revealed Simple Tools For Applying Machine Learning To Your Applications Sudipta Mukherjee pdf docxmary.glass134No ratings yet
- Confusion MatrixDocument6 pagesConfusion MatrixamirNo ratings yet
- Enhancing Milk Quality Detection With Machine Learning: A Comparative Analysis of KNN and Distance-Weighted KNN AlgorithmsDocument9 pagesEnhancing Milk Quality Detection With Machine Learning: A Comparative Analysis of KNN and Distance-Weighted KNN AlgorithmsInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Decision Tree AlgorithmDocument22 pagesDecision Tree Algorithmvani_V_prakashNo ratings yet
- Using Support Vector Machine For Classification and Feature Extraction of Spam in EmailDocument7 pagesUsing Support Vector Machine For Classification and Feature Extraction of Spam in Emailghazy almutiryNo ratings yet
- Identifikasi Kematangan Buah Tropika Berbasis Sistem Penciuman Elektronik Menggunakan Deret Sensor GAs Semikonduktor Dengan Metode Jaringan Syaraf TiruanDocument9 pagesIdentifikasi Kematangan Buah Tropika Berbasis Sistem Penciuman Elektronik Menggunakan Deret Sensor GAs Semikonduktor Dengan Metode Jaringan Syaraf TiruanPutri Wahyulian ANo ratings yet